Ano ang gawa sa DNA. Nucleotide - ano ito? Komposisyon, istraktura, bilang at pagkakasunud-sunod ng mga nucleotide sa DNA chain Ang DNA double helix ay pinatatag ng mga ions
Ang mga nucleic acid ay mga macromolecular substance na binubuo ng mononucleotides, na konektado sa isa't isa sa isang polymer chain gamit ang 3",5" - phosphodiester bond at nakaimpake sa mga cell sa isang tiyak na paraan.
Ang mga nucleic acid ay mga biopolymer ng dalawang uri: ribonucleic acid (RNA) at deoxyribonucleic acid (DNA). Ang bawat biopolymer ay binubuo ng mga nucleotide na naiiba sa nalalabi sa carbohydrate (ribose, deoxyribose) at isa sa mga nitrogenous na base (uracil, thymine). Alinsunod dito, nakuha ng mga nucleic acid ang kanilang pangalan.
Istraktura ng deoxyribonucleic acid
Ang mga nucleic acid ay may pangunahin, pangalawa at tersiyaryong istruktura.
Pangunahing istraktura ng DNA
Ang pangunahing istraktura ng DNA ay isang linear polynucleotide chain kung saan ang mga mononucleotides ay konektado ng 3", 5" phosphodiester bond. Ang panimulang materyal para sa pag-assemble ng isang nucleic acid chain sa isang cell ay ang nucleoside 5'-triphosphate, na, bilang resulta ng pag-alis ng β at γ residues ng phosphoric acid, ay nakakabit sa 3'-carbon atom ng isa pang nucleoside . Kaya, ang 3" carbon atom ng isang deoxyribose covalently binds sa 5" carbon atom ng isa pang deoxyribose sa pamamagitan ng isang solong phosphoric acid residue at bumubuo ng linear polynucleotide chain ng nucleic acid. Kaya ang pangalan: 3", 5"-phosphodiester bonds. Ang mga nitrogenous base ay hindi nakikibahagi sa koneksyon ng mga nucleotide ng isang chain (Larawan 1.).
Ang ganitong koneksyon, sa pagitan ng phosphoric acid residue ng isang nucleotide at ang carbohydrate ng isa, ay humahantong sa pagbuo ng isang pentose-phosphate backbone ng polynucleotide molecule, kung saan ang mga nitrogenous base ay idinagdag nang isa-isa mula sa gilid. Ang kanilang pagkakasunud-sunod sa mga kadena ng mga molekula ng nucleic acid ay mahigpit na tiyak para sa mga selula ng iba't ibang mga organismo, i.e. ay may tiyak na karakter (pangunahing Chargaff).
Ang isang linear na chain ng DNA, ang haba nito ay depende sa bilang ng mga nucleotide na kasama sa chain, ay may dalawang dulo: ang isa ay tinatawag na 3 "end at naglalaman ng isang libreng hydroxyl, at ang isa, ang 5" na dulo, ay naglalaman ng phosphoric acid nalalabi. Ang circuit ay polar at maaaring 5"->3" at 3"->5". Ang isang pagbubukod ay ang pabilog na DNA.
Ang genetic na "text" ng DNA ay binubuo ng code na "mga salita" - triplets ng mga nucleotide na tinatawag na codon. Ang mga segment ng DNA na naglalaman ng impormasyon tungkol sa pangunahing istruktura ng lahat ng uri ng RNA ay tinatawag na mga istrukturang gene.
Ang mga polynucleoditic DNA chain ay umaabot sa napakalaking sukat, kaya sila ay nakaimpake sa isang tiyak na paraan sa cell.
Sa pag-aaral ng komposisyon ng DNA, itinatag ni Chargaff (1949) ang mahahalagang regularidad tungkol sa nilalaman ng mga indibidwal na base ng DNA. Sila ay tumulong sa pagtuklas ng pangalawang istraktura ng DNA. Ang mga pattern na ito ay tinatawag na mga panuntunan ng Chargaff. Mga panuntunan ng Chargaff
Sinasabi ng mga patakarang ito na kapag nagtatayo ng DNA, ang isang medyo mahigpit na pagsusulatan (pagpapares) ay dapat na sundin hindi para sa mga base ng purine at pyrimidine sa pangkalahatan, ngunit partikular para sa thymine na may adenine at cytosine na may guanine. Batay sa mga patakarang ito, bukod sa iba pang mga bagay, noong 1953, iminungkahi nina Watson at Crick ang isang modelo ng pangalawang istraktura ng DNA, na tinatawag na double helix (Fig.). |

Pangalawang istraktura ng DNA
Ang pangalawang istraktura ng DNA ay isang double helix, na ang modelo ay iminungkahi nina D. Watson at F. Crick noong 1953.
Mga kinakailangan para sa paglikha ng isang modelo ng DNA
Bilang resulta ng mga paunang pagsusuri, ang ideya ay ang DNA ng anumang pinagmulan ay naglalaman ng lahat ng apat na nucleotides sa pantay na halaga ng molar. Gayunpaman, noong 1940s, si E. Chargaff at ang kanyang mga kasamahan, bilang isang resulta ng pagsusuri ng DNA na nakahiwalay sa iba't ibang mga organismo, ay malinaw na nagpakita na ang mga nitrogenous base ay nakapaloob sa kanila sa iba't ibang mga ratio ng dami. Nalaman ni Chargaff na, kahit na ang mga ratio na ito ay pareho para sa DNA mula sa lahat ng mga cell ng parehong species ng mga organismo, ang DNA mula sa iba't ibang mga species ay maaaring mag-iba nang malaki sa nilalaman ng ilang mga nucleotide. Iminungkahi nito na ang mga pagkakaiba sa ratio ng mga nitrogenous na base ay maaaring nauugnay sa ilang biological code. Kahit na ang ratio ng mga indibidwal na purine at pyrimidine base sa iba't ibang mga sample ng DNA ay hindi pareho, kapag inihambing ang mga resulta ng mga pagsusuri, isang tiyak na pattern ang ipinahayag: sa lahat ng mga sample, ang kabuuang halaga ng purines ay katumbas ng kabuuang halaga ng mga pyrimidines ( A + G = T + C), ang halaga ng adenine ay katumbas ng halaga ng thymine (A = T), at ang halaga ng guanine - ang halaga ng cytosine (G = C). Ang DNA na nakahiwalay sa mga selula ng mammalian ay karaniwang mas mayaman sa adenine at thymine at medyo mahirap sa guanine at cytosine, habang ang DNA mula sa bakterya ay mas mayaman sa guanine at cytosine at medyo mahirap sa adenine at thymine. Ang mga datos na ito ay bumubuo ng isang mahalagang bahagi ng makatotohanang materyal, sa batayan kung saan ang modelo ng istruktura ng Watson-Crick DNA ay itinayo kalaunan.
Ang isa pang mahalagang hindi direktang indikasyon ng posibleng istraktura ng DNA ay ang data ni L. Pauling sa istruktura ng mga molekula ng protina. Ipinakita ni Pauling na maraming iba't ibang mga matatag na pagsasaayos ng chain ng amino acid ay posible sa isang molekula ng protina. Ang isa sa mga karaniwang configuration ng peptide chain - α-helix - ay isang regular na helical na istraktura. Sa gayong istraktura, posible ang pagbuo ng mga bono ng hydrogen sa pagitan ng mga amino acid na matatagpuan sa mga katabing pagliko ng kadena. Inilarawan ni Pauling ang α-helical na pagsasaayos ng polypeptide chain noong 1950 at iminungkahi na ang mga molekula ng DNA ay malamang na may helical na istraktura na naayos ng mga bono ng hydrogen.
Gayunpaman, ang pinakamahalagang impormasyon tungkol sa istraktura ng molekula ng DNA ay ibinigay ng mga resulta ng pagsusuri ng X-ray diffraction. Ang mga X-ray, na dumadaan sa isang kristal ng DNA, ay sumasailalim sa diffraction, iyon ay, sila ay pinalihis sa ilang mga direksyon. Ang antas at likas na katangian ng pagpapalihis ng mga sinag ay nakasalalay sa istraktura ng mga molekula mismo. Ang pattern ng X-ray diffraction (Larawan 3) ay nagbibigay sa may karanasang mata ng ilang di-tuwirang mga indikasyon patungkol sa istruktura ng mga molecule ng substance na pinag-aaralan. Ang pagsusuri sa mga pattern ng diffraction ng X-ray ng DNA ay humantong sa konklusyon na ang mga nitrogenous base (na may patag na hugis) ay nakasalansan tulad ng isang stack ng mga plato. Ginawang posible ng mga pattern ng X-ray na makilala ang tatlong pangunahing mga panahon sa istruktura ng crystalline na DNA: 0.34, 2, at 3.4 nm.

Watson-Crick DNA Model
Simula sa analytical data ni Chargaff, mga x-ray ni Wilkins, at pananaliksik ng chemist, na nagbigay ng impormasyon tungkol sa eksaktong mga distansya sa pagitan ng mga atomo sa isang molekula, tungkol sa mga anggulo sa pagitan ng mga bono ng isang partikular na atom, at tungkol sa laki ng mga atomo, Watson at Crick nagsimulang bumuo ng mga pisikal na modelo ng mga indibidwal na bahagi ng molekula ng DNA sa isang tiyak na sukat. at "i-adjust" ang mga ito sa isa't isa sa paraang ang resultang sistema ay tumutugma sa iba't ibang pang-eksperimentong data [ipakita] .
Kahit na mas maaga, alam na ang mga katabing nucleotide sa isang DNA chain ay konektado sa pamamagitan ng phosphodiester bridges na nag-uugnay sa 5'-carbon atom ng deoxyribose ng isang nucleotide sa 3'-carbon atom ng deoxyribose ng susunod na nucleotide. Sina Watson at Crick ay walang alinlangan na ang isang panahon na 0.34 nm ay tumutugma sa distansya sa pagitan ng sunud-sunod na mga nucleotide sa isang DNA strand. Dagdag pa, maaaring ipagpalagay na ang panahon ng 2 nm ay tumutugma sa kapal ng kadena. At upang maipaliwanag kung anong tunay na istraktura ang katumbas ng panahon ng 3.4 nm, sina Watson at Crick, pati na rin si Pauling kanina, ay ipinapalagay na ang kadena ay baluktot sa anyo ng isang spiral (o, mas tiyak, ay bumubuo ng isang helix, dahil ang spiral sa mahigpit na kahulugan nito ang salita ay nakukuha kapag ang mga pagliko ay bumubuo ng isang korteng kono sa halip na isang cylindrical na ibabaw sa kalawakan). Pagkatapos ang panahon ng 3.4 nm ay tumutugma sa distansya sa pagitan ng sunud-sunod na pagliko ng spiral na ito. Ang ganitong spiral ay maaaring maging napaka-siksik o medyo nakaunat, ibig sabihin, ang mga pagliko nito ay maaaring patag o matarik. Dahil ang panahon ng 3.4 nm ay eksaktong 10 beses ang distansya sa pagitan ng magkakasunod na nucleotides (0.34 nm), malinaw na ang bawat kumpletong pagliko ng helix ay naglalaman ng 10 nucleotides. Mula sa mga datos na ito, kinakalkula nina Watson at Crick ang density ng isang polynucleotide chain na napilipit sa isang helix na may diameter na 2 nm, na may distansya sa pagitan ng mga pagliko na katumbas ng 3.4 nm. Ito ay lumabas na ang naturang strand ay magkakaroon ng density ng kalahati ng aktwal na density ng DNA, na kilala na. Kinailangan kong ipagpalagay na ang molekula ng DNA ay binubuo ng dalawang kadena - na ito ay isang double helix ng mga nucleotides.
Ang susunod na gawain ay, siyempre, upang ipaliwanag ang spatial na relasyon sa pagitan ng dalawang strands na bumubuo ng double helix. Ang pagkakaroon ng pagsubok ng ilang mga strand arrangement sa kanilang pisikal na modelo, nalaman nina Watson at Crick na ang pinakamahusay na akma para sa lahat ng magagamit na data ay isa kung saan ang dalawang polynucleotide helice ay tumatakbo sa magkasalungat na direksyon; sa kasong ito, ang mga kadena na binubuo ng mga residu ng asukal at pospeyt ay bumubuo sa ibabaw ng isang double helix, at ang mga purine at pyrimidine ay matatagpuan sa loob. Ang mga base na matatagpuan sa tapat ng bawat isa, na kabilang sa dalawang chain, ay konektado sa mga pares sa pamamagitan ng hydrogen bond; Ang mga hydrogen bond na ito ang humahawak sa mga kadena nang magkasama, kaya inaayos ang pangkalahatang pagsasaayos ng molekula.
Ang DNA double helix ay maaaring isipin bilang isang helical rope ladder, na ang mga baitang ay nananatiling pahalang. Pagkatapos, ang dalawang longitudinal na mga lubid ay tumutugma sa mga kadena ng mga nalalabi ng asukal at pospeyt, at ang mga crossbar ay tumutugma sa mga pares ng mga nitrogenous na base na konektado ng mga bono ng hydrogen.
Bilang resulta ng karagdagang pag-aaral ng mga posibleng modelo, sina Watson at Crick ay dumating sa konklusyon na ang bawat "crossbar" ay dapat na binubuo ng isang purine at isang pyrimidine; sa isang panahon na 2 nm (naaayon sa diameter ng double helix), hindi magkakaroon ng sapat na puwang para sa dalawang purine, at ang dalawang pyrimidine ay hindi maaaring magkalapit nang magkadikit upang makabuo ng wastong mga bono ng hydrogen. Ang isang malalim na pag-aaral ng detalyadong modelo ay nagpakita na ang adenine at cytosine, na bumubuo ng isang kumbinasyon ng tamang sukat, ay hindi pa rin matatagpuan sa paraang nabuo ang mga bono ng hydrogen sa pagitan nila. Ang mga katulad na ulat ay pinilit din ang kumbinasyon ng guanine-thymine na hindi kasama, habang ang mga kumbinasyong adenine-thymine at guanine-cytosine ay natagpuan na lubos na katanggap-tanggap. Ang likas na katangian ng mga bono ng hydrogen ay tulad na ang adenine ay nagpapares sa thymine, at ang guanine ay nagpapares sa cytosine. Ang konsepto ng partikular na base pairing ay naging posible na ipaliwanag ang "Chargaff rule", ayon sa kung saan sa anumang molekula ng DNA ang halaga ng adenine ay palaging katumbas ng nilalaman ng thymine, at ang halaga ng guanine ay palaging katumbas ng halaga ng cytosine . Dalawang hydrogen bond ang nabuo sa pagitan ng adenine at thymine, at tatlo sa pagitan ng guanine at cytosine. Dahil sa pagtitiyak na ito sa pagbuo ng mga bono ng hydrogen laban sa bawat adenine sa isang kadena, ang thymine ay nasa kabilang; sa parehong paraan, ang cytosine lamang ang maaaring ilagay laban sa bawat guanine. Kaya, ang mga kadena ay pantulong sa isa't isa, iyon ay, ang pagkakasunud-sunod ng mga nucleotide sa isang kadena ay natatanging tinutukoy ang kanilang pagkakasunud-sunod sa isa pa. Ang dalawang chain ay tumatakbo sa magkasalungat na direksyon at ang kanilang mga phosphate end group ay nasa magkabilang dulo ng double helix.
Bilang resulta ng kanilang pananaliksik, noong 1953 si Watson at Crick ay nagmungkahi ng isang modelo para sa istruktura ng molekula ng DNA (Larawan 3), na nananatiling may kaugnayan sa kasalukuyan. Ayon sa modelo, ang isang molekula ng DNA ay binubuo ng dalawang komplementaryong polynucleotide chain. Ang bawat DNA strand ay isang polynucleotide na binubuo ng ilang sampu-sampung libong nucleotides. Sa loob nito, ang mga kalapit na nucleotides ay bumubuo ng isang regular na pentose-phosphate backbone dahil sa kumbinasyon ng isang phosphoric acid residue at deoxyribose sa pamamagitan ng isang malakas na covalent bond. Ang mga nitrogenous base ng isang polynucleotide chain ay nakaayos sa isang mahigpit na tinukoy na pagkakasunud-sunod laban sa nitrogenous base ng isa pa. Ang paghahalili ng mga nitrogenous na base sa polynucleotide chain ay hindi regular.
Ang pag-aayos ng mga nitrogenous base sa DNA chain ay pantulong (mula sa Griyego na "complement" - karagdagan), i.e. laban sa adenine (A) ay palaging thymine (T), at laban sa guanine (G) - tanging cytosine (C). Ito ay ipinaliwanag sa pamamagitan ng katotohanan na ang A at T, pati na rin ang G at C, ay mahigpit na tumutugma sa bawat isa, i.e. umakma sa isa't isa. Ang sulat na ito ay ibinibigay ng kemikal na istraktura ng mga base, na nagpapahintulot sa pagbuo ng mga bono ng hydrogen sa isang pares ng purine at pyrimidine. Sa pagitan ng A at T mayroong dalawang mga bono, sa pagitan ng G at C - tatlo. Ang mga bono na ito ay nagbibigay ng bahagyang pagpapapanatag ng molekula ng DNA sa kalawakan. Ang katatagan ng double helix ay direktang proporsyonal sa bilang ng G≡C bond, na mas matatag kaysa sa A=T bond.
Ang kilalang pagkakasunud-sunod ng mga nucleotide sa isang strand ng DNA ay ginagawang posible, sa pamamagitan ng prinsipyo ng complementarity, upang maitatag ang mga nucleotide ng isa pang strand.
Bilang karagdagan, ito ay itinatag na ang mga nitrogenous na base na may isang mabangong istraktura ay matatagpuan sa itaas ng isa sa isang may tubig na solusyon, na bumubuo, bilang ito ay, isang stack ng mga barya. Ang prosesong ito ng pagbuo ng mga stack ng mga organikong molekula tinatawag na stacking. Ang mga polynucleotide chain ng DNA molecule ng Watson-Crick model na isinasaalang-alang ay may katulad na physicochemical state, ang kanilang mga nitrogenous na base ay nakaayos sa anyo ng isang stack ng mga barya, sa pagitan ng mga eroplano kung saan nangyayari ang mga interaksyon ng van der Waals (stacking interaction).
Ang mga hydrogen bond sa pagitan ng mga komplementaryong base (pahalang) at stacking na interaksyon sa pagitan ng mga base plane sa isang polynucleotide chain dahil sa mga puwersa ng van der Waals (patayo) ay nagbibigay sa molekula ng DNA ng karagdagang stabilization sa espasyo.
Ang mga backbone ng asukal-pospeyt ng parehong mga kadena ay nakabukas palabas, at ang mga base ay nasa loob, patungo sa isa't isa. Ang direksyon ng mga strand sa DNA ay antiparallel (isa sa kanila ay may direksyon na 5"->3", ang isa pa - 3"->5", ibig sabihin, ang 3"-end ng isang strand ay matatagpuan sa tapat ng 5"-end ng iba.). Ang mga chain ay bumubuo ng mga right helix na may isang karaniwang axis. Ang isang pagliko ng helix ay 10 nucleotides, ang laki ng pagliko ay 3.4 nm, ang taas ng bawat nucleotide ay 0.34 nm, ang diameter ng helix ay 2.0 nm. Bilang resulta ng pag-ikot ng isang strand sa paligid ng isa, isang major groove (mga 20 Å ang diameter) at isang minor groove (mga 12 Å) ay nabuo sa DNA double helix. Ang form na ito ng Watson-Crick double helix ay tinawag na B-form. Sa mga cell, ang DNA ay karaniwang umiiral sa B form, na kung saan ay ang pinaka-matatag.
Mga Pag-andar ng DNA
Ipinaliwanag ng iminungkahing modelo ang marami sa mga biological na katangian ng deoxyribonucleic acid, kabilang ang pag-iimbak ng genetic na impormasyon at ang pagkakaiba-iba ng mga gene, na ibinigay ng isang malawak na iba't ibang magkakasunod na kumbinasyon ng 4 na nucleotides at ang katotohanan ng pagkakaroon ng isang genetic code, ang kakayahang self-reproduce at magpadala ng genetic na impormasyon, na ibinigay ng proseso ng pagtitiklop, at ang pagpapatupad ng genetic na impormasyon sa anyo ng mga protina, pati na rin ang anumang iba pang mga compound na nabuo sa tulong ng mga protina ng enzyme.
Mga pangunahing pag-andar ng DNA.
- Ang DNA ay ang carrier ng genetic na impormasyon, na sinisiguro ng katotohanan ng pagkakaroon ng genetic code.
- Pagpaparami at ipinadalang genetic na impormasyon sa mga henerasyon ng mga selula at organismo. Ang function na ito ay ibinibigay ng proseso ng pagtitiklop.
- Pagpapatupad ng genetic na impormasyon sa anyo ng mga protina, pati na rin ang anumang iba pang mga compound na nabuo sa tulong ng mga protina ng enzyme. Ang function na ito ay ibinibigay ng mga proseso ng transkripsyon at pagsasalin.

