Едноставна математика на теоремата на Бајс. Решавање задачи со формула за вкупна веројатност и Теорија на вкупна веројатност со формула на Бејс
Нека се знаат нивните веројатности и соодветните условни веројатности. Тогаш веројатноста да се случи настанот е:
Оваа формула се нарекува формули за вкупна веројатност. Во учебниците се формулира со теорема чијшто доказ е елементарен: според алгебра на настани, (се случи настан и илисе случил настан иоткако дојде настанот илисе случил настан иоткако дојде настанот или …. илисе случил настан иследеше настан). Од хипотезите ![]() се некомпатибилни, а настанот е зависен, тогаш според Теорема за собирање за веројатностите на некомпатибилни настани (првиот чекор)и теоремата за множење на веројатностите на зависните настани (втор чекор):
се некомпатибилни, а настанот е зависен, тогаш според Теорема за собирање за веројатностите на некомпатибилни настани (првиот чекор)и теоремата за множење на веројатностите на зависните настани (втор чекор):

Веројатно, многумина ја предвидуваат содржината на првиот пример =)
Каде и да плукаш - секаде урната:
Задача 1
Има три идентични урни. Првата урна содржи 4 бели и 7 црни топки, втората урна содржи само бели топки, а третата урна содржи само црни топки. Една урна се избира по случаен избор и од неа по случаен избор се извлекува топка. Која е веројатноста оваа топка да е црна?
Решение: разгледајте го настанот - ќе се извлече црна топка од случајно избрана урна. Овој настан може или не може да се појави како резултат на една од следните хипотези:
– ќе се избере првата урна;
– ќе се избере 2-та урна;
– ќе се избере третата урна.
Бидејќи урната е избрана по случаен избор, изборот на која било од трите урни подеднакво можно, Следствено: ![]()
Забележете дека горенаведените хипотези се формираат целосна група на настани, односно според условот, црна топка може да се појави само од овие урни, а на пример, да не лета од маса за билијард. Ајде да направиме едноставна средна проверка: ![]() Добро, да продолжиме понатаму:
Добро, да продолжиме понатаму:
Првата урна содржи 4 бели + 7 црни = 11 топчиња, секоја класична дефиниција:
е веројатноста да се нацрта црна топка под условдека ќе биде избрана првата урна.
Втората урна содржи само бели топчиња, па доколку се изберепојавата на црна топка станува невозможно: .
И, конечно, во третата урна има само црни топчиња, што значи дека соодветните условна веројатностекстракција на црната топка ќе биде (настанот е сигурен).
е веројатноста дека црна топка ќе биде извлечена од случајно избрана урна.
Одговори:
Анализираниот пример повторно сугерира колку е важно да се РАЗБИРА СОСТОЈБАТА. Да ги земеме истите проблеми со урните и топките - со нивната надворешна сличност, методите на решавање можат да бидат сосема различни: некаде се бара да се примени само класична дефиниција на веројатност, некаде настани независна, некаде зависни, а некаде зборуваме за хипотези. Во исто време, не постои јасен формален критериум за избор на патека за решение - скоро секогаш треба да размислите за тоа. Како да ги подобрите своите вештини? Решаваме, решаваме и пак решаваме!
Задача 2
Во стрелиштето има 5 различни пушки. Веројатноста за погодување на целта за даден стрелец се соодветно еднакви на 0,5; 0,55; 0,7; 0,75 и 0,4. Која е веројатноста да се погоди целта ако стрелецот испука еден истрел од случајно избрана пушка?
Кратко решение и одговор на крајот од часот.
Во повеќето тематски проблеми, хипотезите, се разбира, не се подеднакво веројатни:
Задача 3
Во пирамидата има 5 пушки, од кои три се опремени со оптички нишан. Веројатноста дека стрелецот ќе ја погоди целта при пукање од пушка со телескопски нишан е 0,95; за пушка без телескопски нишан, оваа веројатност е 0,7. Најдете ја веројатноста дека целта ќе биде погодена ако стрелецот испука еден истрел од пушка земена по случаен избор.
Решение: во овој проблем, бројот на пушки е сосема ист како и во претходниот, но има само две хипотези:
- стрелецот ќе избере пушка со оптички нишан;
- стрелецот ќе избере пушка без телескопски нишан.
Од страна на класична дефиниција на веројатност: ![]() .
.
Контрола:
Размислете за настанот: - стрелецот ја погодува целта со случајно избрана пушка.
По услов: .
Според формулата за вкупна веројатност:
Одговори: 0,85
Во пракса, сосема е прифатлив скратениот начин на дизајнирање задача, со кој исто така сте запознаени:
Решение: според класичната дефиниција: ![]() се веројатностите за избор на пушка со и без оптички нишан, соодветно.
се веројатностите за избор на пушка со и без оптички нишан, соодветно.
По услов, ![]() – веројатности за погодување на целта со соодветните видови пушки.
– веројатности за погодување на целта со соодветните видови пушки.
Според формулата за вкупна веројатност:
е веројатноста дека стрелецот ќе ја погоди целта со случајно избрана пушка.
Одговори: 0,85
Следната задача за независно решение:
Задача 4
Моторот работи во три режими: нормален, принуден и празен од. Во режим на мирување, веројатноста за негово неуспех е 0,05, во нормален режим - 0,1, а во принуден режим - 0,7. 70% од времето моторот работи во нормален режим, а 20% во принуден режим. Која е веројатноста за дефект на моторот за време на работата?
За секој случај, да ве потсетам - за да се добијат веројатностите, процентите мора да се поделат со 100. Бидете многу внимателни! Според моите согледувања, условите на проблемите за формулата на вкупната веројатност често се обидуваат да се помешаат; и конкретно избрав таков пример. Ќе ти кажам една тајна - за малку ќе се збунев и самиот =)
Решение на крајот од часот (формулирано на краток начин)
Проблеми за формулите на Бејс
Материјалот е тесно поврзан со содржината од претходниот став. Нека настанот се случи како резултат на спроведувањето на една од хипотезите ![]() . Како да се одреди веројатноста дека се случила одредена хипотеза?
. Како да се одреди веројатноста дека се случила одредена хипотеза?
Под условтој настан веќе се случи, веројатности на хипотези преценетспоред формулите што го добиле името на англискиот свештеник Томас Бејс:
![]()
![]() - веројатноста дека хипотезата се случила;
- веројатноста дека хипотезата се случила; ![]() - веројатноста дека хипотезата се случила;
- веројатноста дека хипотезата се случила;
…![]() е веројатноста дека хипотезата била вистинита.
е веројатноста дека хипотезата била вистинита.
На прв поглед, се чини како целосен апсурд - зошто повторно да се пресметаат веројатностите на хипотезите, ако тие се веќе познати? Но, всушност постои разлика:
- ова е априори(проценето предтестови) веројатности.
- ова е a posteriori(проценето послетестови) веројатностите на истите хипотези, повторно пресметани во врска со „новооткриените околности“ - земајќи го предвид фактот дека настанот се случи.
Ајде да ја разгледаме оваа разлика со конкретен пример:
Задача 5
Магацинот доби 2 серии производи: првата - 4000 парчиња, втората - 6000 парчиња. Просечниот процент на нестандардни производи во првата серија е 20%, а во втората - 10%. Случајно земен од магацинот, производот се покажа како стандарден. Најдете ја веројатноста дека е: а) од првата серија, б) од втората серија.
Прв дел решенијасе состои во користење на формулата за вкупна веројатност. Со други зборови, пресметките се вршат под претпоставка дека тестот уште не е произведени настан „Производот се покажа како стандарден“додека не дојде.
Да разгледаме две хипотези:
- производ земен по случаен избор ќе биде од првата серија;
- производ земен по случаен избор ќе биде од 2-та серија.
Вкупно: 4000 + 6000 = 10000 артикли на залиха. Според класичната дефиниција:
.
Контрола:
Размислете за зависниот настан: – артикал земен по случаен избор од магацинот ќе бидестандарден.
Во првата серија 100% - 20% = 80% стандардни производи, затоа: ![]() под условдека и припаѓа на првата страна.
под условдека и припаѓа на првата страна.
Слично, во втората серија 100% - 10% = 90% стандардни производи и ![]() е веројатноста случајно избраната ставка во магацинот да биде стандардна ставка под условдека припаѓа на втора страна.
е веројатноста случајно избраната ставка во магацинот да биде стандардна ставка под условдека припаѓа на втора страна.
Според формулата за вкупна веројатност:
е веројатноста дека производот избран по случаен избор од магацинот ќе биде стандарден производ.
Втор дел. Да претпоставиме дека производ земен по случаен избор од магацинот се покажа како стандарден. Оваа фраза е директно напишана во условот и го наведува фактот дека настанот се случи.
Според формулите на Бејс:
а) - веројатноста дека избраниот стандарден производ припаѓа на првата серија;
б) - веројатноста дека избраниот стандарден производ припаѓа на 2-та серија.
По ревалоризацијахипотезите, се разбира, сè уште се формираат целосна група:![]() (испитување;-))
(испитување;-))
Одговори: ![]()
Иван Василевич, кој повторно ја промени професијата и стана директор на фабриката, ќе ни помогне да го разбереме значењето на преоценувањето на хипотезите. Тој знае дека денес првата продавница испратила 4000 артикли во магацинот, а втората продавница - 6000 производи и доаѓа да се увери во тоа. Да претпоставиме дека сите производи се од ист тип и се во ист сад. Секако, Иван Василевич претходно пресметал дека производот што сега ќе го отстрани за верификација најверојатно ќе биде произведен од 1-та работилница и со веројатност од втората. Но, откако избраниот предмет се покажа како стандарден, тој извикува: „Каков кул болт! - попрво беше објавен од 2-та работилница. Така, веројатноста за втората хипотеза е преценета во подобра страна, а веројатноста за првата хипотеза е потценета: . И ова преценување не е неразумно - на крајот на краиштата, 2-та работилница не само што произведе повеќе производи, туку и работи 2 пати подобро!
Велиш, чист субјективизам? Делумно - да, згора на тоа, самиот Бајс толкуваше a posterioriверојатности како ниво на доверба. Сепак, не е сè толку едноставно - постои објективна зрно во бајесовиот пристап. Впрочем, веројатноста дека производот ќе биде стандарден (0,8 и 0,9 за 1-ви и 2-ри продавници, соодветно)ова е прелиминарните(а приори) и среднопроценки. Но, гледајќи филозофски, сè тече, сè се менува, вклучувајќи ги и веројатностите. Сосема е можно тоа во времето на студијатапоуспешна 2-та продавница го зголеми процентот на стандардни производи (и/или првата продавница намалена), и ако проверите повеќе или сите 10 илјади артикли на залиха, тогаш преценетите вредности ќе бидат многу поблиску до вистината.
Патем, ако Иван Василевич извлече нестандарден дел, тогаш обратно - тој сè помалку ќе се „сомнева“ во првата продавница - втората. Ви препорачувам да го проверите сами:
Задача 6
Магацинот доби 2 серии производи: првата - 4000 парчиња, втората - 6000 парчиња. Просечниот процент на нестандардни производи во првата серија е 20%, во втората - 10%. Се покажа дека е земен производ по случаен избор од магацинот нестандарден. Најдете ја веројатноста дека е: а) од првата серија, б) од втората серија.
Условот ќе се разликува со две букви, кои ги истакнав со задебелени букви. Проблемот може да се реши од нула, или можете да ги користите резултатите од претходните пресметки. Во примерокот што го имам целосно решение, но за да нема формално преклопување со Задача бр. 5, настанот „Производ земен по случаен избор од магацинот ќе биде нестандарден“означени со .
Бајесовата шема за повторна проценка на веројатностите се наоѓа насекаде, а исто така активно се искористува од разни видови измамници. Размислете за акционерско друштво со три букви што стана познато име, кое привлекува депозити од населението, демек ги инвестира некаде, редовно плаќа дивиденди итн. Што се случува? Ден по ден, месец по месец поминува, а се повеќе и повеќе нови факти, пренесени преку рекламирање и усно на уста, само го зголемуваат нивото на доверба во финансиската пирамида (постериорна баесова реевалуација поради минати настани!). Односно, во очите на штедачите, постои постојан пораст на веројатноста дека „Ова е сериозна канцеларија“; додека веројатноста за спротивната хипотеза („ова се редовни измамници“), се разбира, се намалува и намалува. Останатото, мислам, е јасно. Вреди да се одбележи дека заработената репутација им дава време на организаторите успешно да се сокријат од Иван Василевич, кој остана не само без серија завртки, туку и без панталони.
