Prosta matematyka twierdzenia Bayesa. Rozwiązywanie problemów za pomocą formuły całkowitego prawdopodobieństwa i formuły Bayesa teorii całkowitego prawdopodobieństwa
Niech znane będą ich prawdopodobieństwa i odpowiadające im prawdopodobieństwa warunkowe. Wtedy prawdopodobieństwo zajścia zdarzenia wynosi:
Ta formuła nazywa się wzory na prawdopodobieństwo całkowite. W podręcznikach jest sformułowany przez twierdzenie, którego dowód jest elementarny: zgodnie z algebra zdarzeń, (zdarzenie miało miejsce oraz lub wydarzyło się wydarzenie oraz po nim nastąpiło wydarzenie lub wydarzyło się wydarzenie oraz po nim nastąpiło wydarzenie lub …. lub wydarzyło się wydarzenie oraz obserwowane wydarzenie). Od hipotez ![]() są niezgodne, a zdarzenie zależne, to wg twierdzenie o dodawaniu prawdopodobieństw zdarzeń niekompatybilnych (pierwszy krok) oraz twierdzenie o mnożeniu prawdopodobieństw zdarzeń zależnych (drugi krok):
są niezgodne, a zdarzenie zależne, to wg twierdzenie o dodawaniu prawdopodobieństw zdarzeń niekompatybilnych (pierwszy krok) oraz twierdzenie o mnożeniu prawdopodobieństw zdarzeń zależnych (drugi krok):