Mga anyo ng organisasyon ng double-stranded DNA
Ang DNA ay maaaring bumuo ng ilang uri ng double helixes (Fig. 4). Sa kasalukuyan, alam na ang anim na anyo (mula A hanggang E at Z-form).
Ang mga istrukturang anyo ng DNA, na itinatag ni Rosalind Franklin, ay nakasalalay sa saturation ng molekula ng nucleic acid sa tubig. Sa mga pag-aaral ng mga hibla ng DNA gamit ang pagsusuri ng X-ray diffraction, ipinakita na ang pattern ng X-ray diffraction ay radikal na nakasalalay sa kung anong kamag-anak na kahalumigmigan, sa kung anong antas ng saturation ng tubig ng hibla na ito, ang eksperimento ay nagaganap. Kung ang hibla ay sapat na puspos ng tubig, pagkatapos ay isang radiograph ang nakuha. Kapag natuyo, lumitaw ang isang ganap na kakaibang pattern ng X-ray, ibang-iba sa pattern ng X-ray ng isang high-moisture fiber.
Ang molekula ng mataas na kahalumigmigan na DNA ay tinatawag na B-shape. Sa ilalim ng mga kondisyong pisyolohikal (mababang konsentrasyon ng asin, mataas na antas ng hydration), ang nangingibabaw na uri ng istruktura ng DNA ay ang B-form (ang pangunahing anyo ng double-stranded na DNA ay ang Watson-Crick model). Ang helix pitch ng naturang molekula ay 3.4 nm. Mayroong 10 komplementaryong pares bawat pagliko sa anyo ng mga baluktot na stack ng "mga barya" - mga nitrogenous na base. Ang mga stack ay pinagsasama-sama ng hydrogen bond sa pagitan ng dalawang magkasalungat na "coin" ng mga stack, at ito ay "coiled" na may dalawang ribbons ng phosphodiester backbone na pinaikot sa isang right-handed helix. Ang mga eroplano ng nitrogenous base ay patayo sa axis ng helix. Ang magkalapit na magkatugmang pares ay iniikot nang may kaugnayan sa isa't isa ng 36°. Ang diameter ng helix ay 20Å, kasama ang purine nucleotide na sumasakop sa 12Å at ang pyrimidine nucleotide ay sumasakop sa 8Å.
Ang molekula ng DNA ng mas mababang kahalumigmigan ay tinatawag na A-form. Ang A-form ay nabuo sa ilalim ng mga kondisyon ng hindi gaanong mataas na hydration at sa mas mataas na nilalaman ng Na + o K + ions. Ang mas malawak na right-handed conformation na ito ay may 11 base pairs bawat turn. Ang mga eroplano ng nitrogenous base ay may mas malakas na pagkahilig sa axis ng helix, lumihis sila mula sa normal hanggang sa axis ng helix ng 20 °. Ito ay nagpapahiwatig ng pagkakaroon ng isang panloob na void na may diameter na 5 Å. Ang distansya sa pagitan ng mga katabing nucleotides ay 0.23 nm, ang haba ng coil ay 2.5 nm, at ang diameter ng helix ay 2.3 nm.
Sa una, ang A-form ng DNA ay naisip na hindi gaanong mahalaga. Gayunpaman, nang maglaon ay lumabas na ang A-form ng DNA, pati na rin ang B-form, ay may malaking biological na kahalagahan. Ang RNA-DNA helix sa template-seed complex, pati na rin ang RNA-RNA helix at RNA hairpin structures ay may A-form (ang 2'-hydroxyl group ng ribose ay hindi nagpapahintulot sa RNA molecules na bumuo ng B-form) . Ang A-form ng DNA ay matatagpuan sa spores. Ito ay itinatag na ang A-form ng DNA ay 10 beses na mas lumalaban sa UV rays kaysa sa B-form.
A-form at B-form ay tinatawag mga kanonikal na anyo DNA.
Mga Form C-E din sa kanang kamay, ang kanilang pagbuo ay maaari lamang maobserbahan sa mga espesyal na eksperimento, at, tila, hindi sila umiiral sa vivo. Ang C-form ng DNA ay may istraktura na katulad ng B-DNA. Ang bilang ng mga pares ng base bawat pagliko ay 9.33, at ang haba ng helix ay 3.1 nm. Ang mga pares ng base ay nakakiling sa isang anggulo ng 8 degrees na may kaugnayan sa patayo na posisyon sa axis. Ang mga grooves ay malapit sa laki sa mga grooves ng B-DNA. Sa kasong ito, ang pangunahing uka ay medyo mas maliit, at ang menor de edad na uka ay mas malalim. Ang natural at sintetikong DNA polynucleotides ay maaaring pumasa sa C-form.
| Talahanayan 1. Mga katangian ng ilang uri ng istruktura ng DNA | |||
| Uri ng spiral | A | B | Z |
| Spiral pitch | 0.32 nm | 3.38 nm | 4.46 nm |
| Spiral twist | Tama | Tama | Kaliwa |
| Bilang ng mga pares ng base bawat pagliko | 11 | 10 | 12 |
| Distansya sa pagitan ng base planes | 0.256 nm | 0.338 nm | 0.371 nm |
| Glycosidic bond conformation | anti | anti | anti-C syn-G |
| Conformation ng singsing ng Furanose | C3 "-endo | C2 "-endo | C3 "-endo-G C2 "-endo-C |
| Lapad ng uka, maliit/malaki | 1.11/0.22 nm | 0.57/1.17 nm | 0.2/0.88 nm |
| Lalim ng uka, maliit/malaki | 0.26/1.30 nm | 0.82/0.85 nm | 1.38/0.37 nm |
| spiral diameter | 2.3 nm | 2.0 nm | 1.8 nm |
Mga elemento ng istruktura ng DNA
(mga di-canonical na istruktura ng DNA)
Kasama sa mga istrukturang elemento ng DNA ang mga hindi pangkaraniwang istruktura na limitado ng ilang espesyal na pagkakasunud-sunod:
|

Z-form ng DNA ay natuklasan noong 1979 habang pinag-aaralan ang hexanucleotide d(CG)3 - . Binuksan ito ng propesor ng MIT na si Alexander Rich at ng kanyang mga tauhan. Ang Z-form ay naging isa sa pinakamahalagang elemento ng istruktura ng DNA dahil sa ang katunayan na ang pagbuo nito ay naobserbahan sa mga rehiyon ng DNA kung saan ang mga purine ay kahalili ng mga pyrimidines (halimbawa, 5'-HCHCHC-3'), o sa mga umuulit na 5' -CHCHCH-3' na naglalaman ng methylated cytosine. Ang isang mahalagang kondisyon para sa pagbuo at pagpapapanatag ng Z-DNA ay ang pagkakaroon nito ng purine nucleotides sa syn-conformation, na kahalili ng mga base ng pyrimidine sa anti-conformation.
Ang mga natural na molekula ng DNA ay kadalasang umiiral sa tamang B form maliban kung naglalaman ang mga ito ng mga sequence tulad ng (CG)n. Gayunpaman, kung ang mga naturang pagkakasunud-sunod ay bahagi ng DNA, kung gayon ang mga rehiyong ito, kapag ang lakas ng ionic ng solusyon o mga kasyon na nag-neutralize sa negatibong singil sa backbone ng phosphodiester, ay maaaring magbago sa Z-form, habang ang iba pang mga rehiyon ng DNA sa chain ay nananatili. sa klasikal na B-form. Ang posibilidad ng naturang paglipat ay nagpapahiwatig na ang dalawang strand sa DNA double helix ay nasa isang dynamic na estado at maaaring mag-unwind na may kaugnayan sa isa't isa, na dumadaan mula sa kanang anyo patungo sa kaliwa at kabaliktaran. Ang mga biological na kahihinatnan ng lability na ito, na nagpapahintulot sa mga pagbabagong-anyo ng istruktura ng DNA, ay hindi pa ganap na nauunawaan. Ito ay pinaniniwalaan na ang mga rehiyon ng Z-DNA ay may papel sa regulasyon ng pagpapahayag ng ilang mga gene at nakikibahagi sa genetic recombination.
Ang Z-form ng DNA ay isang kaliwang kamay na double helix, kung saan ang phosphodiester backbone ay zigzag sa kahabaan ng axis ng molekula. Kaya ang pangalan ng molekula (zigzag)-DNA. Ang Z-DNA ay ang pinakamaliit na baluktot (12 base pairs bawat pagliko) at pinakapayat na kilala sa kalikasan. Ang distansya sa pagitan ng mga katabing nucleotides ay 0.38 nm, ang haba ng coil ay 4.56 nm, at ang diameter ng Z-DNA ay 1.8 nm. Bukod dito, hitsura Ang molekula ng DNA na ito ay nakikilala sa pamamagitan ng pagkakaroon ng isang solong uka.
Ang Z-form ng DNA ay natagpuan sa prokaryotic at eukaryotic cells. Sa ngayon, ang mga antibodies ay nakuha na maaaring makilala sa pagitan ng Z-form at B-form ng DNA. Ang mga antibodies na ito ay nagbubuklod sa mga partikular na rehiyon ng mga higanteng chromosome ng Drosophila (Dr. melanogaster) salivary gland cells. Ang nagbubuklod na reaksyon ay madaling sundin dahil sa hindi pangkaraniwang istraktura ng mga chromosome na ito, kung saan ang mas siksik na mga rehiyon (disks) ay kaibahan sa hindi gaanong siksik na mga rehiyon (interdisks). Ang mga rehiyon ng Z-DNA ay matatagpuan sa mga interdisc. Ito ay sumusunod mula dito na ang Z-form ay aktwal na umiiral sa natural na mga kondisyon, bagaman ang mga sukat ng mga indibidwal na seksyon ng Z-form ay hindi pa alam.

(shifters) - ang pinakasikat at madalas na nangyayari na mga base sequence sa DNA. Ang palindrome ay isang salita o parirala na bumabasa mula kaliwa hanggang kanan at vice versa sa parehong paraan. Ang mga halimbawa ng naturang mga salita o parirala ay: KUBO, COSSACK, BAHA, AT ISANG ROSE NA NAHULOG SA PAWS NI AZOR. Kapag inilapat sa mga seksyon ng DNA, ang terminong ito (palindrome) ay nangangahulugang ang parehong paghahalili ng mga nucleotide sa kahabaan ng kadena mula kanan pakaliwa at mula kaliwa hanggang kanan (tulad ng mga titik sa salitang "kubo", atbp.).
Ang palindrome ay nailalarawan sa pamamagitan ng pagkakaroon ng mga baligtad na pag-uulit ng mga base sequence na mayroong pangalawang-order na simetrya na may kinalaman sa dalawang hibla ng DNA. Ang ganitong mga pagkakasunud-sunod, para sa malinaw na mga kadahilanan, ay pantulong sa sarili at may posibilidad na bumuo ng hairpin o cruciform na mga istruktura (Fig.). Nakakatulong ang mga hairpins sa mga regulatory protein na makilala ang lugar kung saan kinopya ang genetic text ng chromosome DNA.
Sa mga kaso kung saan ang isang baligtad na pag-uulit ay naroroon sa parehong DNA strand, ang naturang pagkakasunod-sunod ay tinatawag na mirror repeat. Ang pag-uulit ng salamin ay walang mga katangiang pansariling pantulong at samakatuwid ay hindi kayang bumuo ng mga istruktura ng hairpin o cruciform. Ang mga pagkakasunud-sunod ng ganitong uri ay matatagpuan sa halos lahat ng malalaking molekula ng DNA at maaaring mula sa ilang pares ng base hanggang sa ilang libong pares ng base.
Ang pagkakaroon ng mga palindrome sa anyo ng mga istrukturang cruciform sa mga selulang eukaryotic ay hindi pa napatunayan, bagama't ang isang bilang ng mga istrukturang cruciform ay natagpuan sa vivo sa mga selulang E. coli. Ang pagkakaroon ng mga self-complementary na pagkakasunud-sunod sa RNA o single-stranded DNA ay ang pangunahing dahilan para sa pagtiklop ng nucleic chain sa mga solusyon sa isang tiyak na spatial na istraktura, na kung saan ay nailalarawan sa pamamagitan ng pagbuo ng maraming "mga hairpins".

H-form ng DNA- ito ay isang helix na nabuo ng tatlong hibla ng DNA - ang triple helix ng DNA. Ito ay isang complex ng Watson-Crick double helix na may pangatlong single-stranded na DNA strand, na umaangkop sa malaking uka nito, sa pagbuo ng tinatawag na Hoogsteen pair.
Ang pagbuo ng tulad ng isang triplex ay nangyayari bilang isang resulta ng pagdaragdag ng DNA double helix sa paraan na ang kalahati ng seksyon nito ay nananatili sa anyo ng isang double helix, at ang pangalawang kalahati ay naka-disconnect. Sa kasong ito, ang isa sa mga naka-disconnect na spiral ay bumubuo ng isang bagong istraktura na may unang kalahati ng double helix - isang triple helix, at ang pangalawa ay lumalabas na hindi nakabalangkas, sa anyo ng isang solong-filament na seksyon. Ang isang tampok ng paglipat ng istruktura na ito ay isang matalim na pag-asa sa pH ng daluyan, ang mga proton na nagpapatatag sa bagong istraktura. Dahil sa tampok na ito, ang bagong istraktura ay tinawag na H-form ng DNA, ang pagbuo nito ay natagpuan sa mga supercoiled plasmids na naglalaman ng mga rehiyon ng homopurine-homopyrimidine, na isang mirror repeat.
Sa karagdagang pag-aaral, ang posibilidad ng structural transition ng ilang homopurine-homopyrimidine double-stranded polynucleotides ay itinatag sa pagbuo ng isang three-stranded na istraktura na naglalaman ng:
- isang homopurine at dalawang homopyrimidine strands ( Py-Pu-Py triplex) [pakikipag-ugnayan sa Hoogsteen].
Ang mga constituent block ng Py-Pu-Py triplex ay canonical isomorphic CGC+ at TAT triads. Ang pagpapatatag ng triplex ay nangangailangan ng protonation ng CGC+ triad, kaya ang mga triplex na ito ay nakasalalay sa pH ng solusyon.
- isang homopyrimidine at dalawang homopurine strands ( Py-Pu-Pu triplex) [kabaligtaran na pakikipag-ugnayan ng Hoogsteen].
Ang mga constituent block ng Py-Pu-Pu triplex ay ang canonical isomorphic CGG at TAA triads. Ang isang mahalagang pag-aari ng Py-Pu-Pu triplexes ay ang pagtitiwala sa kanilang katatagan sa pagkakaroon ng mga dobleng sisingilin na mga ion, at iba't ibang mga ion ang kailangan upang patatagin ang mga triplex ng iba't ibang pagkakasunud-sunod. Dahil ang pagbuo ng Py-Pu-Pu triplexes ay hindi nangangailangan ng protonation ng kanilang constituent nucleotides, ang naturang triplexes ay maaaring umiral sa neutral pH.
Tandaan: ang direkta at baligtad na pakikipag-ugnayan ng Hoogsteen ay ipinaliwanag ng simetrya ng 1-methylthymine: ang isang 180 ° na pag-ikot ay humahantong sa katotohanan na ang lugar ng O4 atom ay inookupahan ng O2 atom, habang ang sistema ng mga bono ng hydrogen ay napanatili.
Mayroong dalawang uri ng triple helix:
- parallel triple helix kung saan ang polarity ng ikatlong strand ay kapareho ng sa homopurine chain ng Watson-Crick duplex
- antiparallel triple helix, kung saan ang mga polaridad ng ikatlo at homopurine chain ay magkasalungat.