На не помалку интересните примери ќе се вратиме малку подоцна, но засега, можеби најчестиот случај со три хипотези е следен:
Задача 7
Електричните светилки се произведуваат во три фабрики. Првата фабрика произведува 30% од вкупниот број светилки, втората - 55%, а третата - остатокот. Производите од првата фабрика содржат 1% неисправни светилки, 2-та - 1,5%, третата - 2%. Продавницата добива производи од сите три фабрики. Светилката што ја купив беше неисправна. Која е веројатноста дека е произведен од фабриката 2?
Имајте на ум дека во проблеми на Bayes формули во состојба нужнонекои што се случинастан, во овој случај, купување на светилка.
Настаните се зголемија и решениепопогодно е да се организира во „брз“ стил.
Алгоритмот е сосема ист: на првиот чекор ја наоѓаме веројатноста дека купената светилка ќе ќе биденеисправни.
Користејќи ги првичните податоци, ние ги преведуваме процентите во веројатности:
се веројатностите дека светилката е произведена од 1-та, 2-та и 3-та фабрика, соодветно.
Контрола:
Слично: - веројатностите за производство на неисправна светилка за соодветните фабрики.
Според формулата за вкупна веројатност:
- веројатноста дека купената светилка ќе биде неисправна.
Чекор два. Нека купената светилка е неисправна (настанот се случил)
Според формулата на Бејс: ![]() - веројатноста дека купената неисправна светилка е произведена од втората фабрика
- веројатноста дека купената неисправна светилка е произведена од втората фабрика
Одговори:
Зошто првичната веројатност за 2-та хипотеза се зголеми по повторното оценување? На крајот на краиштата, втората фабрика произведува светилки со просечен квалитет (првата е подобра, третата е полоша). Па зошто се зголеми a posterioriверојатноста дека неисправната светилка е од 2-ра фабрика? Ова веќе не се должи на „репутацијата“, туку на големината. Бидејќи фабриката бр. 2 произведе најголем број светилки, тие ја обвинуваат (барем субјективно): „Најверојатно, оваа неисправна светилка е од таму“.
Интересно е да се забележи дека веројатностите на 1-та и 3-та хипотеза беа преценети во очекуваните насоки и станаа еднакви:
Контрола: ![]() , што требаше да се потврди.
, што требаше да се потврди.
Патем, за потценети и преценети:
Задача 8
AT студентска група 3 лица имаат високо ниво на обука, 19 лица имаат просечно ниво и 3 лица имаат ниско ниво. Веројатности успешна испоракаиспит за овие студенти се соодветно еднакви на: 0,95; 0,7 и 0,4. Се знае дека некој студент го положил испитот. Која е веројатноста дека:
а) тој беше многу добро подготвен;
б) беше умерено подготвен;
в) беше слабо подготвен.
Вршете пресметки и анализирајте ги резултатите од реевалуацијата на хипотезите.
Задачата е блиска до реалноста и е особено веродостојна за група вонредни студенти, каде што наставникот практично не ги знае способностите на овој или оној ученик. Во овој случај, резултатот може да предизвика прилично неочекувани последици. (посебно за испити во 1 семестар). Ако недоволно подготвен ученик има среќа да добие билет, тогаш наставникот веројатно ќе го смета за добар ученик или дури и за силен ученик, што ќе донесе добри дивиденди во иднина (се разбира, треба да ја „подигнете лентата“ и да го одржите вашиот имиџ). Ако ученикот учел, набивал, повторувал 7 дена и 7 ноќи, но едноставно немал среќа, тогаш понатамошните настани може да се развијат на најлош можен начин - со бројни повторувања и балансирање на работ на заминување.
Непотребно е да се каже дека угледот е најважниот капитал, не случајно многу корпорации ги носат имињата и презимињата на нивните татковци основачи, кои го воделе бизнисот пред 100-200 години и станале познати по својата беспрекорна репутација.
Да, бајзов пристап до одредена границасубјективно, но ... така функционира животот!
Ајде да го консолидираме материјалот со последен индустриски пример, во кој ќе зборувам за техничките суптилности на решението што сè уште не се сретнале:
Задача 9
Три работилници на фабриката произведуваат делови од ист тип, кои се склопуваат во заеднички контејнер за склопување. Познато е дека првата продавница произведува 2 пати повеќе делови од втората продавница, а 4 пати повеќе од третата продавница. Во првата работилница дефектот е 12%, во втората - 8%, во третата - 4%. За контрола се зема еден дел од контејнерот. Која е веројатноста да биде неисправна? Колкава е веројатноста дека извадениот неисправен дел е произведен од 3-та продавница?
Таки Иван Василевич е повторно на коњ =) Филмот мора да има среќен крај =)
Решение: за разлика од задачите бр. 5-8, овде е експлицитно поставено прашање, кое се решава со помош на формулата за вкупна веројатност. Но, од друга страна, состојбата е малку „шифрирана“, а училишната вештина да ги составиме наједноставните равенки ќе ни помогне да го решиме овој ребус. За "x" погодно е да се земе најмалата вредност:
Нека биде уделот на делови произведени од третата работилница.
Според условот, првата работилница произведува 4 пати повеќе од третата, така што учеството на првата работилница е .
Дополнително, првата работилница произведува 2 пати повеќе производи од втората работилница, што значи дека уделот на втората: .
Да ја направиме и решиме равенката:
Така: - веројатностите дека делот изваден од контејнерот е ослободен од 1-та, 2-та и 3-та работилница, соодветно.
Контрола:. Покрај тоа, нема да биде излишно да се погледне повторно на фразата „Познато е дека првата работилница произведува производи 2 пати повеќе од втората и 4 пати повеќе од третата работилница“и уверете се дека добиените веројатности навистина одговараат на оваа состојба.
За „Х“ првично беше можно да се земе делот од 1-ви или дел од 2-та продавница - веројатностите ќе излезат исти. Но, вака или онака, најтешкиот дел е поминат, а решението е на вистинскиот пат:
Од состојбата наоѓаме:
- веројатноста за изработка на неисправен дел за соодветните работилници.
Според формулата за вкупна веројатност: ![]() е веројатноста дека делот по случаен избор извлечен од контејнерот ќе биде нестандарден.
е веројатноста дека делот по случаен избор извлечен од контејнерот ќе биде нестандарден.
Прашање второ: колкава е веројатноста дека извадениот неисправен дел е произведен од 3-та продавница? Ова прашање претпоставува дека делот е веќе отстранет и е утврдено дека е неисправен. Ја реевалуираме хипотезата користејќи ја формулата на Бејс:  е посакуваната веројатност. Сосема очекувано - на крајот на краиштата, третата работилница произведува не само најмал дел од делови, туку и води по квалитет!
е посакуваната веројатност. Сосема очекувано - на крајот на краиштата, третата работилница произведува не само најмал дел од делови, туку и води по квалитет!
Во овој случај, морав поедностави ја дропката од четири ката, што во проблемите на формулите на Бејс треба да се прави доста често. Но, за оваа лекција, некако случајно собрав примери во кои може да се направат многу пресметки без обични дропки.
Бидејќи нема точки „а“ и „биди“ во условот, подобро е да го дадете одговорот со текстуални коментари:
Одговори: ![]() - веројатноста дека делот изваден од контејнерот ќе биде неисправен; - веројатноста дека извлечениот неисправен дел е отпуштен од 3-та работилница.
- веројатноста дека делот изваден од контејнерот ќе биде неисправен; - веројатноста дека извлечениот неисправен дел е отпуштен од 3-та работилница.
Како што можете да видите, проблемите со формулата за вкупна веројатност и формулите на Бејс се прилично едноставни и, веројатно, поради оваа причина тие толку често се обидуваат да ја комплицираат состојбата, која веќе ја споменав на почетокот на статијата.
Дополнителни примери се во датотеката со готови решенија за F.P.V. и формулите на Бејс, покрај тоа, веројатно има и такви кои сакаат подлабоко да се запознаат со оваа тема во други извори. А темата е навистина многу интересна - што вреди сама Бајс парадокс, што го оправдува секојдневниот совет дека ако на човек му е дијагностицирана ретка болест, тогаш има смисла да спроведе втор, па дури и два повторени независни прегледи. Се чини дека тие го прават тоа исклучиво од очај ... - но не! Но, да не зборуваме за тажни работи.
е веројатноста дека по случаен избор избран студент ќе го положи испитот.
Нека студентот го положи испитот. Според формулите на Бејс:
а)
б)
во)
Испитување:
Одговори : Формула на Бејс:
Веројатностите P(H i) од хипотезите H i се нарекуваат априори веројатности - веројатности пред експериментите.
Веројатните P(A/H i) се нарекуваат a posteriori веројатности - веројатностите на хипотезите H i рафинирани како резултат на експериментот.
Пример #1. Уредот може да се состави од висококвалитетни делови и од делови со обичен квалитет. Околу 40% од уредите се составени од висококвалитетни делови. Ако уредот е составен од висококвалитетни делови, неговата сигурност (веројатност за работа без дефект) со текот на времето t е 0,95; ако од делови со обичен квалитет - неговата доверливост е 0,7. Уредот беше тестиран за време t и работеше беспрекорно. Најдете ја веројатноста дека е склопен од висококвалитетни делови.
Решение.Можни се две хипотези: H 1 - уредот е составен од висококвалитетни делови; H 2 - уредот е составен од делови со обичен квалитет. Веројатноста на овие хипотези пред експериментот: P(H 1) = 0,4, P(H 2) = 0,6. Како резултат на експериментот, беше забележан настан А - уредот работеше беспрекорно за време т. Условните веројатности за овој настан според хипотезите H 1 и H 2 се: P(A|H 1) = 0,95; P(A|H 2) = 0,7. Користејќи ја формулата (12), ја наоѓаме веројатноста за хипотезата H 1 по експериментот:
![]()
Пример #2. Двајца стрелци независно пукаат во иста цел, секој испука по еден истрел. Веројатноста за погодување на целта за првиот стрелец е 0,8, за вториот 0,4. По пукањето, во целта била пронајдена една дупка. Под претпоставка дека двајца стрелци не можат да погодат иста точка, пронајдете ја веројатноста првиот стрелец да ја погоди целта.
Решение.Нека настанот А е една дупка пронајдена во целта по пукањето. Пред почетокот на пукањето, можни се хипотези:
H 1 - ниту првиот ниту вториот стрелец нема да погоди, веројатноста за оваа хипотеза: P(H 1) = 0,2 0,6 = 0,12.
H 2 - двајцата стрелци ќе погодат, P(H 2) = 0,8 0,4 = 0,32.
H 3 - првиот стрелец ќе погоди, а вториот нема да погоди, P(H 3) = 0,8 0,6 = 0,48.
H 4 - првиот стрелец нема да погоди, но вториот ќе погоди, P (H 4) = 0,2 0,4 = 0,08.
Условните веројатности на настанот А според овие хипотези се:
По искуството, хипотезите H 1 и H 2 стануваат невозможни, а веројатностите на хипотезите H 3 и H 4
ќе бидат еднакви:
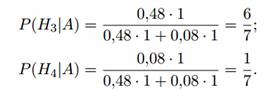
Значи, најверојатно целта е погодена од првиот стрелец.
Пример #3. Во монтажната продавница, електричен мотор е поврзан со уредот. Електричните мотори се испорачуваат од три производители. Во магацинот има соодветно 19,6 и 11 електромотори од наведените погони, кои можат да работат без дефект до крајот на гарантниот рок, соодветно, со веројатности од 0,85, 0,76 и 0,71. Работникот по случаен избор зема еден мотор и го монтира на уредот. Најдете ја веројатноста дека електричниот мотор, монтиран и без дефект до крајот на гарантниот период, бил испорачан од првиот, вториот или третиот производител, соодветно.
Решение.Првиот тест е изборот на електричниот мотор, вториот е работата на електричниот мотор за време на гарантниот период. Размислете за следните настани:
А - електромоторот работи беспрекорно до крајот на гарантниот рок;
H 1 - монтерот ќе го земе моторот од производите на првата фабрика;
H 2 - монтерот ќе го земе моторот од производите на втората фабрика;
H 3 - монтерот ќе го земе моторот од производите на третата фабрика.
Веројатноста за настанот А се пресметува со формулата за вкупна веројатност:
Условните веројатности се наведени во изјавата за проблемот:
Ајде да ги најдеме веројатностите
Користејќи ги формулите на Бејс (12), ги пресметуваме условните веројатности на хипотезите H i:

Пример #4. Веројатноста за време на работата на системот, кој се состои од три елементи, да откажат елементите со броеви 1, 2 и 3, се поврзани како 3: 2: 5. Веројатноста за откривање на дефекти на овие елементи се 0,95, соодветно; 0,9 и 0,6.
б) Во услови на оваа задача, беше откриен дефект за време на работата на системот. Кој елемент има најголема веројатност да не успее?
Решение.
Нека А е неуспешен настан. Да воведеме систем на хипотези H1 - неуспех на првиот елемент, H2 - неуспех на вториот елемент, H3 - неуспех на третиот елемент.
Ги наоѓаме веројатностите на хипотезите:
P(H1) = 3/(3+2+5) = 0,3
P(H2) = 2/(3+2+5) = 0,2
P(H3) = 5/(3+2+5) = 0,5
Според состојбата на проблемот, условните веројатности на настанот А се:
P(A|H1) = 0,95, P(A|H2) = 0,9, P(A|H3) = 0,6
а) Најдете ја веројатноста за откривање дефект во системот.
P(A) = P(H1)*P(A|H1) + P(H2)*P(A|H2) + P(H3)*P(A|H3) = 0,3*0,95 + 0,2*0,9 + 0,5 *0,6 = 0,765
б) Во услови на оваа задача, беше откриен дефект за време на работата на системот. Кој елемент има најголема веројатност да не успее?
P1 = P(H1)*P(A|H1)/ P(A) = 0,3*0,95 / 0,765 = 0,373
P2 = P(H2)*P(A|H2)/ P(A) = 0,2*0,9 / 0,765 = 0,235
P3 = P(H3)*P(A|H3)/ P(A) = 0,5*0,6 / 0,765 = 0,392
Максималната веројатност на третиот елемент.
Кој е Бејс? А каква врска има тоа со менаџментот? – може да биде проследено со прилично фер прашање. Засега, земете го мојот збор: ова е многу важно! .. и интересно (барем за мене).
Во која парадигма работат повеќето менаџери: ако набљудувам нешто, какви заклучоци можам да извлечам од тоа? Што учи Бајс: што всушност мора да биде за да го набљудувам ова нешто? Така се развиваат сите науки, а тој пишува за ова (цитирам од памет): човек кој нема теорија во главата ќе бега од една до друга идеја под влијание на разни настани (набљудувања). Не за џабе велат: нема ништо попрактично од добра теорија.
Пример од пракса. Мојот подреден прави грешка, а мојот колега (раководител на друг оддел) вели дека би било неопходно да се изврши раководно влијание врз несовесниот вработен (со други зборови, казнување / карање). И знам дека овој вработен прави 4-5 илјади исти операции месечно и за ова време не прави повеќе од 10 грешки. Ја чувствувате разликата во парадигмата? Мојот колега реагира на набљудување, а јас априори имам сознанија дека некој вработен прави одреден број грешки, па друга не влијаела на ова знаење... Сега, ако на крајот на месецот се покаже дека има, за пример, 15 такви грешки! .. Ова веќе ќе стане причина да се истражат причините за непочитување на стандардите.
Убедени сте во важноста на Бајесовиот пристап? Заинтригиран? Се надевам". И сега мува во маст. За жал, бајзиските идеи ретко се даваат на прв пат. Јас, искрено, немав среќа, бидејќи со овие идеи се запознав преку популарна литература, откако ја прочитав, останаа многу прашања. Кога планирав да напишам белешка, собрав сè што претходно го истакнав според Бајс, а исто така проучував што пишуваат на Интернет. Ви ја претставувам мојата најдобра претпоставка за темата. Вовед во Бајесова веројатност.
Изведување на теорема на Бајс
Размислете за следниов експеримент: ние именуваме кој било број што лежи на сегментот и поправаме кога овој број е, на пример, помеѓу 0,1 и 0,4 (сл. 1а). Веројатноста за овој настан е еднаква на односот на должината на сегментот со вкупната должина на сегментот, под услов појавата на броеви на сегментот изедначена. Математички, ова може да се напише стр(0,1 <= x <= 0,4) = 0,3, или кратко Р(X) = 0,3, каде Р- веројатност, Xе случајна променлива во опсегот, Xе случајна променлива во опсегот. Тоа е, веројатноста за погодување на сегментот е 30%.

Ориз. 1. Графичко толкување на веројатностите
Сега разгледајте го квадратот x (сл. 1б). Да речеме дека треба да именуваме парови броеви ( x, y), од кои секоја е поголема од нула и помала од една. Веројатноста дека x(првиот број) ќе биде во рамките на сегментот (сина област 1), еднаков на односот на површината на сината област до површината на целиот квадрат, односно (0,4 - 0,1 ) * (1 - 0) / (1 * 1) = 0, 3, односно истите 30%. Веројатноста дека yе внатре во сегментот (зелена површина 2) е еднаква на односот на површината на зелената површина до површината на целиот плоштад стр(0,5 <= y <= 0,7) = 0,2, или кратко Р(Y) = 0,2.
Што може да се научи за вредностите во исто време xи y. На пример, колкава е веројатноста дека и двете xи yсе во соодветните дадени сегменти? За да го направите ова, треба да го пресметате односот на површината на доменот 3 (пресекот на зелените и сините ленти) до површината на целиот плоштад: стр(X, Y) = (0,4 – 0,1) * (0,7 – 0,5) / (1 * 1) = 0,06.
Сега да претпоставиме дека сакаме да знаеме која е веројатноста за тоа yе во интервалот ако xе веќе во опсегот. Тоа е, всушност, имаме филтер и кога повикуваме парови ( x, y), потоа веднаш ги отфрламе оние парови кои не го задоволуваат условот за наоѓање xво даден интервал, а потоа од филтрираните парови ги броиме оние за кои yја задоволува нашата состојба и сметајте ја веројатноста како однос на бројот на парови за кои yлежи во горниот сегмент до вкупниот број на филтрирани парови (односно, за кои xлежи во сегментот). Оваа веројатност можеме да ја запишеме како стр(Y|X на Xпогоди во опсегот“. Очигледно, оваа веројатност е еднаква на односот на површината од областа 3 до површината на сината површина 1. Областа на областа 3 е (0,4 - 0,1) * (0,7 - 0,5) = 0,06, и областа на сината површина 1 ( 0,4 - 0,1) * (1 - 0) = 0,3, тогаш нивниот сооднос е 0,06 / 0,3 = 0,2. Со други зборови, веројатноста за наоѓање yна сегментот, под услов xприпаѓа на сегментот стр(Y|X) = 0,2.
Во претходниот став, ние всушност го формулиравме идентитетот: стр(Y|X) = стр(X, Y) /p( X). Тоа гласи: „веројатност за удирање наво опсегот, под услов Xхит во опсегот е еднаков на односот на веројатноста за симултан удар Xво опсег и наво опсегот, до веројатноста за удирање Xво опсегот“.
По аналогија, разгледајте ја веројатноста стр(X|Y). Повикуваме парови x, y) и филтрирајте ги оние за кои yлежи помеѓу 0,5 и 0,7, тогаш веројатноста дека xе во сегментот под услов дека yприпаѓа на сегментот е еднаков на односот на површината на површина 3 до површината на зелената површина 2: стр(X|Y) = стр(X, Y) / стр(Y).
Забележете дека веројатностите стр(X, Y) и стр(Y, X) се еднакви, и двете се еднакви на односот на површината на зоната 3 до површината на целиот квадрат, но веројатностите стр(Y|X) и стр(X|Y) не е еднаков; додека веројатноста стр(Y|X) е еднаков на односот на површината од областа 3 до областа 1 и стр(X|Y) – домен 3 до домен 2. Забележете и дека стр(X, Y) често се означува како стр(X&Y).
Значи, имаме две дефиниции: стр(Y|X) = стр(X, Y) /p( X) и стр(X|Y) = стр(X, Y) / стр(Y)
Ајде да ги преработиме овие еднаквости како: стр(X, Y) = стр(Y|X)*p( X) и стр(X, Y) = стр(X|Y) * стр(Y)
Бидејќи левите страни се еднакви, така се и десните: стр(Y|X)*p( X) = стр(X|Y) * стр(Y)
Или можеме да ја преработиме последната еднаквост како:

Ова е теорема на Бејс!
Дали е можно таквите едноставни (речиси тавтолошки) трансформации да доведат до голема теорема!? Не брзајте со заклучоците. Ајде повторно да зборуваме за она што го добивме. Имаше некоја почетна (а приори) веројатност Р(X) дека случајната променлива Xрамномерно распоредени на сегментот спаѓа во опсегот X. Се случи некој настан Y, како резултат на што ја добивме a posteriori веројатноста на истата случајна променлива X: Р(X|Y), и оваа веројатност се разликува од Р(X) со коефициентот . Настан Yнаречен доказ, повеќе или помалку потврдување или побивање X. Овој коефициент понекогаш се нарекува моќ на докази. Колку е посилен доказот, колку повеќе фактот на набљудување Y ја менува претходната веројатност, толку повеќе задната веројатност се разликува од претходната. Ако доказите се слаби, задниот е речиси еднаков на претходниот.
Бејсовата формула за дискретни случајни променливи
Во претходниот дел, ја изведовме Бејсовата формула за континуирани случајни променливи x и y дефинирани на интервалот. Размислете за пример со дискретни случајни променливи, од кои секоја зема две можни вредности. Во текот на рутинските лекарски прегледи, беше откриено дека на возраст од четириесет години, 1% од жените страдаат од рак на дојка. 80% од жените со рак добиваат позитивни резултати од мамографијата. 9,6% од здравите жени добиваат и позитивни резултати од мамографијата. За време на прегледот, жена од оваа возрасна група добила позитивен резултат на мамограм. Која е веројатноста таа навистина да има рак на дојка?
Текот на расудувањето/пресметките е како што следува. Од 1% од пациентите со рак, мамографијата ќе даде 80% позитивни резултати = 1% * 80% = 0,8%. Од 99% од здравите жени, мамографијата ќе даде 9,6% позитивни резултати = 99% * 9,6% = 9,504%. Вкупно, од 10,304% (9,504% + 0,8%) со позитивни резултати од мамографијата, само 0,8% се болни, а останатите 9,504% се здрави. Така, веројатноста дека жената со позитивен мамограм има рак е 0,8% / 10,304% = 7,764%. Дали мислевте 80% или така?
Во нашиот пример, формулата на Бејс ја има следната форма:
Ајде уште еднаш да зборуваме за „физичкото“ значење на оваа формула. Xе случајна променлива (дијагноза), која ги зема следните вредности: X 1- болен и X 2- здрав; Y– случајна променлива (резултат од мерење - мамографија), која ги зема вредностите: Y 1- позитивен резултат и Y2- негативен резултат; p(X 1)- веројатноста за заболување пред мамографија (а приори веројатност), еднаква на 1%; R(Y 1 |X 1 ) - веројатноста за позитивен резултат ако пациентот е болен (условна веројатност, бидејќи мора да биде наведена во условите на задачата), еднаква на 80%; R(Y 1 |X 2 ) – веројатноста за позитивен резултат ако пациентот е здрав (исто така условна веројатност), еднаква на 9,6%; p(X 2)- веројатноста дека пациентот е здрав пред мамографија (а приори веројатност), еднаква на 99%; p(X 1|Y 1 ) – веројатноста дека пациентот е болен, со оглед на позитивен резултат од мамограм (задна веројатност).
Се гледа дека задната веројатност (она што го бараме) е пропорционална на претходната веројатност (почетна) со малку покомплексен коефициент  . Пак ќе нагласам. Според мое мислење, ова е фундаментален аспект на бајесовиот пристап. Димензија ( Y) додаде одредена количина на информации на првично достапните (а приори), што го разјасни нашето знаење за објектот.
. Пак ќе нагласам. Според мое мислење, ова е фундаментален аспект на бајесовиот пристап. Димензија ( Y) додаде одредена количина на информации на првично достапните (а приори), што го разјасни нашето знаење за објектот.
Примери
За да го консолидирате опфатениот материјал, обидете се да решите неколку проблеми.
Пример 1Има 3 урни; во првите 3 бели топчиња и 1 црно; во втората - 2 бели топки и 3 црни; во третиот - 3 бели топчиња. Некој случајно приоѓа на една од урните и извлекува 1 топка од неа. Оваа топка е бела. Најдете ги задните веројатности дека топката е извлечена од 1-та, 2-та, 3-та урна.
Решение. Имаме три хипотези: H 1 = (првата урна избрана), H 2 = (избрана втора урна), H 3 = (избрана трета урна). Бидејќи урната е избрана по случаен избор, а приори веројатностите на хипотезите се: Р(Н 1) = Р(Н 2) = Р(Н 3) = 1/3.
Како резултат на експериментот, се појави настанот A = (од избраната урна беше извадена бела топка). Условни веројатности на настанот А под хипотезите H 1, H 2, H 3: P(A|H 1) = 3/4, P(A|H 2) = 2/5, P(A|H 3) = 1. На пример, првото равенство гласи вака: „веројатноста да се нацрта бело топче ако се избере првата урна е 3/4 (бидејќи во првата урна има 4 топки, а 3 од нив се бели)“.
Применувајќи ја Бајсовата формула, ги наоѓаме задните веројатности на хипотезите:

Така, во светлината на информациите за појавата на настанот А, веројатностите на хипотезите се променија: најверојатната стана хипотезата H 3 , најмалку веројатната - хипотезата H 2 .
Пример 2Двајца стрелци независно пукаат во иста цел, секој испука по еден истрел. Веројатноста за погодување на целта за првиот стрелец е 0,8, за вториот - 0,4. По пукањето, во целта била пронајдена една дупка. Најдете ја веројатноста оваа дупка да му припаѓа на првиот стрелец (го отфрламе исходот (и двете дупки се совпаднаа) како занемарливо малку веројатен).
Решение. Пред експериментот, можни се следните хипотези: H 1 = (ниту првата, ниту втората стрелка нема да погоди), H 2 = (двете стрелки ќе погодат), H 3 - (првиот стрелец ќе погоди, а вториот нема ), H 4 = (првиот стрелец нема да погоди, а вториот ќе погоди). Претходни веројатности на хипотези:
P (H 1) \u003d 0,2 * 0,6 \u003d 0,12; P (H 2) \u003d 0,8 * 0,4 \u003d 0,32; P (H 3) \u003d 0,8 * 0,6 \u003d 0,48; P (H 4) \u003d 0,2 * 0,4 \u003d 0,08.
Условните веројатности на набљудуваниот настан A = (има една дупка во целта) според овие хипотези се: P(A|H 1) = P(A|H 2) = 0; P(A|H 3) = P(A|H 4) = 1
По искуството, хипотезите H 1 и H 2 стануваат невозможни, а задните веројатности на хипотезите H 3 и H 4 според формулата на Бејс ќе бидат:

Бејс против спам
Формулата на Bayes најде широка примена во развојот на филтри за спам. Да речеме дека сакате да обучите компјутер да одреди кои е-пораки се спам. Ќе започнеме од речник и комбинации на зборови со помош на бајзиски проценки. Ајде прво да создадеме простор на хипотези. Дозволете ни да имаме 2 хипотези во врска со која било буква: H A е спам, H B не е спам, туку нормална, потребна буква.
Прво, да го „обучиме“ нашиот иден анти-спам систем. Да ги земеме сите букви што ги имаме и да ги поделиме на два „купишта“ од по 10 букви. Во едната ставаме спам букви и ја нарекуваме грамада H A, во другата ја ставаме потребната кореспонденција и ја нарекуваме грамада H B. Сега да видиме: кои зборови и фрази се наоѓаат во спам и потребните пораки и со која фреквенција? Овие зборови и фрази ќе се нарекуваат доказ и ќе се означат со E 1 , E 2 ... Излегува дека најчесто користените зборови (на пример, зборовите „како“, „ваши“) во купиштата H A и H B се појавуваат приближно со иста фреквенција. Така, присуството на овие зборови во писмото не ни кажува ништо за тоа на која грамада припаѓа (слаби докази). Ајде да им доделиме на овие зборови неутрална вредност на проценката на веројатноста за „спам“, да речеме, 0,5.
Нека фразата „разговорен англиски“ се појавува со само 10 букви, а почесто во спам-мејловите (на пример, во 7 спам-мејлови од сите 10) отколку во вистинските (во 3 од 10). Ајде да и дадеме на оваа фраза повисока оценка од 7/10 за спам, и пониска оценка за нормални е-пошта: 3/10. Спротивно на тоа, се покажа дека зборот „другар“ е почест со нормални букви (6 од 10). И така добивме кратко писмо: „Пријателе! Како е вашиот говорен англиски?. Ајде да се обидеме да ја оцениме неговата „спамност“. Ќе ги ставиме општите проценки P(H A), P(H B) за припадност на секој куп користејќи малку поедноставена Bayes формула и нашите приближни проценки:
P(H A) = A/(A+B), каде A \u003d p a1 * p a2 * ... * тава, B \u003d p b1 * p b2 * ... * p b n \u003d (1 - p a1) * (1 - p a2) * ... * ( 1 - p an).
Табела 1. Поедноставена (и нецелосна) бајзова евалуација на пишувањето