Zapewne wielu przewiduje treść pierwszego przykładu =)
Gdziekolwiek plujesz - wszędzie urna:
Zadanie 1
Istnieją trzy identyczne urny. W pierwszej urnie są 4 kule białe i 7 czarnych, w drugiej urnie są tylko kule białe, a w trzeciej urnie są tylko kule czarne. Wybieramy losowo jedną urnę i losujemy z niej kulę. Jakie jest prawdopodobieństwo, że ta kula jest czarna?
Decyzja: rozważ zdarzenie - z losowo wybranej urny zostanie wylosowana czarna kula. To zdarzenie może, ale nie musi, wystąpić w wyniku jednej z następujących hipotez:
– wybrana zostanie I urna;
– wybrana zostanie 2. urna;
– wybrana zostanie trzecia urna.
Ponieważ urna jest wybierana losowo, wybór jednej z trzech urn równie możliwe, W konsekwencji: ![]()
Zauważ, że powyższe hipotezy tworzą pełna grupa imprez, czyli zgodnie z warunkiem czarna bila może pojawić się tylko z tych urn, a np. nie odlecieć ze stołu bilardowego. Zróbmy proste pośrednie sprawdzenie: ![]() OK, przejdźmy dalej:
OK, przejdźmy dalej:
Pierwsza urna zawiera 4 białe + 7 czarnych = 11 kul każda klasyczna definicja:
jest prawdopodobieństwem wylosowania kuli czarnej jeśli się uwzględniże pierwsza urna zostanie wybrana.
W drugiej urnie są tylko kule białe, tzn jeśli wybrano pojawia się czarna kula niemożliwe: .
I wreszcie w trzeciej urnie są tylko czarne kule, co oznacza, że odpowiadają warunkowe prawdopodobieństwo ekstrakcji czarnej kuli będzie (zdarzenie jest pewne).
to prawdopodobieństwo, że z losowo wybranej urny zostanie wylosowana kula czarna.
Odpowiadać:
Analizowany przykład ponownie pokazuje, jak ważne jest ZROZUMIENIE STANU. Weźmy te same problemy z urnami i kulkami - przy ich zewnętrznym podobieństwie metody rozwiązywania mogą być zupełnie inne: gdzieś wymagane jest zastosowanie tylko klasyczna definicja prawdopodobieństwa, gdzieś wydarzenia niezależny, gdzieś zależny, a gdzieś mówimy o hipotezach. Jednocześnie nie ma jasnego formalnego kryterium wyboru ścieżki rozwiązania – prawie zawsze trzeba się nad tym zastanowić. Jak poprawić swoje umiejętności? Rozwiązujemy, rozwiązujemy i jeszcze raz rozwiązujemy!
Zadanie 2
Na strzelnicy znajduje się 5 różnych karabinów. Prawdopodobieństwa trafienia w cel dla danego strzelca są odpowiednio równe 0,5; 0,55; 0,7; 0,75 i 0,4. Jakie jest prawdopodobieństwo trafienia w cel, jeśli strzelec odda jeden strzał z losowo wybranego karabinu?
Krótkie rozwiązanie i odpowiedź na końcu lekcji.
W większości problemów tematycznych hipotezy nie są oczywiście równie prawdopodobne:
Zadanie 3
W piramidzie znajduje się 5 karabinów, z których trzy są wyposażone w celownik optyczny. Prawdopodobieństwo, że strzelec trafi w cel, strzelając z karabinu z celownikiem teleskopowym, wynosi 0,95; dla karabinu bez celownika teleskopowego prawdopodobieństwo to wynosi 0,7. Znajdź prawdopodobieństwo, że cel zostanie trafiony, jeśli strzelec odda jeden strzał z losowo wybranego karabinu.
Decyzja: w tym zadaniu liczba karabinów jest dokładnie taka sama jak w poprzednim, ale są tylko dwie hipotezy:
- strzelec wybierze karabin z celownikiem optycznym;
- strzelec wybierze karabin bez celownika teleskopowego.
Przez klasyczna definicja prawdopodobieństwa: ![]() .
.
Kontrola:
Rozważmy zdarzenie: - strzelec trafia w cel losowo wybranym karabinem.
Według warunku: .
Zgodnie ze wzorem na prawdopodobieństwo całkowite:
Odpowiadać: 0,85
W praktyce skrócony sposób projektowania zadania, który również znasz, jest całkiem do przyjęcia:
Decyzja: zgodnie z klasyczną definicją: ![]() to prawdopodobieństwa wyboru odpowiednio karabinu z celownikiem optycznym i bez celownika optycznego.
to prawdopodobieństwa wyboru odpowiednio karabinu z celownikiem optycznym i bez celownika optycznego.
pod warunkiem, ![]() – prawdopodobieństwa trafienia w cel z poszczególnych typów karabinów.
– prawdopodobieństwa trafienia w cel z poszczególnych typów karabinów.
Zgodnie ze wzorem na prawdopodobieństwo całkowite:
jest prawdopodobieństwo, że strzelec trafi w cel z losowo wybranego karabinu.
Odpowiadać: 0,85
Następujące zadanie do samodzielnego rozwiązania:
Zadanie 4
Silnik pracuje w trzech trybach: normalnym, wymuszonym i biegu jałowym. W trybie bezczynności prawdopodobieństwo jego awarii wynosi 0,05, w trybie normalnym - 0,1, aw trybie wymuszonym - 0,7. 70% czasu silnik pracuje w trybie normalnym, a 20% w trybie wymuszonym. Jakie jest prawdopodobieństwo awarii silnika podczas pracy?
Na wszelki wypadek przypomnę - aby uzyskać prawdopodobieństwo, procenty należy podzielić przez 100. Bądź bardzo ostrożny! Zgodnie z moimi obserwacjami często próbuje się pomylić warunki problemów dla wzoru na prawdopodobieństwo całkowite; i specjalnie wybrałem taki przykład. Zdradzę Ci sekret - sam prawie się pogubiłem =)
Rozwiązanie na koniec lekcji (sformułowane w skrócie)
Zagadnienia dla formuł Bayesa
Materiał jest ściśle powiązany z treścią poprzedniego akapitu. Niech zdarzenie nastąpi w wyniku realizacji jednej z hipotez ![]() . Jak określić prawdopodobieństwo, że dana hipoteza miała miejsce?
. Jak określić prawdopodobieństwo, że dana hipoteza miała miejsce?
Jeśli się uwzględni tamto wydarzenie już się stało, prawdopodobieństwa hipotez przeceniony zgodnie z formułami, które otrzymały imię angielskiego księdza Thomasa Bayesa:
![]()
![]() - prawdopodobieństwo, że hipoteza miała miejsce;
- prawdopodobieństwo, że hipoteza miała miejsce; ![]() - prawdopodobieństwo, że hipoteza miała miejsce;
- prawdopodobieństwo, że hipoteza miała miejsce;
…![]() jest prawdopodobieństwem, że hipoteza była prawdziwa.
jest prawdopodobieństwem, że hipoteza była prawdziwa.
Na pierwszy rzut oka wydaje się to kompletnym absurdem – po co przeliczać prawdopodobieństwa hipotez, skoro są one już znane? Ale w rzeczywistości jest różnica:
- to apriorycznie(szacowany zanim testy) prawdopodobieństwa.
- to a posteriori(szacowany po testy) prawdopodobieństwa tych samych hipotez, przeliczone w związku z „nowo odkrytymi okolicznościami” – biorąc pod uwagę fakt, że zdarzenie stało się.
Spójrzmy na tę różnicę na konkretnym przykładzie:
Zadanie 5
Do magazynu trafiły 2 partie produktów: pierwsza - 4000 sztuk, druga - 6000 sztuk. Średni odsetek produktów niestandardowych w pierwszej partii wynosi 20%, aw drugiej - 10%. Wybrany losowo z magazynu produkt okazał się standardowy. Znajdź prawdopodobieństwo, że jest to: a) z pierwszej partii, b) z drugiej partii.
Pierwsza część rozwiązania polega na wykorzystaniu wzoru na prawdopodobieństwo całkowite. Innymi słowy, obliczenia przeprowadza się przy założeniu, że test jeszcze nie wyprodukowany i wydarzenie "produkt okazał się standardowy" aż nadejdzie.
Rozważmy dwie hipotezy:
- wybrany losowo produkt będzie pochodził z 1 partii;
- wybrany losowo produkt będzie pochodził z 2 partii.
Razem: 4000 + 6000 = 10000 pozycji w magazynie. Zgodnie z klasyczną definicją:
.
Kontrola:
Rozważmy zdarzenie zależne: – przedmiot pobrany losowo z magazynu Wola standard.
W pierwszej partii 100% - 20% = 80% produktów standardowych, a więc: ![]() jeśli się uwzględniże należy do 1. partii.
jeśli się uwzględniże należy do 1. partii.
Podobnie w drugiej partii 100% - 10% = 90% produktów standardowych i ![]() jest prawdopodobieństwem, że losowo wybrany towar w magazynie będzie towarem standardowym jeśli się uwzględniże należy do drugiej partii.
jest prawdopodobieństwem, że losowo wybrany towar w magazynie będzie towarem standardowym jeśli się uwzględniże należy do drugiej partii.
Zgodnie ze wzorem na prawdopodobieństwo całkowite:
to prawdopodobieństwo, że produkt wybrany losowo z magazynu będzie produktem standardowym.
Część druga. Załóżmy, że produkt pobrany losowo z magazynu okazał się standardem. Ta fraza jest bezpośrednio wyrażona w warunku i stwierdza fakt, że zdarzenie wystąpił.
Zgodnie ze wzorami Bayesa:
a) - prawdopodobieństwo, że wybrany produkt standardowy należy do partii 1;
b) - prawdopodobieństwo, że wybrany produkt standardowy należy do drugiej partii.
Później przeszacowanie hipotezy oczywiście wciąż się tworzą pełna grupa:![]() (badanie;-))
(badanie;-))
Odpowiadać: ![]()
Iwan Wasiljewicz, który ponownie zmienił zawód i został dyrektorem zakładu, pomoże nam zrozumieć znaczenie ponownej oceny hipotez. Wie, że dzisiaj 1. sklep wysłał do magazynu 4000 sztuk, a 2. sklep 6000 produktów i przychodzi się upewnić. Załóżmy, że wszystkie produkty są tego samego typu i znajdują się w tym samym pojemniku. Oczywiście Iwan Wasiljewicz wcześniej obliczył, że produkt, który teraz usunie do weryfikacji, najprawdopodobniej zostanie wyprodukowany w pierwszym warsztacie iz prawdopodobieństwem w drugim. Ale gdy wybrany przedmiot okazuje się być standardowy, woła: „Co za fajna śruba! - został raczej wydany przez warsztat 2. Zatem prawdopodobieństwo drugiej hipotezy jest przeszacowane lepsza strona, a prawdopodobieństwo pierwszej hipotezy jest niedoszacowane: . I to przeszacowanie nie jest bezpodstawne - w końcu 2. warsztat nie tylko wyprodukował więcej produktów, ale także działa 2 razy lepiej!
Mówisz, czysty subiektywizm? Częściowo - tak, zresztą sam Bayes zinterpretował a posteriori prawdopodobieństwa jak poziom zaufania. Jednak nie wszystko jest takie proste - w podejściu bayesowskim jest ziarno obiektywne. W końcu prawdopodobieństwo, że produkt będzie standardowy (0,8 i 0,9 odpowiednio dla 1. i 2. sklepu) to wstępny(z góry) i średni szacunki. Ale mówiąc filozoficznie, wszystko płynie, wszystko się zmienia, łącznie z prawdopodobieństwem. Całkiem możliwe, że w czasie studiów bardziej udany 2. sklep zwiększył odsetek produktów standardowych (i/lub pierwszy sklep obniżony), a jeśli sprawdzisz więcej lub wszystkie 10 tysięcy pozycji w magazynie, to przeszacowane wartości będą znacznie bliższe prawdy.
Nawiasem mówiąc, jeśli Iwan Wasiljewicz wyodrębni niestandardową część, to odwrotnie - będzie „podejrzewał” coraz mniej pierwszy sklep - drugi. Proponuję sprawdzić to samemu:
Zadanie 6
Do magazynu trafiły 2 partie produktów: pierwsza - 4000 sztuk, druga - 6000 sztuk. Średni procent produktów niestandardowych w pierwszej partii wynosi 20%, w drugiej - 10%. Produkt pobrany losowo z magazynu okazał się być nie standard. Znajdź prawdopodobieństwo, że jest to: a) z pierwszej partii, b) z drugiej partii.
Warunek wyróżnią dwie litery, które zaznaczyłem pogrubioną czcionką. Problem można rozwiązać od podstaw lub wykorzystać wyniki wcześniejszych obliczeń. W próbce mam kompletne rozwiązanie, ale tak, aby formalnie nie pokrywało się z Zadaniem nr 5, wydarzeniem „Produkt pobrany losowo z magazynu będzie niestandardowy” Oznaczone symbolem .
Bayesowski schemat ponownej oceny prawdopodobieństwa występuje wszędzie i jest aktywnie wykorzystywany przez różnego rodzaju oszustów. Rozważmy trzyliterową spółkę akcyjną, która stała się powszechnie znana, która przyciąga depozyty ludności, rzekomo gdzieś je inwestuje, regularnie wypłaca dywidendy itp. Co się dzieje? Mija dzień za dniem, miesiąc za miesiącem, a coraz więcej nowych faktów, przekazywanych za pośrednictwem reklamy i ustnie, tylko zwiększa poziom zaufania do piramidy finansowej (ponowna ocena bayesowska z powodu przeszłych wydarzeń!). Oznacza to, że w oczach deponentów istnieje stały wzrost prawdopodobieństwa, że "to poważny urząd"; natomiast prawdopodobieństwo hipotezy przeciwnej („to zwykli oszuści”) oczywiście maleje i maleje. Reszta, jak sądzę, jest jasna. Warto zauważyć, że zdobyta reputacja daje organizatorom czas na skuteczne ukrycie się przed Iwanem Wasiljewiczem, który został nie tylko bez partii śrub, ale także bez spodni.
Do nie mniej interesujących przykładów wrócimy nieco później, ale na razie być może najczęstszy przypadek z trzema hipotezami jest następny w kolejce:
Zadanie 7
Lampy elektryczne są produkowane w trzech fabrykach. Pierwsza fabryka produkuje 30% ogólnej liczby lamp, druga - 55%, a trzecia - resztę. Produkty 1. zakładu zawierają 1% wadliwych lamp, 2. - 1,5%, 3. - 2%. Sklep otrzymuje produkty ze wszystkich trzech fabryk. Zakupiona przeze mnie lampa okazała się wadliwa. Jakie jest prawdopodobieństwo, że została ona wyprodukowana przez zakład nr 2?
Zauważ, że w problemach dotyczących formuł Bayesa w warunku koniecznie Niektóre co się stało zdarzenie, w tym przypadku zakup lampy.
Wydarzenia wzrosły i decyzja wygodniej jest ułożyć w stylu „szybkim”.
Algorytm jest dokładnie taki sam: w pierwszym kroku znajdujemy prawdopodobieństwo, że zakupiona lampa będzie będzie wadliwy.
Korzystając z danych początkowych, przekładamy procenty na prawdopodobieństwa:
to prawdopodobieństwo, że lampa jest produkowana odpowiednio przez pierwszą, drugą i trzecią fabrykę.
Kontrola:
Podobnie: - prawdopodobieństwa wyprodukowania wadliwej lampy dla poszczególnych fabryk.
Zgodnie ze wzorem na prawdopodobieństwo całkowite:
- prawdopodobieństwo, że zakupiona lampa będzie wadliwa.
Krok drugi. Niech zakupiona lampa będzie wadliwa (zdarzenie miało miejsce)
Zgodnie ze wzorem Bayesa: ![]() - prawdopodobieństwo, że zakupiona wadliwa lampa jest wyprodukowana przez drugą fabrykę
- prawdopodobieństwo, że zakupiona wadliwa lampa jest wyprodukowana przez drugą fabrykę
Odpowiadać:
Dlaczego początkowe prawdopodobieństwo drugiej hipotezy wzrosło po ponownej ocenie? W końcu drugi zakład produkuje lampy średniej jakości (pierwszy lepszy, trzeci gorszy). Dlaczego więc wzrosła a posteriori prawdopodobieństwo, że wadliwa lampa pochodzi z drugiej fabryki? Nie wynika to już z „reputacji”, ale z wielkości. Ponieważ zakład nr 2 wyprodukował największą liczbę lamp, obwiniają to (przynajmniej subiektywnie): „najprawdopodobniej ta wadliwa lampa jest stamtąd”.
Warto zauważyć, że prawdopodobieństwa pierwszej i trzeciej hipotezy zostały przeszacowane w oczekiwanych kierunkach i zrównały się:
Kontrola: ![]() , co należało zweryfikować.
, co należało zweryfikować.
Nawiasem mówiąc, o niedocenianych i przecenianych:
Zadanie 8
W grupa studencka 3 osoby mają wysoki poziom wyszkolenia, 19 osób średni poziom i 3 osoby niski poziom. Prawdopodobieństwa udana dostawa egzaminu dla tych uczniów wynoszą odpowiednio: 0,95; 0,7 i 0,4. Wiadomo, że jakiś student zdał egzamin. Jakie jest prawdopodobieństwo, że:
a) był bardzo dobrze przygotowany;
b) był średnio przygotowany;
c) był źle przygotowany.
Wykonaj obliczenia i przeanalizuj wyniki ponownej oceny hipotez.
Zadanie jest bliskie rzeczywistości i jest szczególnie prawdopodobne dla grupy studentów niestacjonarnych, gdzie nauczyciel praktycznie nie zna możliwości tego lub innego ucznia. W takim przypadku wynik może spowodować dość nieoczekiwane konsekwencje. (szczególnie na egzaminy w I semestrze). Jeśli źle przygotowany uczeń ma szczęście dostać bilet, to nauczyciel prawdopodobnie uzna go za dobrego ucznia lub nawet silnego ucznia, co zaprocentuje w przyszłości (oczywiście trzeba „podnieść poprzeczkę” i utrzymać swój wizerunek). Jeśli student uczył się, stłoczył, powtarzał przez 7 dni i 7 nocy, ale miał po prostu pecha, to dalsze wydarzenia mogą potoczyć się w najgorszy możliwy sposób – z licznymi powtórkami i balansowaniem na granicy odlotu.
Nie trzeba dodawać, że reputacja jest najważniejszym kapitałem, to nie przypadek, że wiele korporacji nosi imiona i nazwiska swoich ojców założycieli, którzy prowadzili biznes 100-200 lat temu i zasłynęli z nienagannej reputacji.
Tak, podejście bayesowskie do pewnego stopnia subiektywne, ale… tak działa życie!
Połączmy materiał z końcowym przykładem przemysłowym, w którym opowiem o technicznych subtelnościach rozwiązania, które jeszcze nie zostały napotkane:
Zadanie 9
Trzy warsztaty zakładu produkują części tego samego typu, które są montowane we wspólnym pojemniku do montażu. Wiadomo, że pierwszy sklep produkuje 2 razy więcej części niż drugi i 4 razy więcej niż trzeci. W pierwszym warsztacie wada wynosi 12%, w drugim 8%, w trzecim 4%. W celu kontroli jedna część jest pobierana z pojemnika. Jakie jest prawdopodobieństwo, że będzie wadliwy? Jakie jest prawdopodobieństwo, że wyjęta wadliwa część została wyprodukowana przez trzeci warsztat?
Taki Ivan Vasilyevich znowu na koniu =) Film musi mieć szczęśliwe zakończenie =)
Decyzja: w przeciwieństwie do zadań nr 5-8, tutaj postawione jest wprost pytanie, które rozwiązuje się za pomocą wzoru na prawdopodobieństwo całkowite. Ale z drugiej strony warunek jest trochę „zaszyfrowany”, a szkolna umiejętność układania najprostszych równań pomoże nam rozwiązać ten rebus. Dla „x” wygodnie jest przyjąć najmniejszą wartość:
Niech będzie udziałem części wyprodukowanych przez trzeci warsztat.
Zgodnie z warunkiem pierwszy warsztat produkuje 4 razy więcej niż trzeci warsztat, więc udział pierwszego warsztatu wynosi .
Ponadto pierwszy warsztat wytwarza 2 razy więcej produktów niż drugi warsztat, co oznacza, że udział tego drugiego: .
Zróbmy i rozwiążmy równanie:
A więc: - prawdopodobieństwo, że część wyjęta z pojemnika została wydana odpowiednio przez 1., 2. i 3. warsztat.
Sterowanie: . Ponadto ponowne spojrzenie na frazę nie będzie zbyteczne „Wiadomo, że pierwszy warsztat wytwarza produkty 2 razy więcej niż drugi warsztat i 4 razy więcej niż trzeci warsztat” i upewnij się, że otrzymane prawdopodobieństwa rzeczywiście odpowiadają temu warunkowi.
Dla „X” początkowo można było wziąć udział 1. sklepu lub udział 2. sklepu - prawdopodobieństwa wyjdą takie same. Ale w ten czy inny sposób najtrudniejszy odcinek został zaliczony, a rozwiązanie jest na dobrej drodze:
Z warunku znajdujemy:
- prawdopodobieństwo wyprodukowania wadliwej części dla odpowiednich warsztatów.
Zgodnie ze wzorem na prawdopodobieństwo całkowite: ![]() jest prawdopodobieństwem, że część wylosowana z pojemnika będzie niestandardowa.
jest prawdopodobieństwem, że część wylosowana z pojemnika będzie niestandardowa.
Pytanie drugie: jakie jest prawdopodobieństwo, że wymontowana wadliwa część została wyprodukowana przez trzeci warsztat? W tym pytaniu zakłada się, że część została już usunięta i została uznana za wadliwą. Ponownie oceniamy hipotezę za pomocą wzoru Bayesa:  jest pożądanym prawdopodobieństwem. Całkiem oczekiwane - w końcu trzeci warsztat produkuje nie tylko najmniejszy udział części, ale także prowadzi jakością!
jest pożądanym prawdopodobieństwem. Całkiem oczekiwane - w końcu trzeci warsztat produkuje nie tylko najmniejszy udział części, ale także prowadzi jakością!
W tym przypadku musiałem uprościć ułamek czteropiętrowy, co w problemach ze wzorami Bayesa trzeba robić dość często. Ale na tę lekcję jakoś przypadkowo wybrałem przykłady, w których można wykonać wiele obliczeń bez zwykłych ułamków.
Ponieważ w warunku nie ma punktów „a” i „be”, lepiej opatrzyć odpowiedź komentarzem tekstowym:
Odpowiadać: ![]() - prawdopodobieństwo, że wyjęta z pojemnika część będzie wadliwa; - prawdopodobieństwo, że wymontowana wadliwa część została wydana przez 3. warsztat.
- prawdopodobieństwo, że wyjęta z pojemnika część będzie wadliwa; - prawdopodobieństwo, że wymontowana wadliwa część została wydana przez 3. warsztat.
Jak widać, zadania dotyczące formuły prawdopodobieństwa całkowitego i formuły Bayesa są dość proste i prawdopodobnie z tego powodu tak często próbują skomplikować warunek, o którym wspomniałem już na początku artykułu.
Dodatkowe przykłady znajdują się w pliku z gotowe rozwiązania dla F.P.V. i wzory Bayesa, ponadto są zapewne tacy, którzy pragną głębiej zapoznać się z tym tematem w innych źródłach. A temat jest naprawdę bardzo ciekawy - ile jest wart sam paradoks Bayesa, co uzasadnia codzienną radę, że jeśli u człowieka zdiagnozowano rzadką chorobę, to ma sens, aby przeprowadził drugie, a nawet dwa powtórne niezależne badania. Wydawać by się mogło, że robią to wyłącznie z desperacji… – ale nie! Ale nie mówmy o smutnych rzeczach.
jest prawdopodobieństwem, że losowo wybrany student zda egzamin.
Pozwól studentowi zdać egzamin. Zgodnie ze wzorami Bayesa:
a)
b)
w)
Badanie:
Odpowiadać : Formuła Bayesa:
Prawdopodobieństwa P(H i) hipotez H i nazywane są prawdopodobieństwami a priori - prawdopodobieństwami przed eksperymentami.
Prawdopodobieństwa P(A/H i) nazywane są prawdopodobieństwami a posteriori - prawdopodobieństwami hipotez Hi udoskonalonych w wyniku eksperymentu.
Przykład 1. Urządzenie można złożyć z części wysokiej jakości oraz z części zwykłej jakości. Około 40% urządzeń składa się z części wysokiej jakości. Jeżeli urządzenie jest zmontowane z części wysokiej jakości, jego niezawodność (prawdopodobieństwo bezawaryjnej pracy) w czasie t wynosi 0,95; jeśli z części zwykłej jakości - jego niezawodność wynosi 0,7. Urządzenie zostało przetestowane przez czas t i działało bez zarzutu. Znajdź prawdopodobieństwo, że jest zmontowany z części wysokiej jakości.
Decyzja. Możliwe są dwie hipotezy: H 1 - urządzenie jest zmontowane z części wysokiej jakości; H 2 - urządzenie składa się z części zwykłej jakości. Prawdopodobieństwa tych hipotez przed eksperymentem: P(H 1) = 0,4, P(H 2) = 0,6. W wyniku eksperymentu zaobserwowano zdarzenie A – urządzenie pracowało bez zarzutu przez czas t. Prawdopodobieństwa warunkowe tego zdarzenia przy hipotezach H 1 i H 2 wynoszą: P(A|H 1) = 0,95; P(A|H2) = 0,7. Korzystając ze wzoru (12), znajdujemy prawdopodobieństwo hipotezy H 1 po eksperymencie:
![]()
Przykład nr 2. Dwóch strzelców niezależnie strzela do tego samego celu, każdy oddając jeden strzał. Prawdopodobieństwo trafienia w cel dla pierwszego strzelca wynosi 0,8, dla drugiego 0,4. Po strzale w tarczy znaleziono jedną dziurę. Zakładając, że dwóch strzelców nie może trafić w ten sam punkt, znajdź prawdopodobieństwo, że pierwszy strzelec trafił w cel.
Decyzja. Niech wydarzeniem A będzie jedna dziura znaleziona w celu po strzale. Przed rozpoczęciem strzelania możliwe są hipotezy:
H 1 - ani pierwszy, ani drugi strzelec nie trafi, prawdopodobieństwo tej hipotezy: P(H 1) = 0,2 0,6 = 0,12.
H 2 - obaj strzelcy trafią, P(H 2) = 0,8 0,4 = 0,32.
H 3 - pierwszy strzelec trafi, a drugi nie trafi, P(H 3) = 0,8 0,6 = 0,48.
H 4 - pierwszy strzelec nie trafi, ale trafi drugi, P (H 4) = 0,2 0,4 = 0,08.
Warunkowe prawdopodobieństwa zdarzenia A przy tych hipotezach to:
Po doświadczeniu hipotezy H 1 i H 2 stają się niemożliwe, a prawdopodobieństwa hipotez H 3 i H 4
będzie równy:
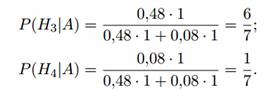
Jest więc najbardziej prawdopodobne, że cel zostanie trafiony przez pierwszego strzelca.
Przykład nr 3. W hali montażowej do urządzenia podłączony jest silnik elektryczny. Silniki elektryczne dostarczane są przez trzech producentów. W magazynie znajduje się odpowiednio 19,6 i 11 silników elektrycznych wymienionych zakładów, które mogą pracować bezawaryjnie do końca okresu gwarancyjnego odpowiednio z prawdopodobieństwem 0,85, 0,76 i 0,71. Robotnik losowo bierze jeden silnik i montuje go na urządzeniu. Znajdź prawdopodobieństwo, że zamontowany i działający bezawaryjnie silnik elektryczny do końca okresu gwarancyjnego został dostarczony odpowiednio przez pierwszego, drugiego lub trzeciego producenta.
Decyzja. Pierwsza próba to wybór silnika elektrycznego, druga to praca silnika elektrycznego w okresie gwarancyjnym. Rozważ następujące zdarzenia:
A - silnik elektryczny pracuje bez zarzutu do końca okresu gwarancyjnego;
H 1 - monter zabierze silnik z produktów pierwszego zakładu;
H 2 - monter zabierze silnik z produktów drugiego zakładu;
H 3 - monter zabierze silnik z produktów trzeciego zakładu.
Prawdopodobieństwo zdarzenia A oblicza się ze wzoru na prawdopodobieństwo całkowite:
Prawdopodobieństwa warunkowe są określone w opisie problemu:
Znajdźmy prawdopodobieństwa
Korzystając ze wzorów Bayesa (12), obliczamy prawdopodobieństwa warunkowe hipotez H i:

Przykład nr 4. Prawdopodobieństwa, że podczas pracy systemu składającego się z trzech elementów, elementy o numerach 1, 2 i 3 ulegną awarii, są powiązane jako 3:2:5. Prawdopodobieństwa wykrycia awarii tych elementów wynoszą odpowiednio 0,95; 0,9 i 0,6.
b) W warunkach tego zadania wykryto awarię podczas pracy systemu. Który element jest najbardziej narażony na awarię?
Decyzja.
Niech A będzie zdarzeniem niepowodzenia. Wprowadźmy system hipotez H1 – awaria pierwszego elementu, H2 – awaria drugiego elementu, H3 – awaria trzeciego elementu.
Znajdujemy prawdopodobieństwa hipotez:
P(H1) = 3/(3+2+5) = 0,3
P(H2) = 2/(3+2+5) = 0,2
P(H3) = 5/(3+2+5) = 0,5
W zależności od warunku problemu, prawdopodobieństwa warunkowe zdarzenia A są następujące:
P(A|H1) = 0,95, P(A|H2) = 0,9, P(A|H3) = 0,6
a) Znajdź prawdopodobieństwo wykrycia awarii w systemie.
P(A) = P(H1)*P(A|H1) + P(H2)*P(A|H2) + P(H3)*P(A|H3) = 0,3*0,95 + 0,2*0,9 + 0,5 *0,6 = 0,765
b) W warunkach tego zadania wykryto awarię podczas pracy systemu. Który element jest najbardziej narażony na awarię?
P1 = P(H1)*P(A|H1)/ P(A) = 0,3*0,95 / 0,765 = 0,373
P2 = P(H2)*P(A|H2)/ P(A) = 0,2*0,9 / 0,765 = 0,235
P3 = P(H3)*P(A|H3)/ P(A) = 0,5*0,6 / 0,765 = 0,392
Maksymalne prawdopodobieństwo trzeciego elementu.
Kim jest Bayes? A co to ma wspólnego z zarządzaniem? – może poprzedzić całkiem słuszne pytanie. Na razie uwierzcie mi na słowo: to bardzo ważne!.. i ciekawe (przynajmniej dla mnie).
W jakim paradygmacie działa większość menedżerów: jeśli coś obserwuję, jakie wnioski mogę z tego wyciągnąć? Czego uczy Bayes: co właściwie musi być, żebym to coś zaobserwował? Tak rozwijają się wszystkie nauki i pisze o tym (cytuję z pamięci): człowiek, który nie ma w głowie teorii, będzie uciekał od jednego pomysłu do drugiego pod wpływem różnych zdarzeń (obserwacji). Nie bez powodu mówią: nie ma nic bardziej praktycznego niż dobra teoria.
Przykład z praktyki. Mój podwładny popełnia błąd, a mój kolega (kierownik innego działu) mówi, że konieczne byłoby wywarcie wpływu menedżerskiego na niedbałego pracownika (innymi słowy ukarać / skarcić). A wiem, że ten pracownik wykonuje miesięcznie 4-5 tys. tego samego typu operacji iw tym czasie popełnia nie więcej niż 10 błędów. Czujesz różnicę w paradygmacie? Kolega reaguje na obserwację, a ja mam a priori wiedzę, że pracownik popełnia pewną ilość błędów, więc kolejny nie wpłynął na tę wiedzę… Teraz, jeśli na koniec miesiąca okaże się, że są np. przykładowo 15 takich błędów!.. To już stanie się powodem do zbadania przyczyn niezgodności z normami.
Przekonany o znaczeniu podejścia bayesowskiego? Zaintrygowany? Mam nadzieję". A teraz mucha w maści. Niestety, idee bayesowskie rzadko są podawane od razu. Szczerze mówiąc, miałem pecha, gdyż zapoznałem się z tymi ideami za pośrednictwem literatury popularnej, po przeczytaniu której pozostało wiele pytań. Planując napisać notatkę, zebrałem wszystko, co wcześniej nakreśliłem według Bayesa, a także przestudiowałem to, co piszą w Internecie. Przedstawiam wam moje najlepsze przypuszczenia na ten temat. Wprowadzenie do prawdopodobieństwa bayesowskiego.
Wyprowadzenie twierdzenia Bayesa
Rozważmy następujący eksperyment: nazywamy dowolną liczbę leżącą na odcinku i ustalamy, kiedy ta liczba jest na przykład między 0,1 a 0,4 (rys. 1a). Prawdopodobieństwo tego zdarzenia jest równe stosunkowi długości odcinka do całkowitej długości odcinka, pod warunkiem, że występowanie liczb na odcinku równo prawdopodobne. Matematycznie można to zapisać p(0,1 <= x <= 0,4) = 0,3, или кратко R(X) = 0,3, gdzie R- prawdopodobieństwo, X jest zmienną losową z zakresu , X jest zmienną losową z zakresu . Oznacza to, że prawdopodobieństwo trafienia w segment wynosi 30%.