G-quadruplex- 4-stranded na DNA. Ang ganitong istraktura ay nabuo kung mayroong apat na guanine, na bumubuo sa tinatawag na G-quadruplex - isang bilog na sayaw ng apat na guanine.
Ang mga unang pahiwatig ng posibilidad ng pagbuo ng naturang mga istraktura ay nakuha bago pa man ang pambihirang tagumpay ng Watson at Crick - kasing aga ng 1910. Pagkatapos ay natuklasan ng German chemist na si Ivar Bang na ang isa sa mga bahagi ng DNA - guanosic acid - ay bumubuo ng mga gel sa mataas na konsentrasyon, habang ang iba pang mga bahagi ng DNA ay walang katangiang ito.
Noong 1962, gamit ang X-ray diffraction method, posible na maitatag ang cell structure ng gel na ito. Ito ay naging binubuo ng apat na guanine residues, na nag-uugnay sa isa't isa sa isang bilog at bumubuo ng isang katangian na parisukat. Sa gitna, ang bono ay sinusuportahan ng isang metal na ion (Na, K, Mg). Ang parehong mga istraktura ay maaaring mabuo sa DNA kung naglalaman ito ng maraming guanine. Ang mga patag na parisukat na ito (G-quartets) ay nakasalansan upang bumuo ng medyo matatag, makakapal na istruktura (G-quadruplexes).
Apat na magkahiwalay na hibla ng DNA ay maaaring ihabi sa apat na stranded complex, ngunit ito ay isang pagbubukod. Mas madalas, ang isang solong strand ng nucleic acid ay itinatali lamang sa isang buhol, na bumubuo ng mga katangian na pampalapot (halimbawa, sa mga dulo ng mga chromosome), o ang double-stranded na DNA ay bumubuo ng isang lokal na quadruplex sa ilang lugar na mayaman sa guanine.
Ang pinaka-pinag-aralan ay ang pagkakaroon ng quadruplexes sa mga dulo ng chromosome - sa telomeres at sa mga oncopromoter. Gayunpaman, ang isang kumpletong pag-unawa sa lokalisasyon ng naturang DNA sa mga chromosome ng tao ay hindi pa rin alam.
Ang lahat ng hindi pangkaraniwang istrukturang ito ng DNA sa linear form ay hindi matatag kumpara sa B-form ng DNA. Gayunpaman, madalas na umiiral ang DNA sa isang ring form ng topological tension kapag mayroon itong tinatawag na supercoiling. Sa ilalim ng mga kundisyong ito, ang mga di-canonical na istruktura ng DNA ay madaling mabuo: Z-form, "crosses" at "hairpins", H-forms, guanine quadruplexes, at ang i-motif.
- Supercoiled form - napapansin kapag inilabas mula sa cell nucleus nang walang pinsala sa pentose-phosphate backbone. Mayroon itong anyo ng mga supertwisted closed ring. Sa supertwisted state, ang DNA double helix ay "twisted on itself" kahit isang beses lang, ibig sabihin, naglalaman ito ng hindi bababa sa isang supercoil (nakukuha ang hugis ng figure na walo).
- Relaxed na estado ng DNA - naobserbahan sa isang solong break (break ng isang strand). Sa kasong ito, nawawala ang mga supercoil at ang DNA ay nasa anyo ng isang saradong singsing.
- Ang linear na anyo ng DNA ay sinusunod kapag ang dalawang hibla ng double helix ay naputol.
Tertiary na istraktura ng DNA
Tertiary na istraktura ng DNA ay nabuo bilang isang resulta ng karagdagang pag-twist sa espasyo ng isang double-stranded molecule - ang supercoiling nito. Ang supercoiling ng molekula ng DNA sa mga eukaryotic na selula, sa kaibahan sa mga prokaryote, ay isinasagawa sa anyo ng mga complex na may mga protina.
Halos lahat ng eukaryotic DNA ay matatagpuan sa mga chromosome ng nuclei, isang maliit na halaga lamang nito ang matatagpuan sa mitochondria, at sa mga halaman at sa mga plastid. Ang pangunahing sangkap ng mga chromosome ng mga eukaryotic cell (kabilang ang mga chromosome ng tao) ay chromatin, na binubuo ng double-stranded DNA, histone at non-histone na mga protina.
Mga protina ng histone ng chromatin
Ang mga histone ay mga simpleng protina na bumubuo ng hanggang 50% ng chromatin. Sa lahat ng pinag-aralan na mga selula ng mga hayop at halaman, limang pangunahing klase ng mga histone ang natagpuan: H1, H2A, H2B, H3, H4, naiiba sa laki, komposisyon ng amino acid at singil (palaging positibo).
Ang mammalian histone H1 ay binubuo ng isang solong polypeptide chain na naglalaman ng humigit-kumulang 215 amino acids; ang mga sukat ng iba pang mga histone ay nag-iiba mula 100 hanggang 135 amino acids. Ang lahat ng mga ito ay spiralized at pinaikot sa isang globule na may diameter na humigit-kumulang 2.5 nm, naglalaman ng hindi pangkaraniwang malaking halaga ng positibong sisingilin na mga amino acid na lysine at arginine. Ang mga histone ay maaaring acetylated, methylated, phosphorylated, poly(ADP)-ribosylated, at ang mga histone na H2A at H2B ay maaaring covalently na maiugnay sa ubiquitin. Ano ang papel ng naturang mga pagbabago sa pagbuo ng istraktura at pagganap ng mga function ng mga histone ay hindi pa ganap na naipapaliwanag. Ipinapalagay na ito ang kanilang kakayahang makipag-ugnayan sa DNA at magbigay ng isa sa mga mekanismo para sa pag-regulate ng pagkilos ng mga gene.
Ang mga histone ay nakikipag-ugnayan sa DNA pangunahin sa pamamagitan ng mga ionic bond (mga tulay ng asin) na nabuo sa pagitan ng mga negatibong sisingilin na phosphate na grupo ng DNA at ang positibong sisingilin na lysine at arginine na mga nalalabi ng mga histone.
Mga non-histone na protina ng chromatin
Ang mga non-histone na protina, hindi katulad ng mga histone, ay lubhang magkakaibang. Hanggang sa 590 iba't ibang mga fraction ng DNA-binding nonhistone na mga protina ang nahiwalay. Tinatawag din silang mga acidic na protina, dahil ang mga acidic na amino acid ay nangingibabaw sa kanilang istraktura (sila ay mga polyanion). Ang partikular na regulasyon ng aktibidad ng chromatin ay nauugnay sa iba't ibang mga non-histone na protina. Halimbawa, ang mga enzyme na mahalaga para sa pagtitiklop at pagpapahayag ng DNA ay maaaring magbigkis sa chromatin nang pansamantala. Ang iba pang mga protina, sabi ng mga nasasangkot sa iba't ibang proseso ng regulasyon, ay nagbubuklod sa DNA lamang sa mga partikular na tisyu o sa ilang mga yugto ng pagkita ng kaibhan. Ang bawat protina ay pantulong sa isang tiyak na pagkakasunud-sunod ng DNA nucleotides (DNA site). Kasama sa pangkat na ito ang:
- isang pamilya ng mga protina ng daliri ng zinc na tukoy sa site. Kinikilala ng bawat "zinc finger" ang isang partikular na site na binubuo ng 5 pares ng nucleotide.
- isang pamilya ng mga protina na tukoy sa site - mga homodimer. Ang isang fragment ng naturang protina na nakikipag-ugnayan sa DNA ay may istrakturang "helix-turn-helix".
- high mobility proteins (HMG proteins - mula sa English, high mobility gel proteins) ay isang pangkat ng mga istruktura at regulatory protein na patuloy na nauugnay sa chromatin. Mayroon silang molekular na timbang na mas mababa sa 30 kD at nailalarawan sa pamamagitan ng mataas na nilalaman ng mga sinisingil na amino acid. Dahil sa kanilang mababang molekular na timbang, ang mga protina ng HMG ay lubos na gumagalaw sa panahon ng polyacrylamide gel electrophoresis.
- enzymes ng pagtitiklop, transkripsyon at pagkumpuni.
Sa partisipasyon ng mga istruktura, regulatory protein at enzymes na kasangkot sa synthesis ng DNA at RNA, ang nucleosome thread ay na-convert sa isang mataas na condensed complex ng mga protina at DNA. Ang resultang istraktura ay 10,000 beses na mas maikli kaysa sa orihinal na molekula ng DNA.

Chromatin
Ang Chromatin ay isang complex ng mga protina na may nuclear DNA at mga di-organikong sangkap. Karamihan sa chromatin ay hindi aktibo. Naglalaman ito ng densely packed, condensed DNA. Ito ay heterochromatin. Mayroong constitutive, genetically inactive na chromatin (satellite DNA) na binubuo ng mga hindi ipinahayag na rehiyon, at facultative - hindi aktibo sa isang bilang ng mga henerasyon, ngunit sa ilalim ng ilang mga pangyayari na may kakayahang magpahayag.
Ang aktibong chromatin (euchromatin) ay hindi naka-condensed, i.e. nakaimpake nang hindi gaanong mahigpit. Sa iba't ibang mga cell, ang nilalaman nito ay mula 2 hanggang 11%. Sa mga selula ng utak, ito ay ang pinaka - 10-11%, sa mga selula ng atay - 3-4 at bato - 2-3%. Mayroong aktibong transkripsyon ng euchromatin. Kasabay nito, ginagawang posible ng istrukturang organisasyon nito na gamitin ang parehong genetic na impormasyon ng DNA na likas sa isang partikular na uri ng organismo sa iba't ibang paraan sa mga espesyal na selula.
Sa isang electron microscope, ang imahe ng chromatin ay kahawig ng mga kuwintas: spherical thickenings na halos 10 nm ang laki, na pinaghihiwalay ng mga filamentous na tulay. Ang mga spherical thickening na ito ay tinatawag na nucleosome. Ang nucleosome ay ang istrukturang yunit ng chromatin. Ang bawat nucleosome ay naglalaman ng 146 bp long supercoiled DNA segment na sugat upang bumuo ng 1.75 kaliwa na pagliko sa bawat nucleosome core. Ang nucleosomal core ay isang histone octamer na binubuo ng mga histones H2A, H2B, H3 at H4, dalawang molekula ng bawat uri (Larawan 9), na mukhang isang disk na may diameter na 11 nm at isang kapal na 5.7 nm. Ang ikalimang histone, H1, ay hindi bahagi ng nucleosomal core at hindi kasama sa proseso ng pag-ikot ng DNA sa paligid ng histone octamer. Nakikipag-ugnayan ito sa DNA sa mga punto kung saan pumapasok at lumalabas ang double helix sa nucleosomal core. Ang mga ito ay intercore (linker) na mga seksyon ng DNA, ang haba nito ay nag-iiba depende sa uri ng cell mula 40 hanggang 50 na mga pares ng nucleotide. Bilang resulta, ang haba ng fragment ng DNA na bahagi ng mga nucleosome ay nag-iiba din (mula 186 hanggang 196 na mga pares ng nucleotide).
Ang nucleosome ay naglalaman ng humigit-kumulang 90% ng DNA, ang natitirang bahagi nito ay ang linker. Ito ay pinaniniwalaan na ang mga nucleosome ay mga fragment ng "silent" chromatin, habang ang linker ay aktibo. Gayunpaman, ang mga nucleosome ay maaaring magbuka at maging linear. Ang mga unfolded nucleosome ay aktibo nang chromatin. Ito ay malinaw na nagpapakita ng pag-asa ng pag-andar sa istraktura. Maaaring ipagpalagay na ang mas maraming chromatin ay nasa komposisyon ng mga globular nucleosome, hindi gaanong aktibo ito. Malinaw, sa iba't ibang mga cell ang hindi pantay na proporsyon ng resting chromatin ay nauugnay sa bilang ng mga naturang nucleosome.
Sa mga mikroskopikong larawan ng elektron, depende sa mga kondisyon ng paghihiwalay at ang antas ng pag-unat, ang chromatin ay maaaring magmukhang hindi lamang bilang isang mahabang thread na may mga pampalapot - "kuwintas" ng mga nucleosome, kundi pati na rin bilang isang mas maikli at mas siksik na fibril (hibla) na may diameter na 30 nm, ang pagbuo nito ay sinusunod sa panahon ng pakikipag-ugnayan histone H1 na nauugnay sa linker na rehiyon ng DNA at histone H3, na humahantong sa karagdagang pag-twist ng helix ng anim na nucleosome bawat pagliko na may pagbuo ng isang solenoid na may diameter na 30 nm . Sa kasong ito, ang protina ng histone ay maaaring makagambala sa transkripsyon ng isang bilang ng mga gene at sa gayon ay kinokontrol ang kanilang aktibidad.
Bilang resulta ng mga pakikipag-ugnayan ng DNA sa mga histone na inilarawan sa itaas, ang isang segment ng DNA double helix ng 186 base pairs na may average na diameter na 2 nm at isang haba na 57 nm ay nagiging helix na may diameter na 10 nm at isang haba. ng 5 nm. Sa kasunod na compression ng helix na ito sa isang hibla na may diameter na 30 nm, ang antas ng condensation ay tumataas ng isa pang anim na beses.
Sa huli, ang packaging ng DNA duplex na may limang histone ay nagreresulta sa 50-fold na condensation ng DNA. Gayunpaman, kahit na ang gayong mataas na antas ng condensation ay hindi maipaliwanag ang halos 50,000-100,000-fold na compaction ng DNA sa metaphase chromosome. Sa kasamaang palad, ang mga detalye ng karagdagang pag-iimpake ng chromatin hanggang sa metaphase chromosome ay hindi pa alam; samakatuwid, ang mga pangkalahatang tampok lamang ng prosesong ito ang maaaring isaalang-alang.
Mga antas ng compaction ng DNA sa mga chromosome
Ang bawat molekula ng DNA ay nakabalot sa isang hiwalay na chromosome. Ang mga diploid na selula ng tao ay naglalaman ng 46 chromosome, na matatagpuan sa cell nucleus. Ang kabuuang haba ng DNA ng lahat ng chromosome ng isang cell ay 1.74 m, ngunit ang diameter ng nucleus kung saan nakaimpake ang mga chromosome ay milyun-milyong beses na mas maliit. Ang ganitong compact packing ng DNA sa mga chromosome at chromosome sa cell nucleus ay ibinibigay ng iba't ibang histone at non-histone na mga protina na nakikipag-ugnayan sa isang tiyak na pagkakasunod-sunod sa DNA (tingnan sa itaas). Ginagawang posible ng compaction ng DNA sa mga chromosome na bawasan ang mga linear na dimensyon nito ng humigit-kumulang 10,000 beses - may kondisyon mula 5 cm hanggang 5 microns. Mayroong ilang mga antas ng compactization (Larawan 10).