Така, нашето хипотетичко писмо доби оценка за веројатноста за припадност со акцент во насока на „спам“. Можеме ли да одлучиме да го фрлиме писмото во едно од купиштата? Ајде да ги поставиме праговите за одлучување:
- Ќе претпоставиме дека буквата припаѓа на грамадата H i ако P(H i) ≥ T.
- Буквата не припаѓа на купот ако P(H i) ≤ L.
- Ако L ≤ P(H i) ≤ T, тогаш не може да се донесе одлука.
Можете да земете T = 0,95 и L = 0,05. Бидејќи за предметното писмо и 0.05< P(H A) < 0,95, и 0,05 < P(H В) < 0,95, то мы не сможем принять решение, куда отнести данное письмо: к спаму (H A) или к нужным письмам (H B). Можно ли улучшить оценку, используя больше информации?
Да. Ајде да ја пресметаме оценката за секој доказ на различен начин, исто како што предложи Бејс. Нека:
F a е вкупниот број на спам пораки;
F ai е бројот на букви со сертификат јасво куп спам;
F b е вкупниот број на потребни букви;
F bi е бројот на букви со сертификат јасво куп потребни (релевантни) букви.
Тогаш: p ai = F ai /F a , p bi = F bi /F b . P(H A) = A/(A+B), P(H B) = B/(A+B), кадеА = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n
Ве молиме имајте предвид дека резултатите од доказните зборови p ai и p bi станаа објективни и може да се пресметаат без човечко учество.
Табела 2. Попрецизна (но нецелосна) баезијанска проценка за достапните карактеристики од писмо

Добивме сосема дефинитивен резултат - со голема маргина на веројатност, буквата може да се припише на потребните букви, бидејќи P(H B) = 0,997 > T = 0,95. Зошто се промени резултатот? Бидејќи користевме повеќе информации - го земавме предвид бројот на букви во секоја од купиштата и, патем, многу поправилно ги одредивме проценките p ai и p bi. Тие беа одредени на ист начин како и самиот Бајс, со пресметување на условните веројатности. Со други зборови, p a3 е веројатноста дека зборот „другар“ ќе се појави во е-поштата, имајќи предвид дека е-поштата веќе припаѓа на купот спам H A . Резултатот не се чекаше долго - се чини дека можеме да донесеме одлука со поголема сигурност.
Бејс наспроти корпоративна измама
Интересна примена на бајесовиот пристап беше опишана од MAGNUS8.
Мојот тековен проект (IS за откривање измама во производствено претпријатие) ја користи формулата на Bayes за да ја одреди веројатноста за измама (измама) во присуство / отсуство на неколку факти индиректно во корист на хипотезата за можноста за измама. Алгоритмот е самостојно учење (со повратна информација), т.е. ги пресметува своите коефициенти (условни веројатности) по фактичка потврда или непотврда на измамата при верификацијата од службата за економска безбедност.
Веројатно вреди да се каже дека таквите методи при дизајнирање алгоритми бараат прилично висока математичка култура на развивачот, бидејќи најмалата грешка во изведувањето и/или имплементацијата на пресметковните формули ќе го поништи и дискредитира целиот метод. Веројатните методи се особено виновни за ова, бидејќи човечкото размислување не е приспособено да работи со веројатносни категории и, соодветно на тоа, нема „видливост“ и разбирање на „физичкото значење“ на средните и конечните веројатни параметри. Таквото разбирање постои само за основните концепти на теоријата на веројатност, а потоа само треба многу внимателно да ги комбинирате и изведете сложените работи според законите на теоријата на веројатност - здравиот разум веќе нема да помогне за композитните објекти. Ова, особено, е поврзано со доста сериозни методолошки битки што се случуваат на страниците на современите книги за филозофијата на веројатноста, како и со голем број софизми, парадокси и куриозитети на оваа тема.
Друга нијанса со која морав да се соочам е дека, за жал, речиси сè што е повеќе или помалку КОРИСНО ВО ПРАКТИКАТА на оваа тема е напишано на англиски јазик. Во изворите на руски јазик, во основа постои само добро позната теорија со демонстративни примери само за најпримитивните случаи.
Целосно се согласувам со последниот коментар. На пример, Google, кога се обидуваше да најде нешто како книгата „Bayesian Probability“, не даде ништо разбирливо. Точно, тој рече дека во Кина е забранета книга со баезијанска статистика. (Професорот по статистика Ендрју Гелман објави на блог на Универзитетот Колумбија дека неговата книга, Анализа на податоци со регресија и повеќестепени/хиерархиски модели, е забранета да се објавува во Кина. текст.“) Се прашувам дали слична причина довела до отсуство на книги за Баезијан веројатност во Русија?
Конзервативизам во процесот на обработка на човечките информации
Веројатностите го одредуваат степенот на неизвесност. Веројатноста, и според Бајс и според нашата интуиција, е едноставно број помеѓу нула и она што го претставува степенот до кој донекаде идеализирана личност верува дека изјавата е вистинита. Причината поради која личноста е донекаде идеализирана е тоа што збирот на неговите веројатности за два меѓусебно исклучувачки настани мора да биде еднаков на неговата веројатност да се случи некој од тие настани. Својството на адитивност има такви импликации што малкумина вистински луѓе можат да им парираат на сите.
Бејсовата теорема е тривијална последица на својството на адитивност, непобитна и со која се согласија сите веројатности, бајзиски и други. Еден начин да го напишете е следниот. Ако P(H A |D) е последователната веројатност дека хипотезата А била откако била забележана дадената вредност D, P(H A) е нејзината претходна веројатност пред да се набљудува дадената вредност D, P(D|H A ) е веројатноста дека ќе се набљудува дадената вредност D, ако H A е точно, а P(D) е безусловна веројатност за дадена вредност D, тогаш
(1) P(H A |D) = P(D|H A) * P(H A) / P(D)
P(D) најдобро се смета за нормализирачка константа која предизвикува задните веројатности да се соберат до една над исцрпниот сет на меѓусебно исклучиви хипотези што се разгледуваат. Ако треба да се пресмета, може да биде вака:
Но, почесто P(D) се елиминира наместо да се брои. Удобен начин да се елиминира е да се трансформира теоремата на Бејс во форма на врска веројатност-коефициент.
Размислете за друга хипотеза, H B, меѓусебно исклучувачка за H A, и сменете го вашето мислење за неа врз основа на истата дадена количина што го променила вашето мислење за H A. Теоремата на Бајес вели дека
(2) P(H B |D) = P(D|H B) * P(H B) / P(D)
Сега ја делиме равенката 1 со равенката 2; резултатот ќе биде вака:

каде Ω 1 се задните коефициенти во корист на H A во однос на H B , Ω 0 се претходните коефициенти, а L е број познат на статистичарите како сооднос на веројатности. Равенката 3 е истата релевантна верзија на теоремата на Бејс како Равенката 1, и често е многу покорисна особено за експерименти кои вклучуваат хипотези. Поборниците на Бајза тврдат дека теоремата на Бајс е формално оптимално правило за тоа како да се ревидираат мислењата во светлината на новите податоци.
Ние сме заинтересирани да го споредиме идеалното однесување дефинирано со теоремата на Бејс со вистинското однесување на луѓето. За да ви дадеме идеја за тоа што значи ова, ајде да пробаме експеримент со вас како субјект. Оваа торба содржи 1000 покер чипови. Имам две од овие кеси, едната со 700 црвени и 300 сини чипови, а другата со 300 црвени и 700 сини. Свртев паричка за да одредам која да ја користам. Така, ако нашите мислења се исти, вашата моментална веројатност да нацртате торба со повеќе црвени чипови е 0,5. Сега, земате примерок по случаен избор, враќајќи се по секој токен. Во 12 чипови, добивате 8 црвени и 4 сини. Сега, врз основа на сè што знаете, колкава е веројатноста дека една чанта излезе со повеќе црвени? Јасно е дека е повисоко од 0,5. Ве молиме не продолжувајте со читање додека не ја снимите вашата оцена.
Ако изгледате како типичен предмет, вашиот резултат паѓа помеѓу 0,7 и 0,8. Меѓутоа, ако ја направиме соодветната пресметка, одговорот би бил 0,97. Навистина, многу ретко се случува човек на кој претходно не му било покажано влијанието на конзервативизмот да дојде до толку висока проценка, дури и ако бил запознаен со теоремата на Бејс.
Ако процентот на црвени чипс во кесата е Р, тогаш веројатноста за добивање рцрвени чипсови и ( n-р) сино во nпримероци со враќање - стр (1-стр)n-р. Така, во типичен експеримент со торба и покер чип, ако ХАзначи дека процентот на црвени чипови е r Аи ХБзначи дека уделот е РБ, тогаш односот на веројатност:

При примена на формулата на Бејс, мора да се земе предвид само веројатноста за вистинското набљудување, а не и веројатностите на други набљудувања што тој можеби ги направил, но не ги направил. Овој принцип има широки импликации за сите статистички и нестатистички примени на Бејсовата теорема; тоа е најважната техничка алатка на бајесовото размислување.
Бајесова револуција
Вашите пријатели и колеги зборуваат за нешто што се нарекува „Бејсова теорема“ или „Бајзово правило“ или нешто што се нарекува Бајесово размислување. Тие навистина се заинтересирани за тоа, па одите на интернет и наоѓате страница за теоремата на Бејс и... Тоа е равенка. И тоа е сè... Зошто математички концепт предизвикува таков ентузијазам во главите? Каков вид на „бајесова револуција“ се случува меѓу научниците и се тврди дека дури и самиот експериментален пристап може да се опише како негов посебен случај? Која е тајната што ја знаат следбениците на Бајс? Каква светлина гледаат?
Бајесовата револуција во науката не се случи бидејќи сè повеќе когнитивни научници одеднаш почнаа да забележуваат дека менталните феномени имаат бајесова структура; не затоа што научниците од секое поле почнале да го користат бајсовиот метод; туку затоа што самата наука е посебен случај на теоремата на Бејс; експерименталниот доказ е бајзијански доказ. Баезиските револуционери тврдат дека кога правите експеримент и добивате докази што ја „поддржуваат“ или „побиваат“ вашата теорија, таа потврда или побивање се случува според Бајзовските правила. На пример, мора да земете предвид не само дека вашата теорија може да го објасни феноменот, туку и дека постојат други можни објаснувања кои исто така можат да го предвидат овој феномен.
Претходно, најпопуларната филозофија на науката беше старата филозофија која беше поместена од Бајесовата револуција. Идејата на Карл Попер дека теориите можат целосно да се фалсификуваат, но никогаш целосно да се потврдат, е уште еден посебен случај на бајесовските правила; ако p(X|A) ≈ 1 - ако теоријата прави точни предвидувања, тогаш набљудувањето ~X многу силно го фалсификува A. Од друга страна, ако p(X|A) ≈ 1 и го набљудуваме X, тоа не поддржува теоријата многу; можен е некој друг услов Б, таков што p(X|B) ≈ 1, и под кој набљудувањето на X не доказ за А, туку доказ за Б. X|A) ≈ 1 и тоа p(X|~A) ≈ 0, што не можеме да го знаеме бидејќи не можеме да ги разгледаме сите можни алтернативни објаснувања. На пример, кога Ајнштајновата теорија за општата релативност ја надмина Њутновата теорија за гравитација, која може да се потврди, таа ги направи сите предвидувања на Њутновата теорија посебен случај на Ајнштајновата теорија.
Слично на тоа, тврдењето на Попер дека идејата мора да биде фалсификувана може да се толкува како манифестација на Бајесовото правило за зачувување на веројатноста; ако резултатот X е позитивен доказ за теоријата, тогаш резултатот ~X мора до одреден степен да ја фалсификува теоријата. Ако се обидувате да ги протолкувате и X и ~X како „поддршка“ на теорија, Баезиските правила велат дека тоа е невозможно! За да ја зголемите веројатноста за теорија, мора да ја подложите на тестови кои потенцијално можат да ја намалат нејзината веројатност; ова не е само правило за откривање шарлатани во науката, туку последица на теоремата за веројатност на Бајес. Од друга страна, идејата на Попер дека е потребно само фалсификување и не е потребна потврда е погрешна. Бејсовата теорема покажува дека фалсификувањето е многу силен доказ во споредба со потврдата, но фалсификувањето сепак е веројатна по природа; не е регулирано со фундаментално различни правила и не се разликува во тоа од потврдата, како што тврди Попер.
Така, откриваме дека многу феномени во когнитивните науки, плус статистичките методи што ги користат научниците, плус самиот научен метод, се сите посебни случаи на теоремата на Бејс. Ова е она за што е бајесовата револуција.
Добредојдовте во Бајесовиот заговор!
Литература за Баезијанска веројатност
2. Нобеловецот за економија Канеман (et al.) опишува многу различни примени на Бајс во прекрасна книга. Само во моето резиме на оваа многу голема книга, изброив 27 референци за името на еден презвитеријански министер. Минимални формули. (.. многу ми се допадна. Точно, комплицирано е, многу математика (и каде без неа), но поединечни поглавја (на пример, поглавје 4. Информации), јасно на темата. Ги советувам сите. Дури и ако математиката е тешко за вас, прочитајте низ редот, прескокнувајќи ја математиката и риболов за корисни зрна ...
14. (додаток од 15.01.2017 год), поглавје од книгата на Тони Крили. 50 идеи за кои треба да знаете. Математика.
Физичарот Ричард Фајнман, нобеловец, зборувајќи за еден филозоф со особено голема вообразеност, еднаш рекол: „Воопшто не ме нервира филозофијата како наука, туку помпата што се создава околу неа. Ако само филозофите можеа да се смеат на себе! Да можеа да кажат: „Јас велам дека е вака, но Фон Лајпциг мислеше дека е поинаку, а тој исто така знае нешто за тоа“. Само да се сетија да појаснат дека тоа е само нивно .
Можеби никогаш не сте слушнале за теоремата на Бајс, но сте ја користеле цело време. На пример, првично ја проценивте веројатноста да добиете зголемување на платата како 50%. Откако добивте позитивни повратни информации од менаџерот, го прилагодивте вашиот рејтинг на подобро и, обратно, го намаливте ако ја скршите машината за кафе на работа. Така се рафинира вредноста на веројатноста додека се акумулираат информациите.
Главната идеја на теоремата на Бејсе да се добие поголема точност на проценката на веројатноста на настанот со земање предвид на дополнителни податоци.
Принципот е едноставен: постои почетна основна проценка на веројатноста, која е пречистена со повеќе информации.
Формула на Бејс
Интуитивните активности се формализирани во едноставна, но моќна равенка ( Формула за веројатност на Бејс):

Левата страна на равенката е постериорина проценка на веројатноста за настанот А под услов на настанување на настанот Б (т.н. условна веројатност).
- P(A)- веројатност за настанот А (основна, а приори проценка);
- P(B|A) -веројатноста (исто така условена) што ја добиваме од нашите податоци;
- а P(B)е константа на нормализација која ја ограничува веројатноста на 1.
Оваа кратка равенка е основата Бајзов метод.
Апстрактната природа на настаните А и Б не ни дозволува јасно да го разбереме значењето на оваа формула. За да ја разбереме суштината на теоремата на Бајс, да разгледаме реален проблем.
Пример
Една од темите на кои работам е проучувањето на навиките на спиење. Имам два месеци снимени податоци со мојот часовник Garmin Vivosmart кои покажуваат во кое време одам да спијам и да се будам. Прикажан е последниот модел најверојатноРаспределбата на веројатноста за спиење како функција од времето (MCMC е приближен метод) е дадена подолу.

Графиконот ја покажува веројатноста да спијам, во зависност само од времето. Како ќе се промени ако се земе предвид времето во кое свети светлото во спалната соба? За да се усоврши проценката, потребна е теорема на Бајс. Рафинираната проценка се заснова на априори и има форма:

Изразот лево е веројатноста дека спијам, со оглед на тоа што се знае дека светлото во мојата спална соба е вклучено. Претходната проценка во даден временски момент (прикажана на графиконот погоре) е означена како P (спиење). На пример, во 22:00 часот, претходната веројатност дека спијам е 27,34%.
Додадете повеќе информации користејќи веројатност P(светло за спална соба|спиење)добиени од набљудуваните податоци.
Од моите набљудувања, го знам следново: веројатноста да спијам кога свети светлото е 1%.
Веројатноста дека светлото е исклучено за време на спиењето е 1-0,01 = 0,99 (знакот „-“ во формулата значи спротивен настан), бидејќи збирот на веројатностите на спротивните настани е 1. Кога спијам, светлината во спалната соба е овозможена или оневозможена.
Конечно, равенката ја вклучува и константата на нормализација P (светло)веројатноста дека светлото е вклучено. Светлото е вклучено и кога спијам и кога сум буден. Затоа, знаејќи ја априори веројатноста за спиење, ја пресметуваме константата на нормализација на следниов начин:
Веројатноста дека светлото е вклучено се зема предвид и во двете опции: или спијам или не ( P (-спиење) = 1 — P (спиење)е веројатноста дека сум буден.)
Веројатноста да свети светлото кога сум буден е P(лесно|-спиење),а се одредува со набљудување. Знам дека има 80% шанси да свети светлото кога сум буден (што значи дека има 20% шанси да не свети ако сум буден).
Конечната Бајсова равенка станува:
Ви овозможува да ја пресметате веројатноста дека спијам, со оглед на тоа што свети светлото. Ако нè интересира веројатноста дека светлото е исклучено, потребна ни е секоја конструкција P(светло|…заменет со P(-светло|….
Ајде да видиме како добиените симболички равенки се користат во пракса.
Да ја примениме формулата на времето 22:30 и да земеме во предвид дека светлото е вклучено. Знаеме дека има 73,90% шанси да сум спиел. Оваа бројка е почетна точка за нашата евалуација.
Ајде да го рафинираме, земајќи ги предвид информациите за осветлувањето. Знаејќи дека светлото е вклучено, ние ги заменуваме броевите во формулата на Бејс:
Дополнителните податоци драматично ја променија проценката на веројатноста, од над 70% на 3,42%. Ова ја покажува моќта на теоремата на Бајс: успеавме да ја усовршиме нашата првична проценка на ситуацијата со вклучување повеќе информации. Можеби интуитивно го правевме ова порано, но сега, размислувајќи за тоа во смисла на формални равенки, успеавме да ги потврдиме нашите предвидувања.
Да разгледаме уште еден пример. Што ако часовникот е 21:45, а светлата се исклучени? Обидете се сами да ја пресметате веројатноста, претпоставувајќи претходна проценка од 0,1206.
Наместо рачно броење секој пат, напишав едноставен Python код за да ги направам овие пресметки, што можете да го испробате во Jupyter Notebook. Ќе го добиете следниов одговор:
Време: 21:45:00 часот Светлото е исклучено.
Претходна веројатност за спиење: 12,06%
Ажурирана веројатност за спиење: 40,44%
Повторно, дополнителните информации ја менуваат нашата проценка. Сега, ако сестра ми сака да ми се јави во 21 часот и 45 минути знаејќи дека светлото ми е вклучено, може да ја искористи оваа равенка за да одреди дали можам да го подигнам телефонот (претпоставувајќи дека кревам само кога сум буден)! Кој вели дека статистиката не е применлива во секојдневниот живот?
Визуелизација на веројатност
Набљудувањето на пресметките е корисно, но визуелизацијата помага да се стекне подлабоко разбирање на резултатот. Секогаш се трудам да користам графикони за да генерирам идеи ако тие не доаѓаат природно од само проучување равенки. Можеме да ја визуелизираме претходната и задната распределба на веројатноста на спиењето користејќи дополнителни податоци:

Кога светлото е вклучено, графиконот се поместува надесно, што покажува дека е помала веројатноста да спијам во тоа време. Исто така, графикот се префрла налево ако светлото ми е исклучено. Разбирањето на значењето на теоремата на Бајс не е лесно, но оваа илустрација јасно покажува зошто треба да ја користите. Формулата Bayes е алатка за рафинирање на прогнозите со дополнителни податоци.
Што ако има уште повеќе податоци?
Зошто да застанете на осветлување на спалната соба? Можеме да користиме уште повеќе податоци во нашиот модел за дополнително да ја усовршиме проценката (се додека податоците остануваат корисни за случајот што се разгледува). На пример, знам дека ако телефонот ми се полни, тогаш има 95% шанси да спијам. Овој факт може да се земе предвид во нашиот модел.
Да претпоставиме дека веројатноста дека мојот телефон се полни е независна од осветлувањето во спалната соба (независноста на настаните е силно претерано поедноставување, но многу ќе ја олесни задачата). Ајде да направиме нов, уште попрецизен израз за веројатноста:
Резултирачката формула изгледа незгодна, но со користење на Python код, можеме да напишеме функција што ќе ја изврши пресметката. За која било временска точка и каква било комбинација на осветлување/полнење на телефонот, оваа функција ја враќа прилагодената веројатност дека спијам.
Времето е 23:00:00 часот Светлото е вклучено Телефонот НЕ се полни.
Претходна веројатност за спиење: 95,52%
Ажурирана веројатност за спиење: 1,74%
Во 23:00 часот, без дополнителни информации, речиси сигурно можевме да кажеме дека сонувам. Меѓутоа, штом имаме дополнителни информации дека светлото е вклучено и телефонот не се полни, заклучуваме дека веројатноста да спијам е практично нула. Еве уште еден пример:
Времето е 22:15:00 часот Светлото е исклучено Телефонот се полни.
Претходна веројатност за спиење: 50,79%
Ажурирана веројатност за спиење: 95,10%
Веројатноста се менува надолу или нагоре во зависност од конкретната ситуација. За да го покажете ова, разгледајте четири дополнителни конфигурации на податоци и како тие ја менуваат распределбата на веројатноста:

Овој графикон дава многу информации, но главната поента е дека кривата на веројатност се менува во зависност од дополнителни фактори. Како што се додаваат повеќе податоци, ќе добиеме попрецизна проценка.
Заклучок
Теоремата на Бејс и другите статистички концепти може да биде тешко да се разберат кога се претставени со апстрактни равенки користејќи само букви или имагинарни ситуации. Вистинското учење доаѓа кога применуваме апстрактни концепти на реални проблеми.
Успехот во науката за податоци е поврзан со континуирано учење, додавање нови методи во вашиот сет на вештини и наоѓање на најдобриот метод за решавање на проблемите. Бејсовата теорема ни овозможува да ги усовршиме нашите проценки на веројатност со дополнителни информации за подобро да ја моделираме реалноста. Зголемувањето на количината на информации овозможува попрецизни предвидувања, а Бејс се покажува како корисна алатка за оваа задача.
Ги поздравувам повратните информации, дискусијата и конструктивната критика. Можете да ме контактирате на Твитер.
Лекција број 4.
Тема: Формула за вкупна веројатност. Формула на Бејс. Шема на Бернули. Полиномна шема. Хипергеометриска шема.
ФОРМУЛА ЗА ВКУПНА веројатност
ФОРМУЛА НА БЕЈС
ТЕОРИЈА
Формула за вкупна веројатност:
Нека има целосна група на некомпатибилни настани:
(, ![]() Тогаш веројатноста за настанот А може да се пресмета со формулата
Тогаш веројатноста за настанот А може да се пресмета со формулата
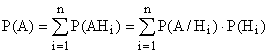 (4.1)
(4.1)
Настаните се нарекуваат хипотези. Се поставуваат хипотези во однос на оној дел од експериментот во кој постои неизвесност.
, каде се априори веројатностите на хипотезите
Формула на Бејс:
Нека експериментот е завршен и се знае дека настанот А се случил како резултат на експериментот. Потоа, земајќи ги предвид овие информации, можеме прецени ги веројатностите на хипотезите:
![]() (4.2)
(4.2)
 , каде задни веројатности на хипотези
, каде задни веројатности на хипотези
РЕШАВАЊЕ НА ПРОБЛЕМ
Задача 1.
Состојба
Во 3 серии делови добиени во магацин, добрите се 89 %, 92 % и 97 % соодветно. Бројот на делови во серии е означен како 1:2:3.
Колкава е веројатноста случајно избраниот дел од магацинот да биде неисправен. Нека се знае дека случајно избран дел се покажал неисправен. Најдете ги веројатностите дека им припаѓа на првата, втората и третата страна.
Решение:
Означете го со A настанот дека случајно избраниот дел се покажува како дефектен.
1-во прашање - до формулата за вкупна веројатност
второ прашање - на Бајсовата формула
Се поставуваат хипотези во однос на оној дел од експериментот во кој постои неизвесност. Во овој проблем, неизвесноста се состои во тоа од која серија е случајно избраниот дел.
Нека во првиот натпревар адетали. Потоа во вториот натпревар - 2 адетали, а во третата - 3 адетали. Само три натпревари 6 адетали.
![]()
![]()
![]()
![]() (процентот на брак на првата линија беше преведен во веројатност)
(процентот на брак на првата линија беше преведен во веројатност)
![]() (процентот на брак на втората линија беше преведен во веројатност)
(процентот на брак на втората линија беше преведен во веројатност)
![]() (процентот на брак во третата линија претворен во веројатност)
(процентот на брак во третата линија претворен во веројатност)
Користејќи ја формулата за вкупна веројатност, ја пресметуваме веројатноста за настан А
-одговор на 1 прашање
Веројатноста дека дефектниот дел припаѓа на првата, втората и третата серија се пресметуваат со помош на формулата на Бејс:



Задача 2.
Состојба:
Во првата урна 10 топки: 4 белците и 6 црна. Во втората урна 20 топки: 2 белците и 18 црна. Од секоја урна по случаен избор се избира по една топка и се става во третата урна. Потоа по случаен избор се избира една топка од третата урна. Најдете ја веројатноста дека топката извлечена од третата урна е бела.
Решение:
Одговорот на прашањето на проблемот може да се добие со помош на формулата за вкупна веројатност:
Неизвесноста лежи во тоа кои топки завршиле во третата урна. Изнесовме хипотези за составот на топчињата во третата урна.
H1=(има 2 бели топчиња во третата урна)
H2=(има 2 црни топки во третата урна)
H3=( третата урна содржи 1 бела и 1 црна топка)
A=(топката земена од урната 3 ќе биде бела)
![]()
Задача 3.
Бела топка се фрла во урна која содржи 2 топчиња со непозната боја. После тоа, вадиме 1 топче од оваа урна. Најдете ја веројатноста дека топката извлечена од урната е бела. Топката земена од урната опишана погоре испадна бела. Најдете ги веројатностите дека во урната пред трансферот имало 0 бели топки, 1 бело топче и 2 бели топки .
1 прашањев - до формулата за вкупна веројатност
2 прашање- на Бајсовата формула
Неизвесноста лежи во почетниот состав на топчињата во урната. Во однос на првичниот состав на топчињата во урната, ги поставуваме следните хипотези:
Здраво=( во урната пред смената бешеi-1 бела топка),i=1,2,3
, i=1,2,3(во ситуација на целосна неизвесност, ги земаме априори веројатностите на хипотезите за исти, бидејќи не можеме да кажеме дека едната опција е поверојатна од другата)
A = (топката извлечена од урната по трансферот ќе биде бела)
Да ги пресметаме условните веројатности:
Ајде да направиме пресметка користејќи ја формулата за вкупна веројатност:
Одговор на 1 прашање
За да одговориме на второто прашање, ја користиме формулата на Бејс:
 (намален во споредба со претходната веројатност)
(намален во споредба со претходната веројатност)
 (непроменето од претходната веројатност)
(непроменето од претходната веројатност)
 (зголемена во споредба со претходната веројатност)
(зголемена во споредба со претходната веројатност)
Заклучок од споредбата на претходните и задните веројатности на хипотезите: почетната неизвесност е квантитативно променета
Задача 4.
Состојба:
При трансфузија на крв, неопходно е да се земат предвид крвните групи на донаторот и на пациентот. Лицето кое има четврта групакрв може да се трансфузира секаков тип на крв, на некоја личност со втората и третата групаможе да се истури или крвта на неговата група, или прво.на една личност со првата крвна групаможете да трансфузирате крв само првата група.Познато е дека меѓу населението 33,7 % имаат прва групапу, 37,5 % имаат втора група, 20,9%имаат трета групаи 7,9% имаат 4-та група.Најдете ја веројатноста дека на случајно земен пациент може да му се трансфузира крвта на случајно земен дарител.
Решение:
Изнесовме хипотези за крвната група на случајно земен пациент:
Здраво=(кај пациентi-та крвна група),i=1,2,3,4
![]()
![]()
![]()
![]()
(Проценти претворени во веројатности)
A=(може да се трансфузира)
Според формулата за вкупна веројатност, добиваме:
т.е. трансфузија може да се изврши во околу 60% од случаите
Бернулиова шема (или биномна шема)
Испитувања на Бернули -ова е независни тестови 2 исход, кој условно го нарекуваме успех и неуспех.
p-стапка на успех
q-веројатност за неуспех
Веројатност за успех не се менува од искуство во искуство
Резултатот од претходниот тест не влијае на следниот тест.
Спроведувањето на тестовите опишани погоре се нарекува Бернулиева шема или биномна шема.
Примери на Бернули тестови:
Фрлање паричкаУспех -грб
неуспех-опашки
Случајот на точната монета
погрешна кутија за монети
стри qне менувајте од искуство во искуство ако не ја смениме паричката за време на експериментот
Фрлање коцкаУспех -ролна „6“
неуспех -сите останати
Случајот на обична коцка
Случај на погрешни коцки
стри qне се менувајте од искуство во искуство, ако во процесот на спроведување на експериментот не ги менуваме коцките
Стрела кон целтаУспех -удри
неуспех -Госпоѓица
p = 0,1 (стрелец погодува во еден истрел од 10)
стри qне менувајте од искуство во искуство, ако во процесот на спроведување на експериментот не ја смениме стрелката
Формула Бернули.
Некаодржана n стр. Размислете за настани
(воn испитувања на Бернули со веројатност за успехстр ќе се случим успеси),
![]() -постои стандардна нотација за веројатноста за вакви настани
-постои стандардна нотација за веројатноста за вакви настани
<-Бернулиевата формула за пресметување на веројатности (4.3)
Објаснување на формулата : веројатност дека ќе има m успеси (веројатностите се множат, бидејќи испитувањата се независни, а бидејќи сите се исти, се појавува степен), - веројатноста да се случат n-m неуспеси (објаснувањето е слично како и за успесите), - бројот на начини за имплементација на настанот, односно на колку начини m успеси може да се постават на n места.
Последици од формулата Бернули:
Заклучок 1:
Некаодржана nИспитувања на Бернули со веројатност за успех стр. Размислете за настани
А(m1,m2)=(број на успеси воn Пробите на Бернули ќе бидат опфатени во опсегот [m1;m2])
![]() (4.4)
(4.4)
Објаснување на формулата:
Формулата (4.4) следи од формулата (4.3) и теоремата за собирање на веројатност за некомпатибилни настани, бидејќи  - збирот (соединувањето) на некомпатибилните настани, а веројатноста за секој се одредува со формулата (4.3).
- збирот (соединувањето) на некомпатибилните настани, а веројатноста за секој се одредува со формулата (4.3).
Последица 2
Некаодржана nИспитувања на Бернули со веројатност за успех стр. Размислете за настан
A=( воn Пробите на Бернули ќе резултираат со најмалку 1 успех}
![]() (4.5)
(4.5)
Објаснување на формулата: ={ нема да има успех во обидите на Бернули)=
(сите n испитувања ќе пропаднат)
Проблем (за формулата Бернули и последиците од неа)пример за задача 1.6-D. ч.
Точна монета фрли 10 пати. Најдете ги веројатностите на следните настани:
A=(грбот ќе падне точно 5 пати)
B=(грбот ќе падне не повеќе од 5 пати)
C=(грбот ќе падне барем еднаш)
Решение:
Да го преформулираме проблемот во однос на тестовите на Бернули:
n=10 број на испитувања
успех- грб
p=0,5 – веројатност за успех
q=1-p=0,5 – веројатност за неуспех
За да ја пресметаме веројатноста за настанот А, користиме Формула Бернули:

За да ја пресметаме веројатноста за настанот Б, користиме последица 1до Формулата на Бернули:

За да ја пресметаме веројатноста за настан C, користиме заклучок 2до Формулата на Бернули:

Шема на Бернули. Пресметка со приближни формули.
ПРИБЛИЧНА ФОРМУЛА НА МОИАВРЕ-ЛАПЛАС
Локална формула
струспех и qнеуспех, тогаш за сите мвалидна е приближната формула:
 , (4.6)
, (4.6)
м.
Вредноста на функцијата може да се најде во специјалното маса. Содржи само вредности за. Но, функцијата е рамномерна, т.е.
Ако, тогаш да претпоставиме
интегрална формула
Ако бројот на испитувања n во шемата Бернули е голем, а веројатностите се исто така големи струспех и qнеуспех, тогаш приближната формула важи за сите (4.7) :
Вредноста на функцијата може да се најде во посебна табела. Содржи само вредности за. Но, функцијата е непарна, т.е. ![]() .
.
Ако, тогаш да претпоставиме
ПРИБЛИЧНА ФОРМУЛА НА ОТРОВИТЕ
Локална формула
Нека бројот на испитувања nспоред шемата на Бернули е голема, а веројатноста за успех во еден тест е мала, а производот е исто така мал. Потоа се одредува со приближната формула:
![]() , (4.8)
, (4.8)
Веројатноста дека бројот на успеси во n Бернули испитувања е м.
Функционални вредности ![]() може да се види во посебна табела.
може да се види во посебна табела.
интегрална формула
Нека бројот на испитувања nспоред шемата на Бернули е голема, а веројатноста за успех во еден тест е мала, а производот е исто така мал.
Потоа ![]() определено со приближната формула:
определено со приближната формула:
 , (4.9)
, (4.9)
Веројатноста дека бројот на успеси во n Бернули испитувања е во опсегот.
Функционални вредности ![]() може да се гледа во посебна табела, а потоа да се сумира во опсегот.
може да се гледа во посебна табела, а потоа да се сумира во опсегот.
|
Формула |
Поасон формула |
Формула Moivre-Laplace |
Квалитет проценки |
|
проценките се груби |
|||
|
10 |
се користи за груби проценки пресметки |
||
|
се користи за применети инженерски пресметки |
|||
|
100 0 |
се користи за какви било инженерски пресметки |
||
|
n> 1000 |
многу добри оценки |
Можете да го погледнете квалитетот на примерите за задачите 1.7 и 1.8 D. z.
Пресметка со формулата Поасон.
Проблем (Поасонова формула).
Состојба:
Веројатноста за искривување на еден симбол при пренесување на порака преку комуникациска линија е еднаква на 0.001. Пораката се смета за прифатена доколку во неа нема изобличувања. Најдете ја веројатноста за примање порака која се состои од 20 зборови по 100ликови секој.
Решение:
Означи со НО
-број на знаци во пораката
успех: карактерот не е искривен
Веројатност за успех
Ајде да пресметаме. Видете препораки за користење приближни формули ( ![]() )
: за пресметката треба да аплицирате Поасон формула
)
: за пресметката треба да аплицирате Поасон формула
Веројатности за Поасоновата формула во однос на иm може да се најде во посебна табела.
Состојба:
Телефонската централа опслужува 1000 претплатници. Веројатноста дека во рок од една минута на секој претплатник ќе му треба поврзување е 0,0007. Пресметајте ја веројатноста за една минута да пристигнат најмалку 3 повици на телефонската централа.
Решение:
Преформулирајте го проблемот во смисла на Бернулиевата шема
успех: примен повик
Веројатност за успех
– опсегот во кој мора да лежи бројот на успеси
A = (ќе пристигнат најмалку три повици) - настан, чија веројатност е потребна. најдете во задача
(Ќе пристигнат помалку од три повици) Продолжуваме кон дополнителните. настан, бидејќи неговата веројатност е полесна за пресметување.
![]()
(пресметка на термини види посебна табела)
На овој начин,
Проблем (локална формула Мувр-Лаплас)
Состојба
Веројатност да се погоди целта со еден истрел е еднакво на 0,8.Одреди ја веројатноста дека на 400ќе се случат истрели точно 300хитови.
Решение:
Преформулирајте го проблемот во смисла на Бернулиевата шема
n=400 – број на испитувања
m=300 – број на успеси
успех - хит
(Проблемско прашање во однос на шемата на Бернули)
Проценка:
Трошиме независни тестови, во секоја од нив разликуваме m опции.
p1 - веројатноста да се добие првата опција во една проба
p2 - веројатноста за добивање на втората опција во едно проба
…………..
pm е веројатноста за добивањеm-та опција во една проба
p1,стр2, ………………..,pm не се менувајте од искуство во искуство
Редоследот на тестови опишан погоре се нарекува полиномна шема.
(кога m=2, полиномната шема се претвора во биномна), т.е. биномната шема опишана погоре е посебен случај на поопшта шема наречена полином).
Размислете за следните настани
А(n1,n2,….,nm)=( во n испитувања опишани погоре, варијантата 1 се појавила n1 пати, варијантата 2 се појавила n2 пати, ….., итн., nm пати се појавила варијантата m)
Формула за пресметување на веројатности со помош на полиномна шема
Состојба
коцки фрли 10 пати.Потребно е да се најде веројатноста дека „6“ ќе испадне 2 пати, и „5“ ќе испадне 3 пати.
Решение:
Означи со НО настанот чија веројатност се наоѓа во проблемот.
n=10 -број на испитувања
m=3
1 опција - капка 6
p1=1/6n1=2
Опција 2 - Капка 5
p2=1/6n2=3
Опција 3 - Спуштете го секое лице освен 5 и 6
p3=4/6n3=5
P(2,3,5)-? (веројатност за настанот наведен во состојбата на проблемот)
Задача за полиномното коло
Состојба
Најдете ја веројатноста дека меѓу 10 Случајно избраните луѓе ќе имаат четири родендени во првиот квартал, три во вториот, два во третиот и еден во четвртиот.
Решение:
Означи со НО настанот чија веројатност се наоѓа во проблемот.
Да го преформулираме проблемот во смисла на полиномна шема:
n=10 -број на испитувања = број на луѓе
m=4е бројот на опции што ги разликуваме во секое испитување
Опција 1 - раѓање во 1 четвртина
p1=1/4n1=4
Опција 2 - раѓање во втор квартал
p2=1/4n2=3
Опција 3 - раѓање во 3 четвртина
p3=1/4n3=2
Опција 4 - раѓање во 4-та четвртина
p4=1/4n4=1
P(4,3,2,1) -? (веројатност за настанот наведен во состојбата на проблемот)
Претпоставуваме дека веројатноста да се родиме во која било четвртина е иста и е еднаква на 1/4.Ајде да ја извршиме пресметката според формулата за полиномната шема:
Задача за полиномното коло
Состојба
во урната 30 топки: Добредојде назад.3 бели, 2 зелени, 4 сини и 1 жолта.
Решение:
Означи со НО настанот чија веројатност се наоѓа во проблемот.
Да го преформулираме проблемот во смисла на полиномна шема:
n=10 -број на обиди = број на избрани топки
m=4е бројот на опции што ги разликуваме во секое испитување
Опција 1 - изберете бела топка
p1=1/3n1=3
Опција 2 - изберете ја зелената топка
p2=1/6n2=2
Трета опција - избор на сината топка
p3=4/15n3=4
Опција 4 - изберете ја жолтата топка
p4=7/30n4=1
P(3,2,4,1)-? (веројатност за настанот наведен во состојбата на проблемот)
p1,стр2, p3,стр4 не се менувајте од искуство во искуство, бидејќи изборот се прави со враќање
Ајде да ја извршиме пресметката според формулата за полиномната шема:
Хипергеометриска шема
Нека има n елементи од k типови:
n1 од првиот тип
n2 од вториот тип
nk тип k
Од овие n елементи по случаен избор нема враќањеизберете m елементи
Размислете за настанот A(m1,…,mk), кој се состои во тоа што меѓу избраните m елементи ќе има
m1 од првиот тип
м2 од втор тип
mk k-ти тип
Веројатноста за овој настан се пресметува со формулата
P(A(m1,…,mk))=  (4.11)
(4.11)
Пример 1
Задача за хипергеометриска шема (примерок за задача 1.9 D. h)
Состојба
во урната 30 топки: 10 бели, 5 зелени, 8 сини и 7 жолти(топчињата се разликуваат само по боја). Од урната по случаен избор се избираат 10 топчиња. нема враќање. Најдете ја веројатноста дека меѓу избраните топки ќе има: 3 бели, 2 зелени, 4 сини и 1 жолта.
Ние имамеn=30,k=4,
n1=10,n2=5,n3=8,n4=7,
m1=3,m2=2,m3=4,m4=1
P(A(3,2,4,1))=  = може да се изброи до број знаејќи ја формулата за комбинации
= може да се изброи до број знаејќи ја формулата за комбинации
Пример 2
Пример за пресметка според оваа шема: видете ги пресметките за играта Sportloto (тема 1)