Ryż. 1. Graficzna interpretacja prawdopodobieństw
Rozważmy teraz kwadrat x (ryc. 1b). Powiedzmy, że musimy nazwać pary liczb ( x, y), z których każdy jest większy od zera i mniejszy od jednego. Prawdopodobieństwo, że x(pierwsza liczba) będzie w segmencie (niebieski obszar 1), równy stosunkowi obszaru niebieskiego obszaru do obszaru całego kwadratu, czyli (0,4 - 0,1 ) * (1 - 0) / (1 * 1) = 0, 3, czyli te same 30%. Prawdopodobieństwo, że y znajduje się wewnątrz segmentu (zielony obszar 2) jest równy stosunkowi obszaru zielonego obszaru do obszaru całego kwadratu p(0,5 <= y <= 0,7) = 0,2, или кратко R(Y) = 0,2.
Czego można się dowiedzieć o wartościach w tym samym czasie x oraz y. Na przykład, jakie jest prawdopodobieństwo, że oba x oraz y znajdują się w odpowiednich danych segmentach? Aby to zrobić, musisz obliczyć stosunek powierzchni domeny 3 (przecięcie zielonych i niebieskich pasków) do powierzchni całego kwadratu: p(X, Y) = (0,4 – 0,1) * (0,7 – 0,5) / (1 * 1) = 0,06.
Załóżmy teraz, że chcemy wiedzieć, jakie jest prawdopodobieństwo, że y jest w przedziale jeśli x jest już w zasięgu. Oznacza to, że w rzeczywistości mamy filtr i kiedy wywołujemy pary ( x, y), to natychmiast odrzucamy te pary, które nie spełniają warunku znalezienia x w zadanym przedziale, a następnie z przefiltrowanych par liczymy te, dla których y spełnia nasz warunek i rozważ prawdopodobieństwo jako stosunek liczby par, dla których y leży w powyższym segmencie do całkowitej liczby filtrowanych par (czyli dla których x leży w segmencie). Możemy zapisać to prawdopodobieństwo jako p(Y|X w X trafienie w dziesiątkę”. Oczywiście prawdopodobieństwo to jest równe stosunkowi pola obszaru 3 do pola obszaru niebieskiego 1. Pole obszaru 3 wynosi (0,4 - 0,1) * (0,7 - 0,5) = 0,06, oraz obszar niebieskiego obszaru 1 ( 0,4 - 0,1) * (1 - 0) = 0,3, wtedy ich stosunek wynosi 0,06 / 0,3 = 0,2. Innymi słowy, prawdopodobieństwo znalezienia y na segmencie, pod warunkiem że x należy do segmentu p(Y|X) = 0,2.
W poprzednim akapicie właściwie sformułowaliśmy tożsamość: p(Y|X) = p(X, Y) /p( X). Brzmi: „prawdopodobieństwo trafienia w w zakresie, pod warunkiem, że X trafienie w zasięgu jest równe stosunkowi prawdopodobieństwa jednoczesnego trafienia X w zasięgu i w w zasięgu, do prawdopodobieństwa trafienia X w zakres".
Przez analogię rozważ prawdopodobieństwo p(X|Y). Dzwonimy do par x, y) i odfiltruj te, dla których y leży między 0,5 a 0,7, to prawdopodobieństwo, że x jest w segmencie pod warunkiem, że y należący do segmentu jest równy stosunkowi powierzchni obszaru 3 do obszaru obszaru zielonego 2: p(X|Y) = p(X, Y) / p(Y).
Zauważ, że prawdopodobieństwa p(X, Y) oraz p(Y, X) są równe i oba są równe stosunkowi pola strefy 3 do pola całego kwadratu, ale prawdopodobieństwa p(Y|X) oraz p(X|Y) nie równe; natomiast prawdopodobieństwo p(Y|X) jest równy stosunkowi powierzchni obszaru 3 do obszaru 1, oraz p(X|Y) – domena 3 do domeny 2. Zwróć też na to uwagę p(X, Y) jest często oznaczane jako p(X&Y).
Mamy więc dwie definicje: p(Y|X) = p(X, Y) /p( X) oraz p(X|Y) = p(X, Y) / p(Y)
Zapiszmy te równości jako: p(X, Y) = p(Y|X)*p( X) oraz p(X, Y) = p(X|Y) * p(Y)
Skoro lewe strony są równe, to i prawe: p(Y|X)*p( X) = p(X|Y) * p(Y)
Lub możemy przepisać ostatnią równość jako:

To jest twierdzenie Bayesa!
Czy to możliwe, że takie proste (prawie tautologiczne) przekształcenia dają początek wielkiemu twierdzeniu!? Nie spiesz się z wnioskami. Porozmawiajmy jeszcze raz o tym, co mamy. Istniało pewne początkowe (a priori) prawdopodobieństwo R(X) że zmienna losowa X równomiernie rozłożony na odcinku mieści się w przedziale X. Jakieś wydarzenie miało miejsce Y, w wyniku czego otrzymaliśmy prawdopodobieństwo a posteriori tej samej zmiennej losowej X: R(X|Y), a prawdopodobieństwo to różni się od R(X) przez współczynnik . Wydarzenie Y zwane dowodami, mniej lub bardziej potwierdzającymi lub odrzucającymi X. Ten współczynnik jest czasami nazywany moc dowodu. Im silniejszy dowód, tym bardziej fakt obserwacji Y zmienia prawdopodobieństwo wcześniejsze, tym bardziej późniejsze prawdopodobieństwo różni się od wcześniejszego. Jeśli dowody są słabe, późniejszy jest prawie równy wcześniejszemu.
Formuła Bayesa dla dyskretnych zmiennych losowych
W poprzedniej sekcji wyprowadziliśmy wzór Bayesa dla ciągłych zmiennych losowych x i y zdefiniowanych w przedziale . Rozważmy przykład z dyskretnymi zmiennymi losowymi, z których każda przyjmuje dwie możliwe wartości. W trakcie rutynowych badań lekarskich stwierdzono, że w wieku czterdziestu lat 1% kobiet choruje na raka piersi. 80% kobiet z rakiem ma pozytywny wynik mammografii. 9,6% zdrowych kobiet uzyskuje również pozytywne wyniki mammografii. W trakcie badania kobieta w tej grupie wiekowej uzyskała pozytywny wynik mammografii. Jakie jest prawdopodobieństwo, że faktycznie ma raka piersi?
Przebieg rozumowania/obliczeń jest następujący. Spośród 1% pacjentów z rakiem mammografia da 80% wyników pozytywnych = 1% * 80% = 0,8%. Spośród 99% zdrowych kobiet mammografia da 9,6% wyników pozytywnych = 99% * 9,6% = 9,504%. W sumie spośród 10,304% (9,504% + 0,8%) z pozytywnym wynikiem mammografii tylko 0,8% jest chorych, a pozostałe 9,504% to osoby zdrowe. Zatem prawdopodobieństwo, że kobieta z pozytywnym wynikiem mammografii ma raka, wynosi 0,8% / 10,304% = 7,764%. Myślałeś, że 80%?
W naszym przykładzie wzór Bayesa przyjmuje następującą postać:
Porozmawiajmy jeszcze raz o „fizycznym” znaczeniu tej formuły. X jest zmienną losową (diagnoza), która przyjmuje następujące wartości: X 1- chory i X 2- zdrowy; Y– zmienna losowa (wynik pomiaru – mammografia), która przyjmuje wartości: Y 1- wynik pozytywny i Y2- wynik negatywny; p(X1)- prawdopodobieństwo zachorowania przed mammografią (prawdopodobieństwo a priori), równe 1%; R(Y 1 |X 1 ) – prawdopodobieństwo pozytywnego wyniku, jeśli pacjent jest chory (prawdopodobieństwo warunkowe, bo musi być określone w warunkach zadania), równe 80%; R(Y 1 |X 2 ) – prawdopodobieństwo uzyskania wyniku pozytywnego, jeśli pacjent jest zdrowy (również prawdopodobieństwo warunkowe), równe 9,6%; p(X2)- prawdopodobieństwo, że pacjentka jest zdrowa przed mammografią (prawdopodobieństwo a priori), równe 99%; p(X 1|Y 1 ) – prawdopodobieństwo, że pacjentka jest chora, biorąc pod uwagę pozytywny wynik mammografii (prawdopodobieństwo późniejsze).
Można zauważyć, że prawdopodobieństwo późniejsze (to, czego szukamy) jest proporcjonalne do prawdopodobieństwa wcześniejszego (początkowego) z nieco bardziej złożonym współczynnikiem  . Jeszcze raz podkreślę. Moim zdaniem jest to fundamentalny aspekt podejścia bayesowskiego. Wymiar ( Y) dodał do początkowo dostępnych (a priori) pewną ilość informacji, która doprecyzowała naszą wiedzę o obiekcie.
. Jeszcze raz podkreślę. Moim zdaniem jest to fundamentalny aspekt podejścia bayesowskiego. Wymiar ( Y) dodał do początkowo dostępnych (a priori) pewną ilość informacji, która doprecyzowała naszą wiedzę o obiekcie.
Przykłady
Aby skonsolidować omówiony materiał, spróbuj rozwiązać kilka problemów.
Przykład 1 Są 3 urny; w pierwszych 3 białych kulach i 1 czarnej; w drugim - 2 białe kule i 3 czarne; w trzecim - 3 białe kule. Ktoś przypadkowo podchodzi do jednej z urn i losuje z niej 1 kulę. Ta piłka jest biała. Znajdź prawdopodobieństwo późniejsze, że kula została wylosowana z 1, 2, 3 urny.
Decyzja. Mamy trzy hipotezy: H 1 = (wybrana pierwsza urna), H 2 = (wybrana druga urna), H 3 = (wybrana trzecia urna). Ponieważ urna jest wybierana losowo, prawdopodobieństwa a priori hipotez są następujące: Р(Н 1) = Р(Н 2) = Р(Н 3) = 1/3.
W wyniku eksperymentu wystąpiło zdarzenie A = (wyjęto białą kulę z wybranej urny). Prawdopodobieństwa warunkowe zdarzenia A przy hipotezach H 1, H 2, H 3: P(A|H 1) = 3/4, P(A|H 2) = 2/5, P(A|H 3) = 1. Na przykład pierwsza równość brzmi następująco: „prawdopodobieństwo wylosowania kuli białej, jeśli wybrano pierwszą urnę, wynosi 3/4 (ponieważ w pierwszej urnie są 4 kule, a 3 z nich są białe)”.
Stosując wzór Bayesa, znajdujemy późniejsze prawdopodobieństwa hipotez:

Tym samym, w świetle informacji o zajściu zdarzenia A, zmieniły się prawdopodobieństwa hipotez: najbardziej prawdopodobna stała się hipoteza H 3 , najmniej prawdopodobna - hipoteza H 2 .
Przykład 2 Dwóch strzelców niezależnie strzela do tego samego celu, każdy oddając jeden strzał. Prawdopodobieństwo trafienia w cel dla pierwszego strzelca wynosi 0,8, dla drugiego - 0,4. Po strzale w tarczy znaleziono jedną dziurę. Znajdź prawdopodobieństwo, że ten dołek należy do pierwszego strzelca (odrzucamy wynik (oba dołki pokrywały się) jako mało prawdopodobny).
Decyzja. Przed eksperymentem możliwe są następujące hipotezy: H 1 = (ani pierwsza, ani druga strzała nie trafi), H 2 = (obie strzały nie trafią), H 3 - (pierwszy strzelec trafi, a drugi nie ), H 4 = (pierwszy strzelec nie trafi, a drugi trafi). Prawdopodobieństwa a priori hipotez:
P.(H.1) \u003d 0,2 * 0,6 \u003d 0,12; P.(H2) \u003d 0,8 * 0,4 \u003d 0,32; P.(H3) \u003d 0,8 * 0,6 \u003d 0,48; P.(H4) \u003d 0,2 * 0,4 \u003d 0,08.
Prawdopodobieństwa warunkowe obserwowanego zdarzenia A = (w tarczy jest jedna dziura) przy tych hipotezach są następujące: P(A|H 1) = P(A|H 2) = 0; P(A|H 3) = P(A|H 4) = 1
Po doświadczeniu hipotezy H 1 i H 2 stają się niemożliwe, a późniejsze prawdopodobieństwa hipotez H 3 i H 4 zgodnie ze wzorem Bayesa będą następujące:

Bayesa przeciwko spamowi
Formuła Bayesa znalazła szerokie zastosowanie w rozwoju filtrów antyspamowych. Załóżmy, że chcesz wyszkolić komputer w określaniu, które e-maile są spamem. Zaczniemy od słownika i kombinacji wyrazów z wykorzystaniem oszacowań bayesowskich. Stwórzmy najpierw przestrzeń hipotez. Przyjmijmy 2 hipotezy dotyczące dowolnego listu: H A to spam, H B to nie spam, ale zwykły, potrzebny list.
Najpierw „wytrenujmy” nasz przyszły system antyspamowy. Weźmy wszystkie litery, które mamy i podzielmy je na dwa „stosy” po 10 liter. W jednym umieszczamy listy spamowe i nazywamy go stosem H A, w drugim umieszczamy niezbędną korespondencję i nazywamy go stosem H B. Zobaczmy teraz: jakie słowa i frazy znajdują się w spamie i niezbędnych wiadomościach e-mail iz jaką częstotliwością? Te słowa i wyrażenia będą nazywane dowodami i oznaczane przez E 1 , E 2 ... Okazuje się, że powszechnie używane słowa (na przykład słowa „jak”, „twój”) w stosach H A i H B występują w przybliżeniu z ta sama częstotliwość. Tak więc obecność tych słów w liście nie mówi nam nic o tym, do którego stosu on należy (słaby dowód). Przypiszmy tym słowom neutralną wartość oszacowania prawdopodobieństwa „spamu”, powiedzmy 0,5.
Niech fraza „konwersacyjny angielski” pojawi się tylko w 10 literach i częściej w wiadomościach spamowych (na przykład w 7 wiadomościach spamowych na wszystkie 10) niż we właściwych (w 3 na 10). Dajmy tej frazie wyższą ocenę 7/10 za spam i niższą ocenę za zwykłe e-maile: 3/10. I odwrotnie, okazało się, że słowo „kumpel” pojawiało się częściej w zwykłych literach (6 na 10). I tak otrzymaliśmy krótki list: „Przyjacielu! Jak tam twój mówiony angielski?. Spróbujmy ocenić jego „spamowość”. Umieścimy ogólne szacunki P(HA), P(H B) przynależności do każdego stosu, używając nieco uproszczonego wzoru Bayesa i naszych przybliżonych szacunków:
P(HA) = A/(A+B), gdzie A \u003d p a1 * p a2 * ... * pan, B \u003d p b1 * p b2 * ... * p b n \u003d (1 - p a1) * (1 - p a2) * ... * ( 1 - p a).
Tabela 1. Uproszczona (i niepełna) bayesowska ocena pisma

Tym samym nasz hipotetyczny list otrzymał ocenę prawdopodobieństwa przynależności z naciskiem na kierunek „spam”. Czy możemy zdecydować się na wrzucenie listu do jednego ze stosów? Ustalmy progi decyzyjne:
- Założymy, że litera należy do sterty H i, jeśli P(H i) ≥ T.
- Litera nie należy do sterty, jeśli P(H i) ≤ L.
- Jeśli L ≤ P(H i) ≤ T, to nie można podjąć żadnej decyzji.
Możesz wziąć T = 0,95 i L = 0,05. Ponieważ dla danej litery i 0,05< P(H A) < 0,95, и 0,05 < P(H В) < 0,95, то мы не сможем принять решение, куда отнести данное письмо: к спаму (H A) или к нужным письмам (H B). Можно ли улучшить оценку, используя больше информации?
Tak. Obliczmy wynik dla każdego dowodu w inny sposób, tak jak sugerował Bayes. Zostawiać:
F a to całkowita liczba wiadomości spamowych;
F ai to liczba liter z certyfikatem ja w stercie spamu;
Fb to całkowita liczba potrzebnych liter;
F bi to liczba liter z certyfikatem ja w stosie niezbędnych (istotnych) listów.
Wtedy: p ai = fa ai /fa za , p bi = fa bi /F b . P(H A) = A/(A+B), P(H B) = B/(A+B), gdzieА = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n
Należy zauważyć, że wyniki słów dowodowych p ai i p bi stały się obiektywne i można je obliczyć bez udziału człowieka.
Tabela 2. Dokładniejsze (ale niepełne) oszacowanie bayesowskie dla dostępnych cech z listu