- Ang double helix ng DNA ay isang molekulang negatibong sisingilin na may diameter na 2 nm at haba ng ilang cm.
- antas ng nucleosomal- Ang chromatin ay tumitingin sa isang electron microscope bilang isang chain ng "beads" - nucleosome - "sa isang thread". Ang nucleosome ay isang unibersal na yunit ng istruktura na matatagpuan pareho sa euchromatin at heterochromatin, sa interphase nucleus at metaphase chromosome.
Ang antas ng nucleosomal ng compaction ay ibinibigay ng mga espesyal na protina - histones. Walong mga domain ng histone na may positibong charge ang bumubuo sa core (core) ng nucleosome sa paligid kung saan nasugatan ang molekula ng DNA na may negatibong charge. Nagbibigay ito ng pagpapaikli sa pamamagitan ng isang kadahilanan na 7, habang ang diameter ay tumataas mula 2 hanggang 11 nm.
- antas ng solenoid
Ang solenoid level ng chromosome organization ay nailalarawan sa pamamagitan ng twisting ng nucleosomal filament at ang pagbuo ng mas makapal na fibrils na 20-35 nm ang lapad mula dito - solenoids o superbids. Ang solenoid pitch ay 11 nm, at mayroong mga 6-10 nucleosome bawat pagliko. Ang solenoid packing ay itinuturing na mas malamang kaysa sa superbid packing, ayon sa kung saan ang chromatin fibril na may diameter na 20–35 nm ay isang chain ng granules, o superbids, na ang bawat isa ay binubuo ng walong nucleosome. Sa antas ng solenoid, ang linear na laki ng DNA ay nabawasan ng 6-10 beses, ang diameter ay tumataas sa 30 nm.
- antas ng loop
Ang antas ng loop ay ibinibigay ng mga non-histone na site-specific na DNA-binding na protina na kumikilala at nagbubuklod sa mga partikular na sequence ng DNA, na bumubuo ng mga loop na humigit-kumulang 30-300 kb. Tinitiyak ng loop ang expression ng gene, i.e. ang loop ay hindi lamang isang istruktura, kundi pati na rin isang functional formation. Ang pagpapaikli sa antas na ito ay nangyayari ng 20-30 beses. Ang diameter ay tumataas sa 300 nm. Ang mga istrukturang tulad ng loop na "lampbrush" sa mga amphibian oocytes ay makikita sa mga cytological na paghahanda. Ang mga loop na ito ay lumilitaw na supercoiled at kumakatawan sa mga domain ng DNA, marahil ay tumutugma sa mga yunit ng chromatin transcription at replication. Inaayos ng mga partikular na protina ang mga base ng mga loop at, posibleng, ang ilan sa kanilang mga panloob na rehiyon. Pinapadali ng organisasyong tulad ng loop na domain ang pagtiklop ng chromatin sa mga metaphase chromosome sa mga helical na istruktura ng mas matataas na order.
- antas ng domain
Ang antas ng domain ng chromosome organization ay hindi pa napag-aralan nang sapat. Sa antas na ito, ang pagbuo ng mga domain ng loop ay nabanggit - ang mga istruktura ng filament (fibrils) 25-30 nm makapal, na naglalaman ng 60% protina, 35% DNA at 5% RNA, ay halos hindi nakikita sa lahat ng mga yugto ng cell cycle na may pagbubukod sa mitosis at medyo random na ipinamamahagi sa cell nucleus. Ang mga istrukturang tulad ng loop na "lampbrush" sa mga amphibian oocytes ay makikita sa mga cytological na paghahanda.
Ang mga loop na domain ay naka-attach kasama ang kanilang base sa intranuclear protein matrix sa tinatawag na built-in na mga attachment na site, na kadalasang tinutukoy bilang MAR / SAR sequence (MAR, mula sa English na matrix na nauugnay na rehiyon; SAR, mula sa English scaffold attachment na mga rehiyon) - Mga fragment ng DNA ng ilang daang mahabang base pairs na nailalarawan sa mataas na content (>65%) ng A/T base pairs. Ang bawat domain ay lumilitaw na may iisang pinagmulan ng pagtitiklop at gumagana bilang isang autonomous na supercoiled unit. Ang anumang loop domain ay naglalaman ng maraming transcription unit, ang paggana nito ay malamang na magkakaugnay - ang buong domain ay nasa isang aktibo o hindi aktibong estado.
Sa antas ng domain, bilang resulta ng sunud-sunod na pag-iimpake ng chromatin, ang mga linear na dimensyon ng DNA ay bumaba nang humigit-kumulang 200 beses (700 nm).
- antas ng chromosome
Sa antas ng chromosomal, ang prophase chromosome ay namumuo sa isang metaphase na may compaction ng mga loop domain sa paligid ng axial framework ng mga non-histone na protina. Ang supercoiling na ito ay sinamahan ng phosphorylation ng lahat ng H1 molecule sa cell. Bilang resulta, ang metaphase chromosome ay maaaring ilarawan bilang mga siksik na naka-pack na solenoid loop na nakapulupot sa isang masikip na spiral. Ang isang tipikal na chromosome ng tao ay maaaring maglaman ng hanggang 2600 na mga loop. Ang kapal ng naturang istraktura ay umabot sa 1400 nm (dalawang chromatids), habang ang molekula ng DNA ay pinaikli ng 104 beses, i.e. mula sa 5 cm na nakaunat na DNA hanggang 5 µm.
Mga function ng chromosome
Sa pakikipag-ugnayan sa mga mekanismo ng extrachromosomal, nagbibigay ang mga chromosome
- imbakan ng namamana na impormasyon
- gamit ang impormasyong ito upang lumikha at mapanatili ang cellular na organisasyon
- regulasyon ng pagbabasa ng namamana na impormasyon
- self-duplication ng genetic material
- ang paglipat ng genetic material mula sa isang mother cell patungo sa mga daughter cell.
Mayroong katibayan na sa pag-activate ng isang rehiyon ng chromatin, i.e. sa panahon ng transkripsyon, ang histone H1 ay nababaligtad muna dito, at pagkatapos ay ang histone octet. Nagdudulot ito ng decondensation ng chromatin, ang sunud-sunod na paglipat ng isang 30-nm chromatin fibril sa isang 10-nm filament at ang karagdagang paglalahad nito sa mga libreng rehiyon ng DNA, i.e. pagkawala ng istraktura ng nucleosomal.
Alam nating lahat na ang hitsura ng isang tao, ilang mga gawi at maging ang mga sakit ay namamana. Ang lahat ng impormasyong ito tungkol sa isang buhay na nilalang ay naka-encode sa mga gene. Kaya ano ang hitsura ng mga kilalang gene na ito, paano gumagana ang mga ito, at saan matatagpuan ang mga ito?
Kaya, ang carrier ng lahat ng gene ng sinumang tao o hayop ay DNA. Ang tambalang ito ay natuklasan noong 1869 ni Johann Friedrich Miescher. Sa kemikal, ang DNA ay deoxyribonucleic acid. Ano ang ibig sabihin nito? Paano dinadala ng acid na ito ang genetic code ng lahat ng buhay sa ating planeta?
Magsimula tayo sa pamamagitan ng pagtingin sa kung saan matatagpuan ang DNA. Mayroong maraming mga organel sa selula ng tao na gumaganap ng iba't ibang mga function. Ang DNA ay matatagpuan sa nucleus. Ang nucleus ay isang maliit na organelle na napapalibutan ng isang espesyal na lamad na nag-iimbak ng lahat ng genetic material - DNA.
Ano ang istraktura ng isang molekula ng DNA?
Una, tingnan natin kung ano ang DNA. Ang DNA ay isang napakahabang molekula na binubuo ng mga elemento ng istruktura - mga nucleotide. Mayroong 4 na uri ng nucleotides - adenine (A), thymine (T), guanine (G) at cytosine (C). Ang kadena ng mga nucleotide ay schematically ganito ang hitsura: GGAATTSTAAG.... Ang sequence ng mga nucleotides ay ang DNA chain.Ang istraktura ng DNA ay unang na-decipher noong 1953 nina James Watson at Francis Crick.
Sa isang molekula ng DNA, mayroong dalawang kadena ng mga nucleotide na pinaikot-ikot sa bawat isa. Paano nagdidikit ang mga nucleotide chain na ito at nagiging spiral? Ang kababalaghan na ito ay dahil sa pag-aari ng complementarity. Ang complementarity ay nangangahulugan na ang ilang mga nucleotide (complementary) lamang ang maaaring magkatapat sa bawat isa sa dalawang chain. Kaya, ang kabaligtaran ng adenine ay palaging thymine, at ang kabaligtaran ng guanine ay palaging cytosine lamang. Kaya, ang guanine ay komplementaryong may cytosine, at adenine kasama ang thymine.Ang ganitong mga pares ng nucleotides na magkatapat sa isa't isa sa iba't ibang chain ay tinatawag ding complementary.
 Maaari itong i-schematically na kinakatawan tulad ng sumusunod:
Maaari itong i-schematically na kinakatawan tulad ng sumusunod:
G - C
T - A
T - A
C - G
Ang mga komplementaryong pares na ito ay A - T at G - C form kemikal na dumidikit sa pagitan ng mga nucleotides ng pares, at ang bono sa pagitan ng G at C ay mas malakas kaysa sa pagitan ng A at T. Ang bono ay nabuo nang mahigpit sa pagitan ng mga komplementaryong base, iyon ay, imposible ang pagbuo ng isang bono sa pagitan ng hindi komplementaryong G at A.
Ang "packaging" ng DNA, paano nagiging chromosome ang isang strand ng DNA?
Bakit ang mga nucleotide chain na ito ng DNA ay umiikot din sa isa't isa? Bakit kailangan ito? Ang katotohanan ay ang bilang ng mga nucleotides ay napakalaki at kailangan mo ng maraming espasyo upang mapaunlakan ang mga ganoong mahabang kadena. Para sa kadahilanang ito, mayroong isang spiral twisting ng dalawang hibla ng DNA sa paligid ng isa. Itong kababalaghan ay tinatawag na spiralization. Bilang resulta ng spiralization, ang mga chain ng DNA ay pinaikli ng 5-6 beses.Ang ilang mga molekula ng DNA ay aktibong ginagamit ng katawan, habang ang iba ay bihirang ginagamit. Ang mga bihirang ginagamit na molekula ng DNA, bilang karagdagan sa helicalization, ay sumasailalim sa mas compact na "packaging". Ang ganitong compact na pakete ay tinatawag na supercoiling at pinaikli ang DNA strand ng 25-30 beses!
Paano nakabalot ang DNA helix?
 Para sa supercoiling, ginagamit ang mga protina ng histone, na may hitsura at istraktura ng isang baras o spool ng sinulid. Ang mga spiralized strands ng DNA ay nasugatan sa mga "coils" na ito - mga histone protein. Sa ganitong paraan, ang mahabang filament ay nagiging sobrang siksik at tumatagal ng napakaliit na espasyo.
Para sa supercoiling, ginagamit ang mga protina ng histone, na may hitsura at istraktura ng isang baras o spool ng sinulid. Ang mga spiralized strands ng DNA ay nasugatan sa mga "coils" na ito - mga histone protein. Sa ganitong paraan, ang mahabang filament ay nagiging sobrang siksik at tumatagal ng napakaliit na espasyo. Kung kinakailangan na gumamit ng isa o ibang molekula ng DNA, ang proseso ng "unwinding" ay nangyayari, iyon ay, ang DNA thread ay "unwound" mula sa "coil" - ang histone protein (kung ito ay nasugatan dito) at unwind mula sa ang helix sa dalawang parallel chain. At kapag ang molekula ng DNA ay nasa isang hindi nababagong estado, kung gayon ang kinakailangang genetic na impormasyon ay mababasa mula dito. Higit pa rito, ang pagbabasa ng genetic na impormasyon ay nangyayari lamang mula sa mga untwisted DNA strands!
Ang isang set ng mga supercoiled chromosome ay tinatawag heterochromatin, at ang mga chromosome na magagamit para sa pagbabasa ng impormasyon - euchromatin.
Ano ang mga gene, ano ang kanilang kaugnayan sa DNA?
Ngayon tingnan natin kung ano ang mga gene. Nabatid na may mga gene na tumutukoy sa pangkat ng dugo, kulay ng mata, buhok, balat at marami pang ibang katangian ng ating katawan. Ang gene ay isang mahigpit na tinukoy na seksyon ng DNA, na binubuo ng isang tiyak na bilang ng mga nucleotide na nakaayos sa isang mahigpit na tinukoy na kumbinasyon. Ang lokasyon sa isang mahigpit na tinukoy na seksyon ng DNA ay nangangahulugan na ang isang partikular na gene ay may lugar nito, at imposibleng baguhin ang lugar na ito. Angkop na gumawa ng gayong paghahambing: ang isang tao ay nakatira sa isang tiyak na kalye, sa isang tiyak na bahay at apartment, at ang isang tao ay hindi maaaring basta-basta lumipat sa ibang bahay, apartment o sa ibang kalye. Ang isang tiyak na bilang ng mga nucleotide sa isang gene ay nangangahulugan na ang bawat gene ay may isang tiyak na bilang ng mga nucleotides at hindi maaaring maging mas marami o mas kaunti. Halimbawa, ang gene encoding insulin production ay 60 base pairs ang haba; ang gene na naka-encode sa produksyon ng hormone oxytocin ay 370 bp. Ang isang mahigpit na pagkakasunud-sunod ng nucleotide ay natatangi para sa bawat gene at mahigpit na tinukoy. Halimbawa, ang AATTAATA sequence ay isang fragment ng isang gene na nagko-code para sa produksyon ng insulin. Upang makakuha ng insulin, ang gayong pagkakasunud-sunod lamang ang ginagamit; para makakuha, halimbawa, adrenaline, ginagamit ang ibang kumbinasyon ng mga nucleotide. Mahalagang maunawaan na ang isang tiyak na kumbinasyon ng mga nucleotide lamang ang nag-encode ng isang tiyak na "produkto" (adrenaline, insulin, atbp.). Ang ganitong natatanging kumbinasyon ng isang tiyak na bilang ng mga nucleotide, na nakatayo sa "lugar nito" - ito ay gene.
Bilang karagdagan sa mga gene, ang tinatawag na "non-coding sequences" ay matatagpuan sa DNA chain. Ang ganitong mga non-coding na nucleotide sequence ay kumokontrol sa paggana ng mga gene, tumutulong sa chromosome spiralization, at markahan ang simula at pagtatapos ng isang gene. Gayunpaman, hanggang ngayon, ang papel ng karamihan sa mga non-coding na pagkakasunud-sunod ay nananatiling hindi maliwanag.
Ano ang chromosome? mga chromosome sa sex
Ang kabuuan ng mga gene ng isang indibidwal ay tinatawag na genome. Naturally, ang buong genome ay hindi maaaring i-pack sa isang solong DNA. Ang genome ay nahahati sa 46 na pares ng mga molekula ng DNA. Ang isang pares ng mga molekula ng DNA ay tinatawag na chromosome. Kaya tiyak na ang mga chromosome na ito na ang isang tao ay may 46 na piraso. Ang bawat chromosome ay nagdadala ng isang mahigpit na tinukoy na hanay ng mga gene, halimbawa, ang ika-18 na chromosome ay naglalaman ng mga gene na naka-encode ng kulay ng mata, atbp. Ang mga chromosome ay naiiba sa haba at hugis. Ang pinakakaraniwang anyo ay nasa anyo ng X o Y, ngunit mayroon ding iba. Ang isang tao ay may dalawang chromosome ng parehong hugis, na tinatawag na paired (pares). Kaugnay ng gayong mga pagkakaiba, ang lahat ng ipinares na chromosome ay binibilang - mayroong 23 pares. Nangangahulugan ito na mayroong isang pares ng chromosome #1, pares #2, #3, at iba pa. Ang bawat gene na responsable para sa isang partikular na katangian ay matatagpuan sa parehong chromosome. Sa modernong mga manual para sa mga espesyalista, ang lokalisasyon ng gene ay maaaring ipahiwatig, halimbawa, tulad ng sumusunod: chromosome 22, mahabang braso.Ano ang mga pagkakaiba sa pagitan ng mga chromosome?
 Paano pa naiiba ang mga chromosome sa bawat isa? Ano ang ibig sabihin ng long arm? Kunin natin ang mga chromosome na hugis X. Ang pagtawid ng mga DNA strands ay maaaring mangyari nang mahigpit sa gitna (X), o maaari itong mangyari hindi sa gitna. Kapag ang naturang intersection ng DNA strands ay hindi nangyayari sa gitna, pagkatapos ay nauugnay sa punto ng intersection, ang ilang mga dulo ay mas mahaba, ang iba, ayon sa pagkakabanggit, ay mas maikli. Ang ganitong mga mahabang dulo ay karaniwang tinatawag na mahabang braso ng chromosome, at maikling mga dulo, ayon sa pagkakabanggit, ang maikling braso. Ang mga chromosome na hugis Y ay kadalasang inookupahan ng mahahabang braso, at ang mga maikli ay napakaliit (hindi man lang sila ipinahiwatig sa eskematiko na imahe).
Paano pa naiiba ang mga chromosome sa bawat isa? Ano ang ibig sabihin ng long arm? Kunin natin ang mga chromosome na hugis X. Ang pagtawid ng mga DNA strands ay maaaring mangyari nang mahigpit sa gitna (X), o maaari itong mangyari hindi sa gitna. Kapag ang naturang intersection ng DNA strands ay hindi nangyayari sa gitna, pagkatapos ay nauugnay sa punto ng intersection, ang ilang mga dulo ay mas mahaba, ang iba, ayon sa pagkakabanggit, ay mas maikli. Ang ganitong mga mahabang dulo ay karaniwang tinatawag na mahabang braso ng chromosome, at maikling mga dulo, ayon sa pagkakabanggit, ang maikling braso. Ang mga chromosome na hugis Y ay kadalasang inookupahan ng mahahabang braso, at ang mga maikli ay napakaliit (hindi man lang sila ipinahiwatig sa eskematiko na imahe). Ang laki ng mga chromosome ay nagbabago: ang pinakamalaki ay ang mga chromosome ng mga pares No. 1 at No. 3, ang pinakamaliit na chromosome ng mga pares No. 17, No. 19.
Bilang karagdagan sa mga hugis at sukat, ang mga chromosome ay naiiba sa kanilang mga pag-andar. Sa 23 pares, 22 pares ay somatic at 1 pares ay sekswal. Ano ang ibig sabihin nito? Tinutukoy ng mga somatic chromosome ang lahat ng mga panlabas na palatandaan ng isang indibidwal, ang kanyang mga tampok mga tugon sa pag-uugali, namamana na psychotype, iyon ay, lahat ng mga tampok at katangian ng bawat indibidwal na tao. Tinutukoy ng isang pares ng sex chromosome ang kasarian ng isang tao: lalaki o babae. Mayroong dalawang uri ng human sex chromosomes - X (X) at Y (Y). Kung sila ay pinagsama bilang XX (x - x) - ito ay isang babae, at kung XY (x - y) - mayroon kaming isang lalaki sa harap namin.
Mga namamana na sakit at pinsala sa chromosome
Gayunpaman, may mga "pagkasira" ng genome, pagkatapos ay nakita ang mga genetic na sakit sa mga tao. Halimbawa, kapag mayroong tatlong chromosome sa 21 pares ng chromosome sa halip na dalawa, ang isang tao ay ipinanganak na may Down syndrome.Mayroong maraming mas maliit na "pagkasira" ng genetic na materyal na hindi humahantong sa pagsisimula ng sakit, ngunit, sa kabaligtaran, ay nagbibigay ng magagandang katangian. Ang lahat ng "pagkasira" ng genetic na materyal ay tinatawag na mutations. Ang mga mutasyon na humahantong sa sakit o pagkasira ng mga katangian ng organismo ay itinuturing na negatibo, at ang mga mutasyon na humahantong sa pagbuo ng mga bagong kapaki-pakinabang na katangian ay itinuturing na positibo.
Gayunpaman, may kaugnayan sa karamihan sa mga sakit na dinaranas ng mga tao ngayon, ito ay hindi isang sakit na minana, ngunit isang predisposisyon lamang. Halimbawa, sa ama ng isang bata, ang asukal ay hinihigop nang dahan-dahan. Hindi ito nangangahulugan na ang bata ay ipanganak na may diabetes, ngunit ang bata ay magkakaroon ng predisposisyon. Nangangahulugan ito na kung ang isang bata ay nag-abuso sa mga matamis at mga produkto ng harina, pagkatapos ay magkakaroon siya ng diabetes.
Ngayon, ang tinatawag na predicative ang gamot. Bilang bahagi ng medikal na kasanayan na ito, ang mga predisposisyon ay nakikilala sa isang tao (batay sa pagkakakilanlan ng kaukulang mga gene), at pagkatapos ay ibinibigay sa kanya ang mga rekomendasyon - kung anong diyeta ang dapat sundin, kung paano maayos na kahalili ang mga rehimen sa trabaho at pahinga upang hindi makakuha ng may sakit.
Paano basahin ang impormasyong naka-encode sa DNA?
Ngunit paano mo mababasa ang impormasyong nakapaloob sa DNA? Paano ito ginagamit ng sarili niyang katawan? Ang DNA mismo ay isang uri ng matrix, ngunit hindi simple, ngunit naka-encode. Upang basahin ang impormasyon mula sa DNA matrix, unang inilipat ito sa isang espesyal na carrier - RNA. Ang RNA ay kemikal na ribonucleic acid. Ito ay naiiba sa DNA dahil maaari itong dumaan sa nuclear membrane papunta sa cell, habang ang DNA ay kulang sa kakayahang ito (ito ay matatagpuan lamang sa nucleus). Ang naka-encode na impormasyon ay ginagamit sa cell mismo. Kaya, ang RNA ay isang carrier ng naka-code na impormasyon mula sa nucleus hanggang sa cell.Paano nangyayari ang RNA synthesis, paano na-synthesize ang protina sa tulong ng RNA?
 Ang mga hibla ng DNA kung saan dapat "basahin" ang impormasyon ay hindi nalilito, isang espesyal na enzyme, ang "tagabuo", ay lumalapit sa kanila at nag-synthesize ng isang komplementaryong RNA chain na kahanay ng DNA strand. Ang molekula ng RNA ay binubuo rin ng 4 na uri ng nucleotides - adenine (A), uracil (U), guanine (G) at cytosine (C). Sa kasong ito, ang mga sumusunod na pares ay pantulong: adenine - uracil, guanine - cytosine. Tulad ng nakikita mo, hindi tulad ng DNA, ang RNA ay gumagamit ng uracil sa halip na thymine. Iyon ay, ang "tagabuo" na enzyme ay gumagana tulad ng sumusunod: kung nakikita nito ang A sa DNA strand, pagkatapos ay nakakabit ito sa Y sa RNA strand, kung G, pagkatapos ay nakakabit ito sa C, atbp. Kaya, ang isang template ay nabuo mula sa bawat aktibong gene sa panahon ng transkripsyon - isang kopya ng RNA na maaaring dumaan sa nuclear membrane.
Ang mga hibla ng DNA kung saan dapat "basahin" ang impormasyon ay hindi nalilito, isang espesyal na enzyme, ang "tagabuo", ay lumalapit sa kanila at nag-synthesize ng isang komplementaryong RNA chain na kahanay ng DNA strand. Ang molekula ng RNA ay binubuo rin ng 4 na uri ng nucleotides - adenine (A), uracil (U), guanine (G) at cytosine (C). Sa kasong ito, ang mga sumusunod na pares ay pantulong: adenine - uracil, guanine - cytosine. Tulad ng nakikita mo, hindi tulad ng DNA, ang RNA ay gumagamit ng uracil sa halip na thymine. Iyon ay, ang "tagabuo" na enzyme ay gumagana tulad ng sumusunod: kung nakikita nito ang A sa DNA strand, pagkatapos ay nakakabit ito sa Y sa RNA strand, kung G, pagkatapos ay nakakabit ito sa C, atbp. Kaya, ang isang template ay nabuo mula sa bawat aktibong gene sa panahon ng transkripsyon - isang kopya ng RNA na maaaring dumaan sa nuclear membrane. Paano naka-encode ang synthesis ng isang protina ng isang partikular na gene?
Pagkatapos umalis sa nucleus, ang RNA ay pumapasok sa cytoplasm. Nasa cytoplasm na, ang RNA ay maaaring, bilang isang matrix, na binuo sa mga espesyal na sistema ng enzyme (ribosomes), na maaaring synthesize, ginagabayan ng impormasyon ng RNA, ang kaukulang pagkakasunud-sunod ng amino acid ng protina. Tulad ng alam mo, ang isang molekula ng protina ay binubuo ng mga amino acid. Paano malalaman ng ribosome kung aling amino acid ang ikakabit sa lumalaking chain ng protina? Ginagawa ito batay sa isang triplet code. Ang triplet code ay nangangahulugan na ang pagkakasunud-sunod ng tatlong nucleotides ng RNA chain ( triplet, halimbawa, GGU) code para sa isang amino acid (sa kasong ito, glycine). Ang bawat amino acid ay naka-encode ng isang tiyak na triplet. At kaya, "binabasa" ng ribosome ang triplet, tinutukoy kung aling amino acid ang dapat idagdag sa susunod habang binabasa ang impormasyon sa RNA. Kapag ang isang kadena ng mga amino acid ay nabuo, ito ay tumatagal ng isang tiyak na spatial na anyo at nagiging isang protina na may kakayahang magsagawa ng enzymatic, pagbuo, hormonal at iba pang mga function na itinalaga dito.Ang protina para sa anumang buhay na organismo ay isang produkto ng gene. Ito ay mga protina na tumutukoy sa lahat ng iba't ibang mga katangian, katangian at panlabas na pagpapakita ng mga gene.
Sa kanan ay ang pinakamalaking human DNA helix na ginawa mula sa mga tao sa beach sa Varna (Bulgaria), na kasama sa Guinness Book of Records noong Abril 23, 2016
Deoxyribonucleic acid. Pangkalahatang Impormasyon
Ang DNA (deoxyribonucleic acid) ay isang uri ng blueprint ng buhay, isang kumplikadong code na naglalaman ng data sa namamana na impormasyon. Ang kumplikadong macromolecule na ito ay may kakayahang mag-imbak at magpadala ng namamana na genetic na impormasyon mula sa henerasyon hanggang sa henerasyon. Tinutukoy ng DNA ang mga katangian ng anumang buhay na organismo bilang pagmamana at pagkakaiba-iba. Tinutukoy ng impormasyong naka-encode dito ang buong programa ng pag-unlad ng anumang buhay na organismo. Ang mga genetically embedded na kadahilanan ay paunang tinutukoy ang buong kurso ng buhay ng isang tao at anumang iba pang organismo. Ang artipisyal o natural na impluwensya ng panlabas na kapaligiran ay maaari lamang bahagyang makaapekto sa pangkalahatang kalubhaan ng mga indibidwal na genetic na katangian o makakaapekto sa pagbuo ng mga naka-program na proseso.
Deoxyribonucleic acid(DNA) ay isang macromolecule (isa sa tatlong pangunahing, ang iba pang dalawa ay RNA at mga protina), na nagbibigay ng imbakan, paghahatid mula sa henerasyon hanggang sa henerasyon at pagpapatupad ng genetic program para sa pagbuo at paggana ng mga buhay na organismo. Naglalaman ang DNA ng impormasyon tungkol sa istruktura ng iba't ibang uri ng RNA at mga protina.
Sa mga eukaryotic cell (hayop, halaman, at fungi), ang DNA ay matatagpuan sa cell nucleus bilang bahagi ng mga chromosome, gayundin sa ilang cell organelles (mitochondria at plastids). Sa mga selula ng mga prokaryotic na organismo (bacteria at archaea), isang pabilog o linear na molekula ng DNA, ang tinatawag na nucleoid, ay nakakabit mula sa loob hanggang sa lamad ng selula. Ang mga ito at ang lower eukaryotes (halimbawa, yeast) ay mayroon ding maliit na autonomous, karamihan ay pabilog na mga molekula ng DNA na tinatawag na plasmids.
Mula sa isang kemikal na pananaw, ang DNA ay isang mahabang polymeric molecule na binubuo ng paulit-ulit na mga bloke - nucleotides. Ang bawat nucleotide ay binubuo ng isang nitrogenous base, isang asukal (deoxyribose), at isang phosphate group. Ang mga bono sa pagitan ng mga nucleotide sa isang kadena ay nabuo sa pamamagitan ng deoxyribose ( SA) at pospeyt ( F) pangkat (phosphodiester bonds).

kanin. 2. Ang nuclertide ay binubuo ng nitrogenous base, asukal (deoxyribose) at isang phosphate group
Sa napakaraming kaso (maliban sa ilang mga virus na naglalaman ng single-stranded DNA), ang DNA macromolecule ay binubuo ng dalawang chain na naka-orient sa nitrogenous base sa isa't isa. Ang double-stranded na molekula na ito ay pinaikot sa isang helix.
Mayroong apat na uri ng nitrogenous base na matatagpuan sa DNA (adenine, guanine, thymine, at cytosine). Ang nitrogenous base ng isa sa mga chain ay konektado sa nitrogenous base ng kabilang chain sa pamamagitan ng hydrogen bond ayon sa prinsipyo ng complementarity: ang adenine ay pinagsama lamang sa thymine ( A-T), guanine - may cytosine lamang ( G-C). Ang mga pares na ito ang bumubuo sa "mga baitang" ng helical na "hagdan" ng DNA (tingnan ang: Fig. 2, 3 at 4).

kanin. 2. Nitrogenous base
Ang pagkakasunud-sunod ng mga nucleotides ay nagpapahintulot sa iyo na "i-encode" ang impormasyon tungkol sa iba't ibang uri RNA, ang pinakamahalaga ay ang impormasyon o template (mRNA), ribosomal (rRNA) at transport (tRNA). Ang lahat ng mga uri ng RNA na ito ay na-synthesize sa DNA template sa pamamagitan ng pagkopya sa DNA sequence sa RNA sequence na na-synthesize sa panahon ng transkripsyon at nakikibahagi sa biosynthesis ng protina (proseso ng pagsasalin). Bilang karagdagan sa mga coding sequence, ang cell DNA ay naglalaman ng mga sequence na gumaganap ng mga regulatory at structural function.

kanin. 3. Pagtitiklop ng DNA
Ang lokasyon ng mga pangunahing kumbinasyon ng mga kemikal na compound ng DNA at ang dami ng mga ratio sa pagitan ng mga kumbinasyong ito ay nagbibigay ng pag-encode ng namamana na impormasyon.
Edukasyon bagong DNA (pagtitiklop)
- Ang proseso ng pagtitiklop: ang pag-unwinding ng DNA double helix - ang synthesis ng mga complementary strands ng DNA polymerase - ang pagbuo ng dalawang molekula ng DNA mula sa isa.
- Ang double helix ay "nag-unzip" sa dalawang sangay kapag sinira ng mga enzyme ang bono sa pagitan ng mga baseng pares ng mga kemikal na compound.
- Ang bawat sangay ay isang bagong elemento ng DNA. Ang mga bagong pares ng base ay konektado sa parehong pagkakasunud-sunod tulad ng sa pangunahing sangay.
Sa pagkumpleto ng pagdoble, dalawang independiyenteng helice ang nabuo, na nilikha mula sa mga kemikal na compound ng magulang na DNA at pagkakaroon ng parehong genetic code kasama nito. Sa ganitong paraan, ang DNA ay nakakapag-rip ng impormasyon mula sa cell patungo sa cell.
Higit pang detalyadong impormasyon:
ISTRUKTURA NG NUCLEIC ACID

kanin. 4 . Nitrogenous base: adenine, guanine, cytosine, thymine
Deoxyribonucleic acid(DNA) ay tumutukoy sa mga nucleic acid. Mga nucleic acid ay isang klase ng hindi regular na biopolymer na ang mga monomer ay mga nucleotides.
MGA NUCLEOTIDE binubuo ng nitrogenous na base, konektado sa isang limang-carbon carbohydrate (pentose) - deoxyribose(sa kaso ng DNA) o ribose(sa kaso ng RNA), na pinagsasama sa isang residue ng phosphoric acid (H 2 PO 3 -).
Nitrogenous base Mayroong dalawang uri: mga base ng pyrimidine - uracil (sa RNA lamang), cytosine at thymine, mga base ng purine - adenine at guanine.

kanin. Fig. 5. Ang istraktura ng mga nucleotides (kaliwa), ang lokasyon ng nucleotide sa DNA (ibaba) at ang mga uri ng nitrogenous base (kanan): pyrimidine at purine

Ang mga carbon atom sa isang pentose molecule ay binibilang mula 1 hanggang 5. Ang Phosphate ay pinagsama sa ikatlo at ikalimang carbon atoms. Ito ay kung paano pinagsama-sama ang mga nucleic acid upang bumuo ng isang kadena ng mga nucleic acid. Kaya, maaari nating ihiwalay ang 3' at 5' na dulo ng DNA strand:

kanin. 6. Paghihiwalay ng 3' at 5' na dulo ng DNA strand
Dalawang hibla ng DNA form dobleng helix. Ang mga chain na ito sa isang spiral ay nakatuon sa magkasalungat na direksyon. Sa iba't ibang mga hibla ng DNA, ang mga nitrogenous na base ay konektado sa isa't isa sa pamamagitan ng hydrogen bonds. Ang adenine ay palaging pinagsama sa thymine, at ang cytosine ay palaging pinagsama sa guanine. Ito ay tinatawag na tuntunin ng komplementaridad(cm. prinsipyo ng complementarity).
Panuntunan ng komplementaridad:
| A-T G-C |
Halimbawa, kung bibigyan tayo ng DNA strand na may sequence
3'-ATGTCCTAGCTGCTCG - 5',
pagkatapos ay ang pangalawang kadena ay magiging pantulong dito at ididirekta sa kabaligtaran na direksyon - mula sa 5'-end hanggang sa 3'-end:
5'- TACAGGATCGACGAGC- 3'.

kanin. 7. Ang direksyon ng mga chain ng DNA molecule at ang koneksyon ng nitrogenous bases gamit ang hydrogen bonds
DNA REPLICATION
Pagtitiklop ng DNA ay ang proseso ng pagdodoble ng molekula ng DNA sa pamamagitan ng template synthesis. Sa karamihan ng mga kaso ng natural na pagtitiklop ng DNApanimulang aklatpara sa DNA synthesis ay maikling snippet (nilikha muli). Ang nasabing ribonucleotide primer ay nilikha ng enzyme primase (DNA primase sa prokaryotes, DNA polymerase sa eukaryotes), at pagkatapos ay pinalitan ng deoxyribonucleotide polymerase, na karaniwang gumaganap ng mga function ng pag-aayos (pagwawasto ng pinsala sa kemikal at pagkasira sa molekula ng DNA).
Ang pagtitiklop ay nangyayari sa isang semi-konserbatibong paraan. Nangangahulugan ito na ang double helix ng DNA ay nag-unwinds at ang isang bagong chain ay nakumpleto sa bawat isa sa mga chain nito ayon sa prinsipyo ng complementarity. Ang molekula ng DNA ng anak na babae ay naglalaman ng isang strand mula sa molekula ng magulang at isang bagong synthesize. Ang pagtitiklop ay nangyayari sa 3' hanggang 5' na direksyon ng parent strand.

kanin. 8. Pagtitiklop (pagdodoble) ng molekula ng DNA
Synthesis ng DNA- hindi ito isang kumplikadong proseso na tila sa unang tingin. Kung iisipin mo ito, kailangan mo munang malaman kung ano ang synthesis. Ito ay ang proseso ng pagsasama-sama ng isang bagay. Ang pagbuo ng isang bagong molekula ng DNA ay nagaganap sa maraming yugto:
1) Ang DNA topoisomerase, na matatagpuan sa harap ng replication fork, ay pinuputol ang DNA upang mapadali ang pag-unwinding at pag-unwinding nito.
2) Ang DNA helicase, kasunod ng topoisomerase, ay nakakaapekto sa proseso ng "pag-unwinding" ng DNA helix.
3) Ang mga protina na nagbubuklod ng DNA ay nagsasagawa ng pagbubuklod ng mga hibla ng DNA, at isinasagawa din ang kanilang pagpapapanatag, na pinipigilan ang mga ito na dumikit sa isa't isa.
4) DNA polymerase δ(delta) , coordinated sa bilis ng paggalaw ng replication fork, nagsasagawa ng synthesisnangungunamga tanikala subsidiary DNA sa direksyon na 5" → 3" sa matrix maternal mga hibla ng DNA sa direksyon mula sa 3" dulo nito hanggang 5" na dulo (bilis hanggang 100 base pairs bawat segundo). Ang mga kaganapang ito maternal Ang mga hibla ng DNA ay limitado.

kanin. 9. Schematic na representasyon ng proseso ng pagtitiklop ng DNA: (1) Lagging strand (lag strand), (2) Leading strand (leading strand), (3) DNA polymerase α (Polα), (4) DNA ligase, (5) RNA -primer, (6) Primase, (7) Okazaki fragment, (8) DNA polymerase δ (Polδ ), (9) Helicase, (10) Single-stranded DNA-binding protein, (11) Topoisomerase.
Ang synthesis ng lagging daughter na DNA strand ay inilarawan sa ibaba (tingnan sa ibaba). scheme replication fork at function ng replication enzymes)
Para sa karagdagang impormasyon sa pagtitiklop ng DNA, tingnan ang
5) Kaagad pagkatapos ng pag-unwinding at pag-stabilize ng isa pang strand ng molekula ng magulang, ito ay sumasali.DNA polymerase α(alpha)at sa direksyon na 5 "→3" ay nag-synthesize ng isang primer (RNA primer) - isang RNA sequence sa isang template ng DNA na may haba na 10 hanggang 200 nucleotides. Pagkatapos nito, ang enzymetinanggal mula sa DNA strand.
sa halip na DNA polymeraseα
nakakabit sa 3" dulo ng primer DNA polymeraseε
.
6)
DNA polymeraseε
(epsilon) na parang patuloy na pahabain ang panimulang aklat, ngunit bilang isang substrate na naka-embeddeoxyribonucleotides(sa halagang 150-200 nucleotides). Bilang isang resulta, ang isang solidong thread ay nabuo mula sa dalawang bahagi -RNA(i.e. primer) at DNA.
DNA polymerase εgumagana hanggang sa makatagpo ito ng panimulang aklat ng naunafragment Okazaki(na-synthesize ng kaunti mas maaga). Ang enzyme na ito ay aalisin sa kadena.
7) DNA polymerase β(beta) ay pumapalit saDNA polymerases ε,gumagalaw sa parehong direksyon (5" → 3") at inaalis ang mga primer na ribonucleotides habang ipinapasok ang mga deoxyribonucleotides sa kanilang lugar. Gumagana ang enzyme hanggang sa kumpletong pag-alis ng panimulang aklat, i.e. hanggang sa isang deoxyribonucleotide (kahit na mas dati nang na-synthesizeDNA polymerase ε). Hindi maiugnay ng enzyme ang resulta ng trabaho nito at ang DNA sa harap, kaya umalis ito sa kadena.
Bilang resulta, ang isang fragment ng DNA ng anak na babae ay "namamalagi" sa matrix ng thread ng ina. Ito ay tinatawag nafragment ng Okazaki.
8) Ang DNA ligase ay nagpapalit ng dalawang katabi mga fragment ng Okazaki , ibig sabihin. 5 "-end ng segment, na-synthesizeDNA polymerase ε,at 3" chain end built-inDNA polymeraseβ .
ISTRUKTURA NG RNA
Ribonucleic acid(RNA) ay isa sa tatlong pangunahing macromolecules (ang iba pang dalawa ay DNA at mga protina) na matatagpuan sa mga selula ng lahat ng nabubuhay na organismo.
Tulad ng DNA, ang RNA ay binubuo ng isang mahabang kadena kung saan tinatawag ang bawat link nucleotide. Ang bawat nucleotide ay binubuo ng nitrogenous base, ribose sugar, at phosphate group. Gayunpaman, hindi tulad ng DNA, ang RNA ay karaniwang may isa sa halip na dalawang hibla. Ang pentose sa RNA ay kinakatawan ng ribose, hindi deoxyribose (ribose ay may karagdagang hydroxyl group sa pangalawang carbohydrate atom). Sa wakas, ang DNA ay naiiba sa RNA sa komposisyon ng mga nitrogenous base: sa halip na thymine ( T) uracil ay naroroon sa RNA ( U) , na pantulong din sa adenine.
Ang pagkakasunud-sunod ng mga nucleotides ay nagpapahintulot sa RNA na mag-encode ng genetic na impormasyon. Ang lahat ng cellular organism ay gumagamit ng RNA (mRNA) upang i-program ang synthesis ng protina.
Ang mga cellular RNA ay nabuo sa isang proseso na tinatawag transkripsyon , iyon ay, ang synthesis ng RNA sa isang template ng DNA, na isinasagawa ng mga espesyal na enzyme - RNA polymerases.
Ang mga Messenger RNA (mRNAs) ay nakikibahagi sa isang prosesong tinatawag broadcast, mga. synthesis ng protina sa template ng mRNA na may partisipasyon ng mga ribosome. Ang iba pang mga RNA ay sumasailalim sa mga pagbabagong kemikal pagkatapos ng transkripsyon, at pagkatapos ng pagbuo ng mga sekundarya at tersiyaryong istruktura, nagsasagawa sila ng mga function na nakasalalay sa uri ng RNA.

kanin. 10. Ang pagkakaiba sa pagitan ng DNA at RNA sa mga tuntunin ng nitrogenous base: sa halip na thymine (T), ang RNA ay naglalaman ng uracil (U), na pantulong din sa adenine.
TRANSCRIPTION
Ito ang proseso ng RNA synthesis sa isang template ng DNA. Nag-unwind ang DNA sa isa sa mga site. Ang isa sa mga chain ay naglalaman ng impormasyon na kailangang kopyahin sa RNA molecule - ang chain na ito ay tinatawag na coding. Ang pangalawang strand ng DNA, na pantulong sa coding strand, ay tinatawag na template strand. Sa proseso ng transkripsyon sa template chain sa 3'-5' na direksyon (kasama ang DNA chain), isang RNA chain na pandagdag dito ay na-synthesize. Kaya, ang isang kopya ng RNA ng coding strand ay nilikha.
![]()
kanin. 11. Schematic na representasyon ng transkripsyon
Halimbawa, kung bibigyan tayo ng sequence ng coding strand
3'-ATGTCCTAGCTGCTCG - 5',
pagkatapos, ayon sa panuntunan ng complementarity, ang matrix chain ay magdadala ng sequence
5'- TACAGGATCGACGAGC- 3',
at ang RNA na na-synthesize mula rito ay ang sequence
BROADCAST
Isaalang-alang ang mekanismo synthesis ng protina sa RNA matrix, pati na rin ang genetic code at mga katangian nito. Gayundin, para sa kalinawan, sa link sa ibaba, inirerekomenda naming manood ng maikling video tungkol sa mga proseso ng transkripsyon at pagsasalin na nagaganap sa isang buhay na cell:

kanin. 12. Proseso ng synthesis ng protina: Mga code ng DNA para sa RNA, mga code ng RNA para sa protina
GENETIC CODE
Genetic code- isang paraan ng pag-encode ng amino acid sequence ng mga protina gamit ang isang sequence ng nucleotides. Ang bawat amino acid ay naka-encode ng isang sequence ng tatlong nucleotides - isang codon o isang triplet.
Genetic code na karaniwan sa karamihan ng pro- at eukaryotes. Ang talahanayan ay naglilista ng lahat ng 64 na codon at naglilista ng kaukulang mga amino acid. Ang base order ay mula sa 5" hanggang 3" na dulo ng mRNA.
Talahanayan 1. Standard genetic code
|
1st nie |
2nd base |
ika-3 nie |
|||||||
|
U |
C |
A |
G |
||||||
|
U |
U U U |
(Phe/F) |
U C U |
(Ser/S) |
U A U |
(Tyr/Y) |
U G U |
(Cys/C) |
U |
|
U U C |
U C C |
U A C |
U G C |
C |
|||||
|
U U A |
(Leu/L) |
U C A |
U A A |
Itigil ang codon** |
U G A |
Itigil ang codon** |
A |
||
|
U U G |
U C G |
U A G |
Itigil ang codon** |
U G G |
(Trp/W) |
G |
|||
|
C |
C U U |
C C U |
(Pro/P) |
C A U |
(Kanya/H) |
C G U |
(Arg/R) |
U |
|
|
C U C |
C C C |
C A C |
C G C |
C |
|||||
|
C U A |
C C A |
C A A |
(Gln/Q) |
CGA |
A |
||||
|
C U G |
C C G |
C A G |
C G G |
G |
|||||
|
A |
A U U |
(Ile/I) |
A C U |
(Thr/T) |
A A U |
(Asn/N) |
A G U |
(Ser/S) |
U |
|
Isang U C |
A C C |
A A C |
A G C |
C |
|||||
|
A U A |
A C A |
A A A |
(Lys/K) |
A G A |
A |
||||
|
A U G |
(Met/M) |
A C G |
A A G |
A G G |
G |
||||
|
G |
G U U |
(Val/V) |
G C U |
(Ala/A) |
G A U |
(Asp/D) |
G G U |
(Gly/G) |
U |
|
G U C |
G C C |
G A C |
G G C |
C |
|||||
|
G U A |
G C A |
G A A |
(Glu/E) |
G G A |
A |
||||
|
G U G |
G C G |
G A G |
G G G |
G |
|||||
Sa mga triplet, mayroong 4 na espesyal na sequence na nagsisilbing "punctuation marks":
- *Triplet AUG, din ang pag-encode ng methionine, ay tinatawag simulan ang codon. Ang codon na ito ay nagsisimula sa synthesis ng isang molekula ng protina. Kaya, sa panahon ng synthesis ng protina, ang unang amino acid sa sequence ay palaging methionine.
- **Triplets UAA, UAG at UGA tinawag itigil ang mga codon at huwag mag-code para sa anumang mga amino acid. Sa mga sequence na ito, humihinto ang synthesis ng protina.
Mga katangian ng genetic code
1. Tripletity. Ang bawat amino acid ay naka-encode ng isang sequence ng tatlong nucleotides - isang triplet o codon.
2. Pagpapatuloy. Walang karagdagang mga nucleotide sa pagitan ng mga triplets, patuloy na binabasa ang impormasyon.
3. Hindi nagsasapawan. Ang isang nucleotide ay hindi maaaring maging bahagi ng dalawang triplets sa parehong oras.
4. Kakaiba. Ang isang codon ay maaaring mag-code para lamang sa isang amino acid.

5. Pagkabulok. Ang isang amino acid ay maaaring ma-encode ng maraming magkakaibang mga codon.

6. Kagalingan sa maraming bagay. Ang genetic code ay pareho para sa lahat ng nabubuhay na organismo.
Halimbawa. Binibigyan kami ng pagkakasunud-sunod ng coding strand:
3’- CCGATTGCACGTCGATCGTATA- 5’.
Ang matrix chain ay magkakaroon ng sequence:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
Ngayon ay "nag-synthesize" kami ng impormasyong RNA mula sa chain na ito:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
Ang synthesis ng protina ay napupunta sa direksyon na 5' → 3', samakatuwid, kailangan nating i-flip ang sequence upang "basahin" ang genetic code:
5’- AUAUGCUAGCUGCACGUUAGCC- 3’.
Ngayon hanapin ang start codon AUG:
5’- AU AUG CUAGCUGCACGUUAGCC- 3’.
Hatiin ang pagkakasunod-sunod sa triplets:
parang ganito: ang impormasyon mula sa DNA ay inililipat sa RNA (transkripsyon), mula RNA patungo sa protina (pagsasalin). Ang DNA ay maaari ding madoble sa pamamagitan ng pagtitiklop, at ang proseso ng reverse transcription ay posible rin, kapag ang DNA ay na-synthesize mula sa isang RNA template, ngunit ang ganitong proseso ay pangunahing katangian ng mga virus.

kanin. 13. Central Dogma molecular biology
GENOM: GENES AT CHROMOSOMES
(pangkalahatang konsepto)
Genome - ang kabuuan ng lahat ng mga gene ng isang organismo; kumpletong set ng chromosome nito.
Ang terminong "genome" ay iminungkahi ni G. Winkler noong 1920 upang ilarawan ang kabuuan ng mga gene na nakapaloob sa haploid set ng mga chromosome ng mga organismo ng parehong biological species. Ang orihinal na kahulugan ng terminong ito ay nagpapahiwatig na ang konsepto ng genome, sa kaibahan ng genotype, ay isang genetic na katangian ng species sa kabuuan, at hindi ng isang indibidwal. Sa pag-unlad ng molecular genetics, nagbago ang kahulugan ng terminong ito. Ito ay kilala na ang DNA, na siyang tagapagdala ng genetic na impormasyon sa karamihan ng mga organismo at, samakatuwid, ay bumubuo ng batayan ng genome, ay kinabibilangan ng hindi lamang mga gene sa modernong kahulugan ng salita. Karamihan ng Ang DNA ng mga eukaryotic cell ay kinakatawan ng non-coding (“redundant”) nucleotide sequence na hindi naglalaman ng impormasyon tungkol sa mga protina at nucleic acid. Kaya, ang pangunahing bahagi ng genome ng anumang organismo ay ang buong DNA ng haploid set ng mga chromosome nito.
Ang mga gene ay mga segment ng mga molekula ng DNA na nagko-code para sa mga polypeptides at mga molekula ng RNA.
Sa nakalipas na siglo, malaki ang pagbabago sa ating pag-unawa sa mga gene. Dati, ang genome ay isang rehiyon ng isang chromosome na nag-encode o tumutukoy sa isang katangian o phenotypic(nakikita) ari-arian, tulad ng kulay ng mata.
Noong 1940, iminungkahi nina George Beadle at Edward Tatham ang isang molekular na kahulugan ng isang gene. Pinoproseso ng mga siyentipiko ang mga spore ng fungus Neurospora crassa X-ray at iba pang mga ahente na nagdudulot ng mga pagbabago sa pagkakasunud-sunod ng DNA ( mutasyon), at natagpuan ang mga mutant strain ng fungus na nawalan ng ilang partikular na enzyme, na sa ilang mga kaso ay humantong sa pagkagambala sa buong metabolic pathway. Sina Beadle at Tatham ay dumating sa konklusyon na ang isang gene ay isang seksyon ng genetic na materyal na tumutukoy o nagko-code para sa isang enzyme. Ganito ang hypothesis "isang gene, isang enzyme". Ang konseptong ito ay kalaunan ay pinalawak sa kahulugan "isang gene - isang polypeptide", dahil maraming mga gene ang nag-encode ng mga protina na hindi mga enzyme, at ang polypeptide ay maaaring maging isang subunit ng isang kumplikadong protina complex.
Sa fig. Ang 14 ay nagpapakita ng isang diagram kung paano tinutukoy ng mga triplet ng DNA ang isang polypeptide, ang pagkakasunud-sunod ng amino acid ng isang protina, na pinapamagitan ng mRNA. Ang isa sa mga strand ng DNA ay gumaganap ng papel ng isang template para sa synthesis ng mRNA, ang mga nucleotide triplets (codons) na kung saan ay pantulong sa DNA triplets. Sa ilang bakterya at maraming eukaryote, ang mga pagkakasunud-sunod ng coding ay naaantala ng mga rehiyong hindi nagko-coding (tinatawag na mga intron).
Modernong biochemical na kahulugan ng isang gene mas partikular. Ang mga gene ay lahat ng mga seksyon ng DNA na nag-encode sa pangunahing sequence ng mga end product, na kinabibilangan ng mga polypeptides o RNA na may structural o catalytic function.
Kasama ng mga gene, naglalaman din ang DNA ng iba pang mga sequence na gumaganap ng eksklusibong pagpapaandar ng regulasyon. Mga pagkakasunud-sunod ng regulasyon maaaring markahan ang simula o pagtatapos ng mga gene, makaapekto sa transkripsyon, o ipahiwatig ang lugar ng pagsisimula ng pagtitiklop o recombination. Ang ilang mga gene ay maaaring ipahayag sa iba't ibang paraan, na may parehong piraso ng DNA na nagsisilbing template para sa pagbuo ng iba't ibang mga produkto.
Maaari naming halos kalkulahin pinakamababang laki ng gene coding para sa intermediate na protina. Ang bawat amino acid sa isang polypeptide chain ay naka-encode ng isang sequence ng tatlong nucleotides; ang mga pagkakasunud-sunod ng mga triplet na ito (codons) ay tumutugma sa kadena ng mga amino acid sa polypeptide na naka-encode ng ibinigay na gene. Ang polypeptide chain ng 350 amino acid residues (medium length chain) ay tumutugma sa isang sequence na 1050 bp. ( bp). Gayunpaman, maraming eukaryotic genes at ilang prokaryotic genes ang nagambala ng mga segment ng DNA na hindi tagapagdala ng impormasyon tungkol sa protina, at samakatuwid ay naging mas mahaba kaysa sa isang simpleng ipinapakita ng pagkalkula.
Ilang gene ang nasa isang chromosome?
 kanin. 15. View ng mga chromosome sa prokaryotic (kaliwa) at eukaryotic cells. Ang mga histone ay isang malawak na klase ng mga nuklear na protina na gumaganap ng dalawang pangunahing pag-andar: sila ay kasangkot sa pag-iimpake ng mga hibla ng DNA sa nucleus at sa epigenetic na regulasyon ng mga prosesong nuklear tulad ng transkripsyon, pagtitiklop, at pagkumpuni.
kanin. 15. View ng mga chromosome sa prokaryotic (kaliwa) at eukaryotic cells. Ang mga histone ay isang malawak na klase ng mga nuklear na protina na gumaganap ng dalawang pangunahing pag-andar: sila ay kasangkot sa pag-iimpake ng mga hibla ng DNA sa nucleus at sa epigenetic na regulasyon ng mga prosesong nuklear tulad ng transkripsyon, pagtitiklop, at pagkumpuni.
Ang DNA ng mga prokaryote ay mas simple: ang kanilang mga cell ay walang nucleus, kaya ang DNA ay matatagpuan nang direkta sa cytoplasm sa anyo ng isang nucleoid.
 Tulad ng alam mo, ang mga bacterial cell ay may chromosome sa anyo ng isang DNA strand, na nakaimpake sa isang compact na istraktura - isang nucleoid. prokaryotic chromosome Escherichia coli, na ang genome ay ganap na na-decode, ay isang pabilog na molekula ng DNA (sa katunayan, hindi ito kanang bilog, ngunit sa halip ay isang loop na walang simula o wakas), na binubuo ng 4,639,675 b.p. Ang pagkakasunud-sunod na ito ay naglalaman ng humigit-kumulang 4300 na mga gene ng protina at isa pang 157 na mga gene para sa mga matatag na molekula ng RNA. V genome ng tao humigit-kumulang 3.1 bilyong base pairs na tumutugma sa halos 29,000 genes na matatagpuan sa 24 na magkakaibang chromosome.
Tulad ng alam mo, ang mga bacterial cell ay may chromosome sa anyo ng isang DNA strand, na nakaimpake sa isang compact na istraktura - isang nucleoid. prokaryotic chromosome Escherichia coli, na ang genome ay ganap na na-decode, ay isang pabilog na molekula ng DNA (sa katunayan, hindi ito kanang bilog, ngunit sa halip ay isang loop na walang simula o wakas), na binubuo ng 4,639,675 b.p. Ang pagkakasunud-sunod na ito ay naglalaman ng humigit-kumulang 4300 na mga gene ng protina at isa pang 157 na mga gene para sa mga matatag na molekula ng RNA. V genome ng tao humigit-kumulang 3.1 bilyong base pairs na tumutugma sa halos 29,000 genes na matatagpuan sa 24 na magkakaibang chromosome.
Prokaryotes (Bacteria).
 Bacterium E. coli ay may isang double-stranded na pabilog na molekula ng DNA. Binubuo ito ng 4,639,675 b.p. at umabot sa haba na humigit-kumulang 1.7 mm, na lumalampas sa haba ng cell mismo E. coli humigit-kumulang 850 beses. Bilang karagdagan sa malaking pabilog na chromosome bilang bahagi ng nucleoid, maraming bakterya ang naglalaman ng isa o higit pang maliliit na pabilog na molekula ng DNA na malayang matatagpuan sa cytosol. Ang mga extrachromosomal na elementong ito ay tinatawag plasmids(Larawan 16).
Bacterium E. coli ay may isang double-stranded na pabilog na molekula ng DNA. Binubuo ito ng 4,639,675 b.p. at umabot sa haba na humigit-kumulang 1.7 mm, na lumalampas sa haba ng cell mismo E. coli humigit-kumulang 850 beses. Bilang karagdagan sa malaking pabilog na chromosome bilang bahagi ng nucleoid, maraming bakterya ang naglalaman ng isa o higit pang maliliit na pabilog na molekula ng DNA na malayang matatagpuan sa cytosol. Ang mga extrachromosomal na elementong ito ay tinatawag plasmids(Larawan 16).
Karamihan sa mga plasmid ay binubuo lamang ng ilang libong base pairs, ang ilan ay naglalaman ng higit sa 10,000 bp. Nagdadala sila ng genetic na impormasyon at gumagaya upang bumuo ng mga plasmid ng anak na babae, na pumapasok sa mga selula ng anak na babae sa panahon ng paghahati ng selula ng magulang. Ang mga plasmid ay matatagpuan hindi lamang sa bakterya, kundi pati na rin sa lebadura at iba pang fungi. Sa maraming mga kaso, ang mga plasmid ay hindi nag-aalok ng kalamangan sa mga host cell at ang kanilang tanging trabaho ay upang magparami nang nakapag-iisa. Gayunpaman, ang ilang mga plasmid ay nagdadala ng mga gene na kapaki-pakinabang sa host. Halimbawa, ang mga gene na nakapaloob sa mga plasmid ay maaaring magbigay ng paglaban sa mga antibacterial agent sa bacterial cells. Ang mga plasmid na nagdadala ng β-lactamase gene ay nagbibigay ng paglaban sa mga β-lactam antibiotic tulad ng penicillin at amoxicillin. Maaaring dumaan ang mga plasmid mula sa mga cell na lumalaban sa antibiotic patungo sa iba pang mga cell ng pareho o iba't ibang bacterial species, na nagiging sanhi ng mga cell na iyon na maging lumalaban din. Ang masinsinang paggamit ng mga antibiotic ay isang makapangyarihang selective factor na nagsusulong ng pagkalat ng mga plasmid na nag-e-encode ng antibiotic resistance (pati na rin ang mga transposon na nag-encode ng mga katulad na gene) sa mga pathogenic bacteria, at humahantong sa paglitaw ng mga bacterial strain na may resistensya sa ilang antibiotics. Ang mga doktor ay nagsisimulang maunawaan ang mga panganib ng malawakang paggamit ng mga antibiotics at inireseta lamang ang mga ito kapag talagang kinakailangan. Para sa mga katulad na dahilan, ang malawakang paggamit ng mga antibiotic para sa paggamot ng mga hayop sa bukid ay limitado.
Tingnan din: Ravin N.V., Shestakov S.V. Genome of prokaryotes // Vavilov Journal of Genetics and Breeding, 2013. V. 17. No. 4/2. pp. 972-984.
Eukaryotes.
Talahanayan 2. DNA, mga gene at chromosome ng ilang mga organismo
|
nakabahaging DNA, b.s. |
Bilang ng mga chromosome* |
Tinatayang bilang ng mga gene |
|
|
Escherichia coli(bacterium) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(lebadura) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans(nematode) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana(halaman) |
119 186 200 |
33 000 |
|
|
Drosophila melanogaster(lipad ng prutas) |
120 367 260 |
20 000 |
|
|
Oryza sativa(bigas) |
480 000 000 |
57 000 |
|
|
Mus muscle(mouse) |
2 634 266 500 |
27 000 |
|
|
Homo sapiens(Tao) |
3 070 128 600 |
29 000 |
Tandaan. Ang impormasyon ay patuloy na ina-update; Para sa higit pang napapanahong impormasyon, sumangguni sa mga indibidwal na website ng genomic na proyekto.
* Para sa lahat ng eukaryote, maliban sa lebadura, ang diploid na hanay ng mga chromosome ay ibinibigay. diploid kit chromosome (mula sa Greek diploos - double at eidos - view) - dobleng hanay ng mga chromosome(2n), ang bawat isa ay may homology sa sarili nito.
**Haploid set. Ang mga ligaw na strain ng yeast ay karaniwang may walong (octaploid) o higit pang set ng mga chromosome na ito.
***Para sa mga babaeng may dalawang X chromosome. Ang mga lalaki ay may X chromosome, ngunit walang Y, ibig sabihin, 11 chromosome lamang.
Ang yeast cell, isa sa pinakamaliit na eukaryote, ay may 2.6 beses na mas maraming DNA kaysa sa isang cell E. coli(Talahanayan 2). mga selula ng langaw ng prutas Drosophila, isang klasikong bagay ng genetic research, ay naglalaman ng 35 beses na mas maraming DNA, at ang mga cell ng tao ay naglalaman ng humigit-kumulang 700 beses na mas maraming DNA kaysa sa mga cell. E. coli. Maraming halaman at amphibian ang naglalaman ng higit pang DNA. Ang genetic na materyal ng mga eukaryotic cell ay nakaayos sa anyo ng mga chromosome. Diploid set ng mga chromosome (2 n) depende sa uri ng organismo (Talahanayan 2).
Halimbawa, sa isang somatic cell ng tao mayroong 46 chromosome ( kanin. 17). Ang bawat chromosome sa isang eukaryotic cell, tulad ng ipinapakita sa Fig. 17, a, ay naglalaman ng isang napakalaking double-stranded na molekula ng DNA. Dalawampu't apat na chromosome ng tao (22 magkapares na chromosome at dalawang sex chromosome X at Y) ay nag-iiba sa haba ng higit sa 25 beses. Ang bawat eukaryotic chromosome ay naglalaman ng isang tiyak na hanay ng mga gene.

kanin. 17. eukaryotic chromosome.a- isang pares ng konektado at condensed sister chromatid mula sa human chromosome. Sa form na ito, ang mga eukaryotic chromosome ay nananatili pagkatapos ng pagtitiklop at sa metaphase sa panahon ng mitosis. b- isang kumpletong hanay ng mga chromosome mula sa isang leukocyte ng isa sa mga may-akda ng libro. Ang bawat normal na somatic cell ng tao ay naglalaman ng 46 chromosome.

Ang laki at pag-andar ng DNA bilang isang matrix para sa pag-iimbak at pagpapadala ng namamana na materyal ay nagpapaliwanag ng pagkakaroon ng mga espesyal na elemento ng istruktura sa organisasyon ng molekula na ito. Sa mas mataas na mga organismo, ang DNA ay ipinamamahagi sa pagitan ng mga chromosome.
Ang set ng DNA (chromosome) ng isang organismo ay tinatawag na genome. Ang mga chromosome ay matatagpuan sa cell nucleus at bumubuo ng isang istraktura na tinatawag na chromatin. Ang Chromatin ay isang complex ng DNA at mga pangunahing protina (histones) sa isang 1:1 ratio. Ang haba ng DNA ay karaniwang sinusukat sa pamamagitan ng bilang ng mga pares ng komplementaryong nucleotides (bp). Halimbawa, ang 3rd human chromosomesiglo ay isang molekula ng DNA na may sukat na 160 milyong bp. ay may haba na humigit-kumulang 1 mm, samakatuwid, ang isang linearized na molekula ng 3rd human chromosome ay magiging 5 mm ang haba, at ang DNA ng lahat ng 23 chromosome (~ 3 * 10 9 bp, MR = 1.8 * 10 12) ng isang haploid cell - egg o sperm cell - sa isang linearized na anyo ay magiging 1 m. Maliban sa mga cell ng mikrobyo, lahat ng mga cell ng katawan ng tao (mayroong mga 1013 sa kanila) ay naglalaman ng isang double set ng mga chromosome. Sa panahon ng paghahati ng cell, ang lahat ng 46 na molekula ng DNA ay gumagaya at muling nag-aayos sa 46 na chromosome.
Kung ikinonekta mo ang mga molekula ng DNA ng genome ng tao (22 chromosome at chromosome X at Y o X at X) sa isa't isa, makakakuha ka ng isang sequence na halos isang metro ang haba. Tandaan: Sa lahat ng mammal at iba pang heterogametic na organismong lalaki, ang mga babae ay may dalawang X chromosome (XX) at ang mga lalaki ay may isang X chromosome at isang Y chromosome (XY).
Karamihan sa mga selula ng tao, kaya ang kabuuang haba ng DNA ng naturang mga selula ay humigit-kumulang 2m. Ang isang may sapat na gulang na tao ay may humigit-kumulang 10 14 na mga selula, kaya ang kabuuang haba ng lahat ng mga molekula ng DNA ay 2・10 11 km. Para sa paghahambing, ang circumference ng Earth ay 4・10 4 km, at ang distansya mula sa Earth hanggang sa Araw ay 1.5・10 8 km. Ganyan kahanga-hangang compactly packaged na DNA sa ating mga cell!
Sa mga eukaryotic cell, mayroong iba pang mga organel na naglalaman ng DNA - ito ay mitochondria at chloroplast. Maraming mga hypotheses ang iniharap tungkol sa pinagmulan ng mitochondrial at chloroplast DNA. Ang pangkalahatang tinatanggap na pananaw ngayon ay ang mga ito ay ang mga simulain ng mga chromosome ng sinaunang bakterya na tumagos sa cytoplasm ng mga host cell at naging mga pasimula ng mga organel na ito. Mitochondrial DNA code para sa mitochondrial tRNA at rRNA, pati na rin ang ilang mitochondrial protein. Higit sa 95% ng mitochondrial proteins ay naka-encode ng nuclear DNA.
ISTRUKTURA NG MGA GENES
Isaalang-alang ang istruktura ng gene sa mga prokaryote at eukaryotes, ang kanilang pagkakatulad at pagkakaiba. Sa kabila ng katotohanan na ang isang gene ay isang seksyon ng DNA na naka-encode lamang ng isang protina o RNA, bilang karagdagan sa direktang bahagi ng coding, kabilang din dito ang mga regulatory at iba pang mga elemento ng istruktura na may ibang istraktura sa mga prokaryote at eukaryotes.
pagkakasunud-sunod ng coding- ang pangunahing estruktural at functional unit ng gene, nasa loob nito ang mga triplets ng nucleotides encodingpagkakasunud-sunod ng amino acid. Nagsisimula ito sa isang start codon at nagtatapos sa isang stop codon.
Bago at pagkatapos ng coding sequence ay hindi na-translate na 5' at 3' na mga sequence. Nagsasagawa sila ng mga regulatory at auxiliary function, halimbawa, tinitiyak ang landing ng ribosome sa mRNA.
Ang mga hindi na-translated at coding sequence ay bumubuo ng isang transcription unit - isang na-transcribe na rehiyon ng DNA, iyon ay, isang rehiyon ng DNA kung saan na-synthesize ang mRNA.
Terminator Isang hindi na-transcribe na rehiyon ng DNA sa dulo ng isang gene kung saan humihinto ang RNA synthesis.
Sa simula ng gene ay lugar ng regulasyon, na kinabibilangan ng tagataguyod at operator.
tagataguyod- ang pagkakasunud-sunod kung saan ang polymerase ay nagbubuklod sa panahon ng pagsisimula ng transkripsyon. Operator- ito ang lugar kung saan maaaring magbigkis ang mga espesyal na protina - mga panunupil, na maaaring bawasan ang aktibidad ng RNA synthesis mula sa gene na ito - sa madaling salita, bawasan ito pagpapahayag.
Ang istraktura ng mga gene sa prokaryotes
Ang pangkalahatang plano para sa istraktura ng mga gene sa mga prokaryote at eukaryote ay hindi naiiba - pareho sa mga ito ay naglalaman ng isang rehiyon ng regulasyon na may isang tagataguyod at operator, isang yunit ng transkripsyon na may mga coding at hindi na-translate na mga pagkakasunud-sunod, at isang terminator. Gayunpaman, ang organisasyon ng mga gene sa prokaryotes at eukaryotes ay magkaiba.

kanin. 18. Scheme ng istraktura ng gene sa prokaryotes (bacteria) -ang imahe ay pinalaki
Sa simula at sa dulo ng operon, may mga karaniwang regulasyong rehiyon para sa ilang mga istrukturang gene. Mula sa na-transcribe na rehiyon ng operon, binabasa ang isang molekula ng mRNA, na naglalaman ng ilang mga pagkakasunud-sunod ng coding, bawat isa ay may sariling simula at stop codon. Mula sa bawat isa sa mga lugar na itoisang protina ang na-synthesize. Sa ganitong paraan, Mula sa isang molekula ng RNA, maraming mga molekula ng protina ang na-synthesize.
Ang mga prokaryote ay nailalarawan sa pamamagitan ng kumbinasyon ng ilang mga gene sa isang solong functional unit - operon. Ang gawain ng operon ay maaaring kontrolin ng iba pang mga gene, na maaaring kapansin-pansing alisin mula sa operon mismo - mga regulator. Ang protina na isinalin mula sa gene na ito ay tinatawag panunupil. Ito ay nagbubuklod sa operator ng operon, na kinokontrol ang pagpapahayag ng lahat ng mga gene na nakapaloob dito nang sabay-sabay.
Ang mga prokaryote ay nailalarawan din ng hindi pangkaraniwang bagay transkripsyon at pagsasalin ng conjugations.
![]()
kanin. 19 Ang phenomenon ng transcription at translation coupling sa prokaryotes - ang imahe ay pinalaki
Ang pagpapares na ito ay hindi nangyayari sa mga eukaryotes dahil sa pagkakaroon ng isang nuclear envelope na naghihiwalay sa cytoplasm, kung saan nagaganap ang pagsasalin, mula sa genetic na materyal, kung saan nangyayari ang transkripsyon. Sa mga prokaryote, sa panahon ng synthesis ng RNA sa isang template ng DNA, ang isang ribosome ay maaaring agad na magbigkis sa synthesized na molekula ng RNA. Kaya, nagsisimula ang pagsasalin bago pa man makumpleto ang transkripsyon. Bukod dito, maraming ribosom ang maaaring sabay-sabay na magbigkis sa isang molekula ng RNA, na nag-synthesize ng ilang molekula ng isang protina nang sabay-sabay.
Ang istraktura ng mga gene sa eukaryotes
Ang mga gene at chromosome ng mga eukaryote ay napaka kumplikadong organisado.
Ang bakterya ng maraming species ay may isang chromosome lamang, at sa halos lahat ng kaso mayroong isang kopya ng bawat gene sa bawat chromosome. Ilang genes lang, gaya ng rRNA genes, ang nakapaloob sa maraming kopya. Ang mga gene at regulatory sequence ay bumubuo sa halos buong genome ng prokaryotes. Bukod dito, halos bawat gene ay mahigpit na tumutugma sa pagkakasunud-sunod ng amino acid (o pagkakasunud-sunod ng RNA) na ine-encode nito (Larawan 14).
Ang istruktura at functional na organisasyon ng eukaryotic genes ay mas kumplikado. Ang pag-aaral ng mga eukaryotic chromosome, at kalaunan ang pagkakasunud-sunod ng kumpletong eukaryotic genome sequences, ay nagdala ng maraming mga sorpresa. Marami, kung hindi man karamihan, ang mga eukaryotic genes ay may isang kawili-wiling tampok: ang kanilang mga nucleotide sequence ay naglalaman ng isa o higit pang mga rehiyon ng DNA na hindi naka-encode sa amino acid sequence ng polypeptide na produkto. Ang ganitong mga hindi na-translate na pagsingit ay nakakagambala sa direktang pagsusulatan sa pagitan ng nucleotide sequence ng gene at ng amino acid sequence ng naka-encode na polypeptide. Ang mga hindi naisaling segment na ito sa mga gene ay tinatawag mga intron, o built-in mga pagkakasunod-sunod, at ang mga segment ng coding ay mga exon. Sa mga prokaryote, iilan lamang sa mga gene ang naglalaman ng mga intron.
Kaya, sa mga eukaryote, halos walang kumbinasyon ng mga gene sa mga operon, at ang coding sequence ng isang eukaryotic gene ay kadalasang nahahati sa mga isinaling rehiyon. - mga exon, at mga hindi naisaling seksyon - mga intron.
Sa karamihan ng mga kaso, ang pag-andar ng mga intron ay hindi pa naitatag. Sa pangkalahatan, halos 1.5% lamang ng DNA ng tao ang "coding", ibig sabihin, nagdadala ito ng impormasyon tungkol sa mga protina o RNA. Gayunpaman, isinasaalang-alang ang malalaking intron, lumalabas na ang 30% ng DNA ng tao ay binubuo ng mga gene. Dahil ang mga gene ay bumubuo ng isang medyo maliit na proporsyon ng genome ng tao, ang isang malaking halaga ng DNA ay nananatiling hindi natukoy.

kanin. 16. Scheme ng istraktura ng gene sa eukaryotes - ang imahe ay pinalaki
Mula sa bawat gene, isang immature, o pre-RNA, ang unang na-synthesize, na naglalaman ng parehong mga intron at exon.
Pagkatapos nito, ang proseso ng splicing ay nagaganap, bilang isang resulta kung saan ang mga rehiyon ng intron ay excised, at isang mature na mRNA ay nabuo, kung saan ang isang protina ay maaaring synthesize.

kanin. 20. Alternatibong proseso ng splicing - ang imahe ay pinalaki
Ang ganitong organisasyon ng mga gene ay nagbibigay-daan, halimbawa, kapag ang iba't ibang anyo ng isang protina ay maaaring synthesize mula sa isang gene, dahil sa ang katunayan na ang mga exon ay maaaring pinagsama sa iba't ibang mga pagkakasunud-sunod sa panahon ng splicing.

kanin. 21. Mga pagkakaiba sa istruktura ng mga gene ng prokaryotes at eukaryotes - ang imahe ay pinalaki
MGA MUTASYON AT MUTAGENESIS
mutation tinatawag na isang patuloy na pagbabago sa genotype, iyon ay, isang pagbabago sa pagkakasunud-sunod ng nucleotide.
Ang prosesong humahantong sa mutation ay tinatawag mutagenesis, at ang organismo lahat na ang mga selula ay nagdadala ng parehong mutation mutant.
teorya ng mutation ay unang binuo ni Hugh de Vries noong 1903. Kasama sa modernong bersyon nito ang mga sumusunod na probisyon:
1. Ang mga mutasyon ay nangyayari bigla, biglaan.
2. Ang mga mutasyon ay ipinapasa mula sa henerasyon hanggang sa henerasyon.
3. Ang mga mutasyon ay maaaring maging kapaki-pakinabang, nakakapinsala o neutral, nangingibabaw o recessive.
4. Ang posibilidad ng pag-detect ng mga mutasyon ay depende sa bilang ng mga indibidwal na pinag-aralan.
5. Ang mga katulad na mutasyon ay maaaring mangyari nang paulit-ulit.
6. Ang mga mutasyon ay hindi nakadirekta.
Ang mga mutasyon ay maaaring mangyari sa ilalim ng impluwensya ng iba't ibang mga kadahilanan. Matukoy ang pagkakaiba sa pagitan ng mga mutasyon na dulot ng mutagenic mga epekto: pisikal (hal. ultraviolet o radiation), kemikal (hal. colchicine o reactive oxygen species) at biological (hal. mga virus). Ang mga mutasyon ay maaari ding sanhi mga error sa pagtitiklop.
Depende sa mga kondisyon para sa hitsura ng mutations ay nahahati sa kusang-loob- iyon ay, mga mutasyon na lumitaw sa ilalim ng normal na mga kondisyon, at sapilitan- iyon ay, mga mutasyon na lumitaw sa ilalim ng mga espesyal na kondisyon.
Ang mga mutasyon ay maaaring mangyari hindi lamang sa nuclear DNA, kundi pati na rin, halimbawa, sa DNA ng mitochondria o plastids. Alinsunod dito, maaari nating makilala nuklear at cytoplasmic mutasyon.
Bilang resulta ng paglitaw ng mga mutasyon, madalas na lumitaw ang mga bagong alleles. Kung na-override ng mutant allele ang normal na allele, tinatawag ang mutation nangingibabaw. Kung pinipigilan ng normal na allele ang mutated, tinatawag ang mutation recessive. Karamihan sa mga mutasyon na nagdudulot ng mga bagong alleles ay resessive.
Ang mga mutasyon ay nakikilala sa pamamagitan ng epekto adaptive, na humahantong sa isang pagtaas sa kakayahang umangkop ng organismo sa kapaligiran, neutral na hindi nakakaapekto sa kaligtasan ng buhay nakakapinsala na nagpapababa sa kakayahang umangkop ng mga organismo sa mga kondisyon sa kapaligiran at nakamamatay humahantong sa pagkamatay ng organismo sa mga unang yugto ng pag-unlad.
Ayon sa mga kahihinatnan, ang mga mutasyon ay nakikilala, na humahantong sa pagkawala ng function ng protina, mutations na humahantong sa paglitaw may bagong function ang protina, pati na rin ang mga mutasyon na baguhin ang dosis ng isang gene, at, nang naaayon, ang dosis ng protina na na-synthesize mula dito.
Ang isang mutation ay maaaring mangyari sa anumang cell ng katawan. Kung ang isang mutation ay nangyari sa isang germ cell, ito ay tinatawag na germinal(germinal, o generative). Ang ganitong mga mutasyon ay hindi lilitaw sa organismo kung saan sila lumitaw, ngunit humahantong sa hitsura ng mga mutant sa mga supling at minana, kaya mahalaga ang mga ito para sa genetika at ebolusyon. Kung ang mutation ay nangyayari sa anumang iba pang cell, ito ay tinatawag na somatic. Ang gayong mutation ay maaaring magpakita mismo sa ilang lawak sa organismo kung saan ito lumitaw, halimbawa, ay humantong sa pagbuo ng mga kanser na tumor. Gayunpaman, ang gayong mutation ay hindi minana at hindi nakakaapekto sa mga supling.
Maaaring makaapekto ang mga mutasyon sa mga bahagi ng genome na may iba't ibang laki. Maglaan genetic, chromosomal at genomic mutasyon.
Mga mutation ng gene
Ang mga mutasyon na nangyayari sa isang sukat na mas maliit sa isang gene ay tinatawag genetic, o may tuldok (dotted). Ang ganitong mga mutasyon ay humantong sa isang pagbabago sa isa o higit pang mga nucleotide sa pagkakasunud-sunod. Kasama sa mga mutation ng genepagpapalit, na humahantong sa pagpapalit ng isang nucleotide ng isa pa,mga pagtanggal na humahantong sa pagkawala ng isa sa mga nucleotides,mga pagsingit, na humahantong sa pagdaragdag ng dagdag na nucleotide sa sequence.

kanin. 23. Gene (point) mutations
Ayon sa mekanismo ng pagkilos sa protina, ang mga mutation ng gene ay nahahati sa:magkasingkahulugan, na (bilang resulta ng pagkabulok ng genetic code) ay hindi humantong sa pagbabago sa komposisyon ng amino acid ng produktong protina,missense mutations, na humahantong sa pagpapalit ng isang amino acid ng isa pa at maaaring makaapekto sa istraktura ng synthesized na protina, bagaman kadalasan ay hindi gaanong mahalaga,walang kapararakan mutations, na humahantong sa pagpapalit ng coding codon na may stop codon,mutations na humahantong sa disorder ng splicing:

kanin. 24. Mutation scheme
Gayundin, ayon sa mekanismo ng pagkilos sa protina, ang mga mutasyon ay nakahiwalay, na humahantong sa paglilipat ng frame mga pagbabasa tulad ng pagsingit at pagtanggal. Ang ganitong mga mutasyon, tulad ng mga walang katuturang mutasyon, bagaman nangyayari ang mga ito sa isang punto sa gene, ay kadalasang nakakaapekto sa buong istraktura ng protina, na maaaring humantong sa isang kumpletong pagbabago sa istraktura nito. kapag ang isang segment ng isang chromosome ay umiikot ng 180 degrees kanin. 28. Pagsasalin
kapag ang isang segment ng isang chromosome ay umiikot ng 180 degrees kanin. 28. Pagsasalin
kanin. 29. Chromosome bago at pagkatapos ng pagdoble
Genomic mutations
Sa wakas, genomic mutations nakakaapekto sa buong genome, iyon ay, ang bilang ng mga kromosom ay nagbabago. Ang polyploidy ay nakikilala - isang pagtaas sa ploidy ng cell, at aneuploidy, iyon ay, isang pagbabago sa bilang ng mga chromosome, halimbawa, trisomy (ang pagkakaroon ng karagdagang homologue sa isa sa mga chromosome) at monosomy (ang kawalan ng isang homolog sa chromosome).
Video na nauugnay sa DNA
DNA REPLICATION, RNA CODING, PROTEIN SYNTHESIS
(Kung hindi ipinapakita ang video, available ito sa
Ayon sa istrukturang kemikal ng DNA ( Deoxyribonucleic acid) ay isang biopolymer, na ang mga monomer ay nucleotides. Ibig sabihin, ang DNA ay polynucleotide. Bukod dito, ang molekula ng DNA ay karaniwang binubuo ng dalawang kadena na baluktot na may kaugnayan sa isa't isa kasama ng isang helical na linya (kadalasang tinatawag na "spiral twisted") at magkakaugnay ng mga bono ng hydrogen.
Ang mga kadena ay maaaring baluktot pareho sa kaliwa at sa kanan (madalas) na gilid.
Ang ilang mga virus ay may single strand DNA.
Ang bawat DNA nucleotide ay binubuo ng 1) isang nitrogenous base, 2) deoxyribose, 3) isang residue ng phosphoric acid.
Dobleng kanang kamay na DNA helix
Ang DNA ay naglalaman ng mga sumusunod: adenine, guanine, thymine at cytosine. Adenine at guanine ay mga purine, at thymine at cytosine - sa pyrimidines. Minsan ang DNA ay naglalaman ng uracil, na karaniwang katangian ng RNA, kung saan pinapalitan nito ang thymine.
Ang mga nitrogenous base ng isang chain ng DNA molecule ay konektado sa nitrogenous base ng isa pa ayon sa prinsipyo ng complementarity: adenine lamang sa thymine (bumubuo sila ng dalawang hydrogen bond sa isa't isa), at guanine lamang sa cytosine (tatlong bono) .
Ang nitrogenous base sa nucleotide mismo ay konektado sa unang carbon atom ng cyclic form deoxyribose, na isang pentose (carbohydrate na may limang carbon atoms). Ang bono ay covalent, glycosidic (C-N). Hindi tulad ng ribose, ang deoxyribose ay kulang sa isa sa mga hydroxyl group nito. Ang singsing ng deoxyribose ay nabuo ng apat na carbon atoms at isang oxygen atom. Ang ikalimang carbon atom ay nasa labas ng singsing at konektado sa pamamagitan ng isang oxygen atom sa isang phosphoric acid residue. Gayundin, sa pamamagitan ng oxygen atom sa ikatlong carbon atom, ang phosphoric acid residue ng kalapit na nucleotide ay nakakabit.
Kaya, sa isang strand ng DNA, ang mga katabing nucleotide ay magkakaugnay mga covalent bond sa pagitan ng deoxyribose at phosphoric acid (phosphodiester bond). Ang isang phosphate-deoxyribose backbone ay nabuo. Patayo dito, patungo sa isa pang strand ng DNA, ang mga nitrogenous na base ay nakadirekta, na konektado sa mga base ng pangalawang strand sa pamamagitan ng mga bono ng hydrogen.
Ang istraktura ng DNA ay tulad na ang mga gulugod ng mga kadena na konektado ng mga bono ng hydrogen ay nakadirekta sa iba't ibang direksyon (sinasabi nilang "multidirectional", "antiparallel"). Sa gilid kung saan ang isa ay nagtatapos sa phosphoric acid na konektado sa ikalimang carbon atom ng deoxyribose, ang isa ay nagtatapos sa isang "libre" na ikatlong carbon atom. Iyon ay, ang balangkas ng isang kadena ay nakabaligtad, kumbaga, may kaugnayan sa isa pa. Kaya, sa istraktura ng mga kadena ng DNA, 5 "mga dulo at 3" na mga dulo ay nakikilala.
Kapag kinokopya (pagdodoble) ang DNA, ang synthesis ng mga bagong kadena ay palaging nagpapatuloy mula sa kanilang ika-5 dulo hanggang sa pangatlo, dahil ang mga bagong nucleotide ay maaari lamang ikabit sa libreng ikatlong dulo.
Sa huli (hindi direkta sa pamamagitan ng RNA), bawat magkakasunod na tatlong nucleotide sa DNA chain code para sa isang amino acid ng protina.
Ang pagkatuklas ng istraktura ng molekula ng DNA ay naganap noong 1953 salamat sa gawain ni F. Crick at D. Watson (na pinadali din ng unang gawain ng iba pang mga siyentipiko). Bagama't paano Kemikal na sangkap Ang DNA ay kilala mula noong ika-19 na siglo. Noong 1940s, naging malinaw na ang DNA ang carrier ng genetic information.
Ang double helix ay itinuturing na pangalawang istraktura ng molekula ng DNA. Sa mga eukaryotic cell, ang karamihan ng DNA ay matatagpuan sa mga chromosome, kung saan ito ay nauugnay sa mga protina at iba pang mga sangkap, at sumasailalim din sa mas siksik na packaging.
Deoxyribonucleic acid o DNA ay ang carrier ng genetic information. Karamihan sa DNA sa mga selula ay matatagpuan sa nucleus. Ito ang pangunahing bahagi ng mga chromosome. Sa eukaryotes, ang DNA ay matatagpuan din sa mitochondria at plastids. Binubuo ang DNA ng mga mononucleotide na covalently linked sa isa't isa, na kumakatawan sa isang mahabang polymer na walang sanga. Ang mga mononucleotide na bumubuo sa DNA ay binubuo ng deoxyribose, isa sa 4 na nitrogenous base (adenine, guanine, cytosine at thymine), at isang residue ng phosphoric acid. Ang bilang ng mga mononucleotide na ito ay napakalaki. Halimbawa, sa mga prokaryotic cell na naglalaman ng isang solong chromosome, ang DNA ay isang solong macromolecule na may molekular na timbang na higit sa 2 x 10 9 .
Ang mga mononucleotide ng isang strand ng DNA ay konektado sa serye sa bawat isa dahil sa pagbuo mga covalent phosphodiester bond sa pagitan ng deoxyribose OH group ng isang mononucleotide at ang phosphoric acid residue ng isa pa. Sa isang gilid ng nabuong backbone ng isang strand ng DNA ay mga nitrogenous base. Maaari silang ihambing sa apat na magkakaibang mga kuwintas na inilagay sa isang thread, dahil. ang mga ito ay, kumbaga, na nakasabit sa isang chain ng asukal-pospeyt.
Lumilitaw ang tanong, paano mai-encode ng mahabang polynucleotide chain na ito ang programa para sa pagbuo ng isang cell o kahit isang buong organismo? Ang sagot sa tanong na ito ay maaaring makuha sa pamamagitan ng pag-unawa kung paano nabuo ang spatial na istraktura ng DNA. Ang istraktura ng molekulang ito ay natukoy at inilarawan nina J. Watson at F. Crick noong 1953.
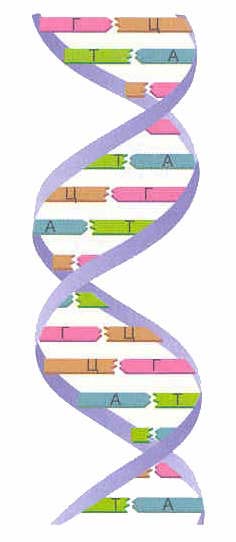
Ang mga molekula ng DNA ay dalawang hibla na kahanay sa isa't isa at anyo kanang kamay na helix
. Ang lapad ng spiral na ito ay humigit-kumulang 2 nm, ngunit ang haba nito ay maaaring umabot sa daan-daang libong nanometer. Iminungkahi nina Watson at Crick ang isang modelo ng DNA, ayon sa kung saan ang lahat ng mga base ng DNA ay matatagpuan sa loob ng helix, ang sugar-phosphate backbone ay nasa labas. Kaya, ang mga base ng isang kadena ay mas malapit hangga't maaari sa mga base ng isa pa,
kaya nabuo ang mga bono ng hydrogen sa pagitan nila. Ang istraktura ng DNA helix ay tulad na ang polynucleotide chain na bumubuo dito ay maaari lamang paghiwalayin pagkatapos na ito ay matanggal.
Dahil sa maximum na kalapitan ng dalawang strand ng DNA, ang komposisyon nito ay naglalaman ng parehong dami ng nitrogenous base ng isang uri (adenine at guanine) at nitrogenous base ng isa pang uri (thymine at cytosine), ibig sabihin, valid ang formula: A+G=T+C. Ito ay dahil sa laki ng mga nitrogenous base, ibig sabihin, ang haba ng mga istruktura na nabuo dahil sa paglitaw ng isang hydrogen bond sa pagitan ng mga pares ng adenine-thymine at guanine-cytosine ay humigit-kumulang 1.1 nm. Ang kabuuang sukat ng mga pares na ito ay tumutugma sa mga sukat ng panloob na bahagi ng DNA helix. Upang bumuo ng isang spiral mag-asawang C-T ay masyadong maliit mag-asawang A-G, sa kabaligtaran, ay masyadong malaki. Iyon ay, ang nitrogenous base ng unang strand ng DNA, ay tumutukoy sa base na matatagpuan sa parehong lugar ng iba pang strand ng DNA. Ang mahigpit na pagsusulatan ng mga nucleotide na matatagpuan sa isang molekula ng DNA sa mga ipinares na kadena parallel sa bawat isa ay tinatawag complementarity (opsyonal). eksaktong pagpaparami o pagtitiklop Ang genetic na impormasyon ay posible nang tumpak dahil sa tampok na ito ng molekula ng DNA.
Sa DNA, ang biological na impormasyon ay naitala sa paraang ito ay eksaktong makopya at mailipat sa mga descendant na selula. Bago ang cell division, pagtitiklop (pagdodoble sa sarili ) DNA. Dahil ang bawat strand ay naglalaman ng isang pantulong na nucleotide sequence sa partner strand, sila ay aktwal na nagdadala ng parehong genetic na impormasyon. Kung paghihiwalayin mo ang mga strand at gagamitin ang bawat isa sa kanila bilang template (matrix) upang bumuo ng pangalawang strand, makakakuha ka ng dalawang bagong magkaparehong DNA strand. Ito ay kung paano nadoble ang DNA sa isang cell.