Otrzymaliśmy dość określony wynik - z dużym marginesem prawdopodobieństwa literę można przypisać niezbędnym literom, ponieważ P(H B) = 0,997 > T = 0,95. Dlaczego wynik się zmienił? Ponieważ wykorzystaliśmy więcej informacji - wzięliśmy pod uwagę liczbę liter w każdym ze stosów i przy okazji znacznie dokładniej ustaliliśmy oszacowania p ai i p bi. Zostały one określone w taki sam sposób, jak zrobił to sam Bayes, poprzez obliczenie prawdopodobieństw warunkowych. Innymi słowy, p a3 to prawdopodobieństwo, że słowo „kumpel” pojawi się w wiadomości e-mail, biorąc pod uwagę, że wiadomość e-mail należy już do sterty spamu H A . Na wynik nie trzeba było długo czekać - wydaje się, że możemy podjąć decyzję z większą pewnością.
Bayes kontra oszustwo korporacyjne
Ciekawe zastosowanie podejścia bayesowskiego opisał MAGNUS8.
Mój obecny projekt (IS do wykrywania nadużyć w przedsiębiorstwie produkcyjnym) wykorzystuje formułę Bayesa do określenia prawdopodobieństwa wystąpienia nadużycia (oszustwa) w obecności/braku kilku faktów pośrednio przemawiających za hipotezą o możliwości wystąpienia nadużycia. Algorytm jest samouczący się (ze sprzężeniem zwrotnym), tj. przelicza swoje współczynniki (prawdopodobieństwa warunkowe) po faktycznym potwierdzeniu lub braku potwierdzenia oszustwa podczas weryfikacji przez służby bezpieczeństwa gospodarczego.
Warto chyba powiedzieć, że takie metody przy projektowaniu algorytmów wymagają dość wysokiej kultury matematycznej twórcy, bo najmniejszy błąd w wyprowadzeniu i/lub implementacji wzorów obliczeniowych unieważni i zdyskredytuje całą metodę. Szczególnie winne są temu metody probabilistyczne, ponieważ ludzkie myślenie nie jest przystosowane do pracy z kategoriami probabilistycznymi, a co za tym idzie, nie ma „widoczności” i zrozumienia „fizycznego znaczenia” pośrednich i końcowych parametrów probabilistycznych. Takie rozumienie istnieje tylko dla podstawowych pojęć teorii prawdopodobieństwa, a wtedy wystarczy bardzo ostrożnie połączyć i wyprowadzić złożone rzeczy zgodnie z prawami teorii prawdopodobieństwa – zdrowy rozsądek nie pomoże już w przypadku obiektów złożonych. Wiąże się to w szczególności z dość poważnymi bitwami metodologicznymi, jakie toczą się na kartach współczesnych książek z zakresu filozofii prawdopodobieństwa, a także dużą liczbą sofizmatów, paradoksów i ciekawostek na ten temat.
Kolejnym niuansem, z którym musiałem się zmierzyć jest to, że niestety prawie wszystko mniej lub bardziej PRZYDATNE W PRAKTYCE na ten temat jest napisane po angielsku. W źródłach rosyjskojęzycznych istnieje w zasadzie tylko dobrze znana teoria z przykładami demonstracyjnymi tylko dla najbardziej prymitywnych przypadków.
W pełni zgadzam się z ostatnim komentarzem. Na przykład Google, próbując znaleźć coś w rodzaju książki „Prawdopodobieństwo Bayesa”, nie podał niczego zrozumiałego. To prawda, powiedział, że książka ze statystykami bayesowskimi została zakazana w Chinach. (Profesor statystyki Andrew Gelman poinformował na blogu Columbia University, że jego książka, Data Analysis with Regression and Multilevel/Hierarchical Models, została zakazana publikacji w Chinach. text.) Zastanawiam się, czy podobny powód doprowadził do braku książek o bayesowskim Prawdopodobieństwo w Rosji?
Konserwatyzm w procesie przetwarzania informacji przez człowieka
Prawdopodobieństwa określają stopień niepewności. Prawdopodobieństwo, zarówno według Bayesa, jak i naszej intuicji, jest po prostu liczbą od zera do tego, co reprezentuje stopień, w jakim nieco wyidealizowana osoba wierzy, że stwierdzenie jest prawdziwe. Powodem, dla którego dana osoba jest nieco wyidealizowana, jest to, że suma jej prawdopodobieństw dwóch wzajemnie wykluczających się zdarzeń musi być równa prawdopodobieństwu wystąpienia jednego z tych zdarzeń. Właściwość addytywności ma takie implikacje, że niewielu prawdziwych ludzi może je wszystkie dopasować.
Twierdzenie Bayesa jest trywialną konsekwencją własności addytywności, niezaprzeczalną i akceptowaną przez wszystkich probabilistów, Bayesa i innych. Jeden ze sposobów napisania tego jest następujący. Jeśli P(H A |D) jest prawdopodobieństwem późniejszym, że hipoteza A była po zaobserwowaniu danej wartości D, P(HA) jest jej prawdopodobieństwem uprzednim przed zaobserwowaniem danej wartości D, P(D|HA ) jest prawdopodobieństwem, że a dana wartość D będzie obserwowana, jeśli H A jest prawdą, a P(D) jest bezwarunkowym prawdopodobieństwem danej wartości D, to
(1) P(H A |D) = P(D|H A) * P(HA A) / P(D)
P(D) najlepiej traktować jako stałą normalizującą, która powoduje, że późniejsze prawdopodobieństwa sumują się do jedności w wyczerpującym zestawie wzajemnie wykluczających się hipotez, które są rozważane. Jeśli trzeba to obliczyć, może to wyglądać tak:
Częściej jednak P(D) jest raczej eliminowane niż liczone. Wygodnym sposobem na jego wyeliminowanie jest przekształcenie twierdzenia Bayesa w postać relacji prawdopodobieństwo-szansa.
Rozważ inną hipotezę, H B , wykluczającą się wzajemnie z HA i zmień zdanie na jej temat w oparciu o tę samą daną wielkość, która zmieniła twoje zdanie na temat HA. Twierdzenie Bayesa mówi, że
(2) P(H b |D) = P(D|H b) * P(H b) / P(D)
Teraz podzielimy Równanie 1 przez Równanie 2; wynik będzie taki:

gdzie Ω 1 to późniejsze szanse na korzyść HA pod względem H B , Ω 0 to wcześniejsze szanse, a L to liczba znana statystykom jako iloraz prawdopodobieństw. Równanie 3 jest tą samą odpowiednią wersją twierdzenia Bayesa co Równanie 1 i często jest znacznie bardziej przydatne, zwłaszcza w przypadku eksperymentów obejmujących hipotezy. Zwolennicy bayesowscy argumentują, że twierdzenie Bayesa jest formalnie optymalną regułą rewizji opinii w świetle nowych danych.
Interesuje nas porównanie idealnego zachowania określonego przez twierdzenie Bayesa z rzeczywistym zachowaniem ludzi. Aby dać ci wyobrażenie o tym, co to oznacza, spróbujmy przeprowadzić eksperyment z tobą jako podmiotem. Ta torba zawiera 1000 żetonów do pokera. Mam dwie takie torby, jedną z 700 czerwonych i 300 niebieskich żetonów, a drugą z 300 czerwonymi i 700 niebieskimi. Rzuciłem monetą, aby określić, której użyć. Tak więc, jeśli nasze opinie są takie same, Twoje obecne prawdopodobieństwo wylosowania worka z większą liczbą czerwonych żetonów wynosi 0,5. Teraz losowo próbkujesz, wracając po każdym żetonie. W 12 żetonach otrzymujesz 8 czerwonych i 4 niebieskie. Teraz, biorąc pod uwagę wszystko, co wiesz, jakie jest prawdopodobieństwo, że w torbie znalazło się więcej czerwonych? Wyraźnie widać, że jest wyższy niż 0,5. Nie czytaj dalej, dopóki nie zapiszesz swojej oceny.
Jeśli wyglądasz jak typowy przedmiot, Twój wynik mieści się w przedziale od 0,7 do 0,8. Gdybyśmy jednak wykonali odpowiednie obliczenia, odpowiedź wyniosłaby 0,97. Rzeczywiście, bardzo rzadko zdarza się, aby osoba, której wcześniej nie pokazano wpływu konserwatyzmu, doszła do tak wysokiej oceny, nawet jeśli znała twierdzenie Bayesa.
Jeśli proporcja czerwonych żetonów w worku jest R, to prawdopodobieństwo otrzymania r czerwone żetony i ( n-r) niebieski w n próbki ze zwrotem - p r (1–p)n-r. Tak więc w typowym eksperymencie z workiem i żetonem do pokera, jeśli HA oznacza, że udział żetonów czerwonych wynosi r A oraz HB oznacza, że udział jest RB, to iloraz prawdopodobieństwa:

Stosując wzór Bayesa, należy wziąć pod uwagę tylko prawdopodobieństwo rzeczywistej obserwacji, a nie prawdopodobieństwo innych obserwacji, które mógł wykonać, ale tego nie zrobił. Zasada ta ma szerokie implikacje dla wszystkich statystycznych i niestatystycznych zastosowań twierdzenia Bayesa; jest to najważniejsze narzędzie techniczne myślenia bayesowskiego.
Rewolucja bayesowska
Twoi przyjaciele i współpracownicy mówią o czymś, co nazywa się „twierdzeniem Bayesa” lub „regułą Bayesa” lub czymś, co nazywa się myśleniem Bayesa. Oni naprawdę się tym interesują, więc wchodzisz do sieci i znajdujesz stronę o twierdzeniu Bayesa i... To jest równanie. I to wszystko... Dlaczego pojęcie matematyczne budzi taki entuzjazm w umysłach? Jaki rodzaj „rewolucji bayesowskiej” ma miejsce wśród naukowców i twierdzi się, że nawet samo podejście eksperymentalne można określić jako jego szczególny przypadek? Jaki jest sekret, który znają wyznawcy Bayesa? Jakie światło widzą?
Bayesowska rewolucja w nauce nie nastąpiła, ponieważ coraz więcej kognitywistów nagle zaczęło dostrzegać, że zjawiska mentalne mają strukturę bayesowską; nie dlatego, że naukowcy ze wszystkich dziedzin zaczęli stosować metodę bayesowską; ale dlatego, że sama nauka jest szczególnym przypadkiem twierdzenia Bayesa; dowód eksperymentalny jest dowodem bayesowskim. Bayesowscy rewolucjoniści argumentują, że kiedy przeprowadzasz eksperyment i otrzymujesz dowody, które „potwierdzają” lub „obalają” twoją teorię, to potwierdzenie lub obalenie następuje zgodnie z regułami bayesowskimi. Na przykład musisz wziąć pod uwagę nie tylko to, że twoja teoria może wyjaśnić to zjawisko, ale także to, że istnieją inne możliwe wyjaśnienia, które również mogą przewidzieć to zjawisko.
Wcześniej najpopularniejszą filozofią nauki była stara filozofia, wyparta przez rewolucję bayesowską. Pomysł Karla Poppera, że teorie mogą być całkowicie sfałszowane, ale nigdy całkowicie potwierdzone, jest kolejnym szczególnym przypadkiem reguł Bayesa; jeśli p(X|A) ≈ 1 - jeśli teoria trafnie przewiduje, to obserwacja ~X bardzo silnie falsyfikuje A. Z drugiej strony, jeśli p(X|A) ≈ 1 i obserwujemy X, to nie potwierdza teoria bardzo; możliwy jest jakiś inny warunek B, taki, że p(X|B) ≈ 1, przy którym obserwacja X nie dowodzi A, ale dowodzi B. Aby zaobserwować X definitywnie potwierdzające A, musielibyśmy nie wiedzieć, że p( X|A) ≈ 1 i że p(X|~A) ≈ 0, którego nie możemy znać, ponieważ nie możemy rozważyć wszystkich możliwych alternatywnych wyjaśnień. Na przykład, kiedy ogólna teoria względności Einsteina przewyższyła wysoce weryfikowalną teorię grawitacji Newtona, uczyniła wszystkie przewidywania teorii Newtona szczególnym przypadkiem Einsteina.
Podobnie twierdzenie Poppera, że idea musi być falsyfikowalna, można interpretować jako przejaw reguły Bayesa dotyczącej zachowania prawdopodobieństwa; jeśli wynik X jest pozytywnym dowodem na teorię, to wynik ~X musi do pewnego stopnia sfalsyfikować teorię. Jeśli próbujesz zinterpretować zarówno X, jak i ~X jako „popierające” teorię, reguły bayesowskie mówią, że to niemożliwe! Aby zwiększyć prawdopodobieństwo teorii, musisz poddać ją testom, które potencjalnie mogą zmniejszyć jej prawdopodobieństwo; nie jest to tylko reguła wykrywania szarlatanów w nauce, ale konsekwencja Bayesowskiego twierdzenia o prawdopodobieństwie. Z drugiej strony pomysł Poppera, że potrzebne jest tylko falsyfikowanie i żadne potwierdzenie, jest błędny. Twierdzenie Bayesa pokazuje, że falsyfikowanie jest bardzo mocnym dowodem w porównaniu z potwierdzeniem, ale falsyfikacja ma nadal charakter probabilistyczny; nie rządzi się zasadniczo innymi regułami i nie różni się tym od konfirmacji, jak przekonuje Popper.
W ten sposób odkrywamy, że wiele zjawisk w naukach kognitywnych, a także metody statystyczne stosowane przez naukowców, a także sama metoda naukowa, są szczególnymi przypadkami twierdzenia Bayesa. Na tym właśnie polega rewolucja bayesowska.
Witamy w konspiracji Bayesa!
Literatura dotycząca prawdopodobieństwa bayesowskiego
2. Laureat Nagrody Nobla w dziedzinie ekonomii Kahneman (i in.) opisuje we wspaniałej książce wiele różnych zastosowań Bayesa. W samym tylko podsumowaniu tej bardzo obszernej książki naliczyłem 27 odniesień do nazwiska prezbiteriańskiego duchownego. Minimalne formuły. (.. bardzo mi się podobało. Fakt, to skomplikowane, dużo matematyki (a gdzie bez niej), ale poszczególne rozdziały (np. Rozdział 4. Informacje), wyraźnie na temat. Radzę wszystkim. Nawet jeśli matematyka jest trudne dla ciebie, przeczytaj całą linię, pomijając matematykę i łowiąc przydatne ziarna ...
14. (uzupełnienie z dnia 15 stycznia 2017 r), rozdział z książki Tony'ego Crilly'ego. 50 pomysłów, o których musisz wiedzieć. Matematyka.
Fizyk Richard Feynman, laureat Nagrody Nobla, mówiąc o jednym filozofie o szczególnie wielkiej zarozumiałości, powiedział kiedyś: „Wcale nie irytuje mnie filozofia jako nauka, ale przepych, jaki wokół niej powstał. Gdyby tylko filozofowie mogli śmiać się z samych siebie! Gdyby tylko mogli powiedzieć: „Mówię, że jest tak, ale Von Leipzig uważał, że jest inaczej, i on też coś o tym wie”. Gdyby tylko pamiętali, żeby wyjaśnić, że to tylko ich sprawa .
Być może nigdy nie słyszałeś o twierdzeniu Bayesa, ale używałeś go przez cały czas. Na przykład początkowo oszacowałeś prawdopodobieństwo otrzymania podwyżki wynagrodzenia na 50%. Po otrzymaniu pozytywnej opinii od kierownika poprawiłeś swoją ocenę na lepszą i odwrotnie, obniżyłeś ją, jeśli zepsułeś ekspres do kawy w pracy. W ten sposób wartość prawdopodobieństwa jest udoskonalana w miarę gromadzenia informacji.
Główna idea twierdzenia Bayesa polega na uzyskaniu większej dokładności oszacowania prawdopodobieństwa zdarzenia poprzez uwzględnienie dodatkowych danych.
Zasada jest prosta: istnieje wstępne podstawowe oszacowanie prawdopodobieństwa, które jest udoskonalane o więcej informacji.
Formuła Bayesa
Intuicyjne działania są sformalizowane w prostym, ale potężnym równaniu ( Formuła prawdopodobieństwa Bayesa):

Lewa strona równania to oszacowanie a posteriori prawdopodobieństwa zdarzenia A pod warunkiem zajścia zdarzenia B (tzw. prawdopodobieństwo warunkowe).
- ROCZNIE)- prawdopodobieństwo zdarzenia A (podstawowe, estymacja a priori);
- P(B|A) — prawdopodobieństwo (również warunkowe), jakie uzyskamy z naszych danych;
- a P(B) jest stałą normalizacji, która ogranicza prawdopodobieństwo do 1.
To krótkie równanie jest podstawą metoda bayesowska.
Abstrakcyjny charakter zdarzeń A i B nie pozwala nam na jasne zrozumienie znaczenia tej formuły. Aby zrozumieć istotę twierdzenia Bayesa, rozważmy rzeczywisty problem.
Przykład
Jednym z tematów, nad którymi pracuję, jest badanie wzorców snu. Mam dane z dwóch miesięcy zarejestrowane przez zegarek Garmin Vivosmart, pokazujące, o której godzinie kładę się spać i wstaję. Pokaz ostatniego modelu najprawdopodobniej Poniżej przedstawiono rozkład prawdopodobieństwa snu w funkcji czasu (MCMC jest metodą przybliżoną).

Wykres pokazuje prawdopodobieństwo, że śpię, w zależności tylko od czasu. Jak to się zmieni, jeśli weźmiemy pod uwagę czas, w którym pali się światło w sypialni? Aby udoskonalić oszacowanie, potrzebne jest twierdzenie Bayesa. Udoskonalone oszacowanie oparte jest na oszacowaniu a priori i ma postać:

Wyrażenie po lewej to prawdopodobieństwo, że śpię, biorąc pod uwagę, że światło w mojej sypialni jest włączone. Wcześniejsze oszacowanie w danym momencie (pokazane na powyższym wykresie) jest oznaczone jako P (sen). Na przykład o 22:00 wcześniejsze prawdopodobieństwo, że śpię, wynosi 27,34%.
Dodaj więcej informacji, używając prawdopodobieństwa P(światło w sypialni|sen) pochodzi z obserwowanych danych.
Z własnych obserwacji wiem, że prawdopodobieństwo, że śpię przy włączonym świetle wynosi 1%.
Prawdopodobieństwo, że światło jest wyłączone podczas snu, wynosi 1-0,01 = 0,99 (znak „-” we wzorze oznacza zdarzenie przeciwne), ponieważ suma prawdopodobieństw przeciwnych zdarzeń wynosi 1. Kiedy śpię, światło w sypialnia jest włączona lub wyłączona.
Wreszcie, równanie zawiera również stałą normalizacji Sytuacja) prawdopodobieństwo, że światło jest włączone. Światło jest włączone zarówno kiedy śpię, jak i kiedy nie śpię. Dlatego znając a priori prawdopodobieństwo snu, obliczamy stałą normalizacji w następujący sposób:
Prawdopodobieństwo, że światło jest włączone, jest brane pod uwagę w obu opcjach: albo śpię, albo nie ( P(-sen) = 1 — P (sen) jest prawdopodobieństwo, że nie śpię).
Prawdopodobieństwo, że światło jest włączone, kiedy nie śpię, wynosi P(lekki|-sen), i ustalona przez obserwację. Wiem, że istnieje 80% szans, że światło będzie włączone, gdy nie śpię (co oznacza, że istnieje 20% szans, że światło nie będzie włączone, gdy nie śpię).
Końcowe równanie Bayesa ma postać:
Pozwala obliczyć prawdopodobieństwo, że śpię, biorąc pod uwagę, że światło jest włączone. Jeśli interesuje nas prawdopodobieństwo zgaszenia światła, potrzebujemy każdej konstrukcji P(światło|… zastąpione przez P(-jasny|….
Zobaczmy, jak powstałe równania symboliczne są wykorzystywane w praktyce.
Zastosujmy wzór do godziny 22:30 i weźmy pod uwagę, że światło jest włączone. Wiemy, że istnieje 73,90% szans, że spałem. Ta liczba jest punktem wyjścia do naszej oceny.
Dopracujmy to, biorąc pod uwagę informacje o oświetleniu. Wiedząc, że lampka się świeci, podstawiamy liczby do wzoru Bayesa:
Dodatkowe dane radykalnie zmieniły oszacowanie prawdopodobieństwa z ponad 70% do 3,42%. Pokazuje to siłę twierdzenia Bayesa: udało nam się udoskonalić naszą wstępną ocenę sytuacji, dodając więcej informacji. Być może robiliśmy to intuicyjnie już wcześniej, ale teraz, myśląc o tym w kategoriach równań formalnych, byliśmy w stanie potwierdzić nasze przewidywania.
Rozważmy jeszcze jeden przykład. Co jeśli na zegarze jest 21:45, a światła są wyłączone? Spróbuj sam obliczyć prawdopodobieństwo, zakładając wcześniejsze oszacowanie 0,1206.
Zamiast ręcznie liczyć za każdym razem, napisałem prosty kod w Pythonie do wykonywania tych obliczeń, który możesz wypróbować w Jupyter Notebook. Otrzymasz następującą odpowiedź:
Godzina: 21:45:00 Światło wyłączone.
Wcześniejsze prawdopodobieństwo snu: 12,06%
Zaktualizowane prawdopodobieństwo snu: 40,44%
Ponownie, dodatkowe informacje zmieniają nasze szacunki. Teraz, jeśli moja siostra chce zadzwonić do mnie o 21:45, wiedząc, że mam włączone światło, może użyć tego równania, aby określić, czy mogę odebrać telefon (zakładając, że odbieram tylko wtedy, gdy nie śpię)! Kto powiedział, że statystyki nie mają zastosowania w życiu codziennym?
Wizualizacja prawdopodobieństwa
Obserwacja obliczeń jest przydatna, ale wizualizacja pomaga lepiej zrozumieć wynik. Zawsze staram się używać wykresów do generowania pomysłów, jeśli nie wynikają one naturalnie z samego studiowania równań. Możemy zwizualizować wcześniejsze i późniejsze rozkłady prawdopodobieństwa snu za pomocą dodatkowych danych:

Gdy światło jest włączone, wykres przesuwa się w prawo, wskazując, że jest mniej prawdopodobne, że będę spał w tym czasie. Podobnie wykres przesuwa się w lewo, jeśli moje światło jest wyłączone. Zrozumienie znaczenia twierdzenia Bayesa nie jest łatwe, ale ta ilustracja jasno pokazuje, dlaczego trzeba go używać. Formuła Bayesa to narzędzie do uszczegóławiania prognoz o dodatkowe dane.
A co jeśli danych jest jeszcze więcej?
Dlaczego poprzestać na oświetleniu sypialni? Możemy wykorzystać jeszcze więcej danych w naszym modelu, aby jeszcze bardziej udoskonalić oszacowanie (o ile dane pozostają przydatne w rozważanym przypadku). Na przykład wiem, że jeśli mój telefon się ładuje, to istnieje 95% szans, że będę spał. Fakt ten można uwzględnić w naszym modelu.
Załóżmy, że prawdopodobieństwo, że mój telefon się ładuje, jest niezależne od oświetlenia w sypialni (niezależność zdarzeń to mocne uproszczenie, ale znacznie ułatwi zadanie). Zróbmy nowe, jeszcze dokładniejsze wyrażenie na prawdopodobieństwo:
Wynikowa formuła wygląda nieporęcznie, ale używając kodu Pythona możemy napisać funkcję, która wykona obliczenia. Dla dowolnego punktu w czasie i dowolnej kombinacji oświetlenia/ładowania telefonu ta funkcja zwraca skorygowane prawdopodobieństwo, że śpię.
Godzina 23:00:00 Światło jest włączone Telefon NIE ładuje się.
Wcześniejsze prawdopodobieństwo snu: 95,52%
Zaktualizowane prawdopodobieństwo snu: 1,74%
O 23:00, bez dalszych informacji, prawie na pewno moglibyśmy powiedzieć, że śniłem. Kiedy jednak mamy dodatkowe informacje, że lampka się świeci, a telefon się nie ładuje, dochodzimy do wniosku, że prawdopodobieństwo, że śpię, jest praktycznie zerowe. Oto inny przykład:
Godzina 22:15:00 Światło jest WYŁĄCZONE Telefon się ładuje.
Wcześniejsze prawdopodobieństwo snu: 50,79%
Zaktualizowane prawdopodobieństwo snu: 95,10%
Prawdopodobieństwo przesuwa się w dół lub w górę w zależności od konkretnej sytuacji. Aby to zademonstrować, rozważ cztery dodatkowe konfiguracje danych i sposób, w jaki zmieniają one rozkład prawdopodobieństwa:

Ten wykres dostarcza wielu informacji, ale najważniejsze jest to, że krzywa prawdopodobieństwa zmienia się w zależności od dodatkowych czynników. Gdy dodamy więcej danych, otrzymamy dokładniejsze oszacowanie.
Wniosek
Twierdzenie Bayesa i inne koncepcje statystyczne mogą być trudne do zrozumienia, gdy są reprezentowane przez abstrakcyjne równania wykorzystujące tylko litery lub wyimaginowane sytuacje. Prawdziwa nauka przychodzi, gdy stosujemy abstrakcyjne koncepcje do rzeczywistych problemów.
Sukces w nauce o danych polega na ciągłym uczeniu się, dodawaniu nowych metod do zestawu umiejętności i znajdowaniu najlepszej metody rozwiązywania problemów. Twierdzenie Bayesa pozwala nam udoskonalić nasze oszacowania prawdopodobieństwa o dodatkowe informacje, aby lepiej modelować rzeczywistość. Zwiększenie ilości informacji pozwala na dokładniejsze przewidywania, a Bayes okazuje się być użytecznym narzędziem do tego zadania.
Czekam na opinie, dyskusję i konstruktywną krytykę. Możesz skontaktować się ze mną na Twitterze.
Lekcja nr 4.
Temat: Wzór na prawdopodobieństwo całkowite. Formuła Bayesa. Schemat Bernoulliego. Schemat wielomianu. Schemat hipergeometryczny.
WZÓR CAŁKOWITEGO PRAWDOPODOBIEŃSTWA
FORMUŁA BAYESA
TEORIA
Wzór na całkowite prawdopodobieństwo:
Niech będzie pełna grupa niekompatybilnych zdarzeń:
(, ![]() ).Wtedy prawdopodobieństwo zdarzenia A można obliczyć ze wzoru
).Wtedy prawdopodobieństwo zdarzenia A można obliczyć ze wzoru
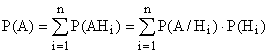 (4.1)
(4.1)
Zdarzenia nazywane są hipotezami. Stawia się hipotezy dotyczące tej części eksperymentu, w której występuje niepewność.
, gdzie są prawdopodobieństwami a priori hipotez
Formuła Bayesa:
Niech eksperyment się zakończy i będzie wiadomo, że w wyniku eksperymentu zaszło zdarzenie A. Wtedy, biorąc pod uwagę te informacje, możemy przeceniać prawdopodobieństwo hipotez:
![]() (4.2)
(4.2)
 , gdzie późniejsze prawdopodobieństwa hipotez
, gdzie późniejsze prawdopodobieństwa hipotez
ROZWIĄZYWANIE PROBLEMÓW
Zadanie 1.
Stan : schorzenie
W 3 partiach części otrzymanych na magazynie dobre są 89 %, 92 % oraz 97 % odpowiednio. Liczba części w partiach jest określana jako 1:2:3.
Jakie jest prawdopodobieństwo, że losowo wybrana część z magazynu będzie wadliwa. Niech wiadomo, że losowo wybrana część okazała się wadliwa. Znajdź prawdopodobieństwo, że należy do pierwszej, drugiej i trzeciej strony.
Decyzja:
Oznaczmy przez A zdarzenie, w którym losowo wybrana część okaże się wadliwa.
pierwsze pytanie - do wzoru na prawdopodobieństwo całkowite
drugie pytanie - do wzoru Bayesa
Stawia się hipotezy dotyczące tej części eksperymentu, w której występuje niepewność. W zadaniu tym niepewność polega na tym, z jakiej partii pochodzi losowo wybrana część.
Wpuść pierwszą grę a Detale. Następnie w drugiej grze - 2 a szczegóły, a w trzecim - 3 a Detale. Tylko trzy mecze 6 a Detale.
![]()
![]()
![]()
![]() (procent małżeństw w pierwszej linii przeliczono na prawdopodobieństwo)
(procent małżeństw w pierwszej linii przeliczono na prawdopodobieństwo)
![]() (procent małżeństw w drugiej linii przeliczono na prawdopodobieństwo)
(procent małżeństw w drugiej linii przeliczono na prawdopodobieństwo)
![]() (procent małżeństw w trzeciej linii przeliczony na prawdopodobieństwo)
(procent małżeństw w trzeciej linii przeliczony na prawdopodobieństwo)
Korzystając ze wzoru na prawdopodobieństwo całkowite, obliczamy prawdopodobieństwo zdarzenia A
-odpowiedz na 1 pytanie
Prawdopodobieństwo, że wadliwa część należy do pierwszej, drugiej i trzeciej partii, oblicza się za pomocą wzoru Bayesa:



Zadanie 2.
Stan : schorzenie:
W pierwszej urnie 10 kulki: 4 biały piasek 6 czarny. W drugiej urnie 20 kulki: 2 biały piasek 18 czarny. Z każdej urny losowo wybieramy jedną kulę i umieszczamy w trzeciej urnie. Następnie z trzeciej urny losujemy jedną kulę. Znajdź prawdopodobieństwo, że kula wylosowana z trzeciej urny jest biała.
Decyzja:
Odpowiedź na pytanie problemu można uzyskać za pomocą wzoru na prawdopodobieństwo całkowite:
Niepewność polega na tym, które kule trafiły do trzeciej urny. Postawiliśmy hipotezy dotyczące składu kul w trzeciej urnie.
H1=(w trzeciej urnie są 2 białe kule)
H2=(w trzeciej urnie są 2 czarne kule)
H3=(trzecia urna zawiera 1 kulę białą i 1 kulę czarną)
A=(piłka pobrana z urny 3 będzie biała)
![]()
Zadanie 3.
Do urny zawierającej 2 kule nieznanego koloru wrzucono białą kulę. Następnie wyciągamy 1 kulę z tej urny. Znajdź prawdopodobieństwo, że wylosowana kula z urny jest biała. Kula wyjęta z opisanej powyżej urny okazała się biała. Znajdź prawdopodobieństwa że przed przeniesieniem w urnie było 0 kul białych, 1 kula biała i 2 kule białe .
1 pytanie c - do wzoru na prawdopodobieństwo całkowite
2 pytanie- na wzór Bayesa
Niepewność tkwi w początkowym składzie kul w urnie. Odnośnie początkowego składu kul w urnie stawiamy następujące hipotezy:
Hi=( w urnie przed zmianą byłoi-1 bila biała),i=1,2,3
, i=1,2,3(w sytuacji całkowitej niepewności przyjmujemy, że prawdopodobieństwa a priori hipotez są takie same, ponieważ nie możemy powiedzieć, że jedna opcja jest bardziej prawdopodobna niż druga)
A = (kula wylosowana z urny po przeniesieniu będzie biała)
Obliczmy prawdopodobieństwa warunkowe:
Dokonajmy obliczeń, korzystając ze wzoru na prawdopodobieństwo całkowite:
Odpowiedz na 1 pytanie
Aby odpowiedzieć na drugie pytanie, używamy wzoru Bayesa:
 (zmniejszone w porównaniu z wcześniejszym prawdopodobieństwem)
(zmniejszone w porównaniu z wcześniejszym prawdopodobieństwem)
 (bez zmian w stosunku do wcześniejszego prawdopodobieństwa)
(bez zmian w stosunku do wcześniejszego prawdopodobieństwa)
 (zwiększone w porównaniu z wcześniejszym prawdopodobieństwem)
(zwiększone w porównaniu z wcześniejszym prawdopodobieństwem)
Wniosek z porównania prawdopodobieństw a priori i a posteriori hipotez: początkowa niepewność zmieniła się ilościowo
Zadanie 4.
Stan : schorzenie:
Podczas przetaczania krwi należy wziąć pod uwagę grupy krwi dawcy i pacjenta. Osoba, która ma czwarta grupa krew każdy rodzaj krwi może być przetaczany, do osoby z drugą i trzecią grupą można wlać lub krew jego grupy, lub pierwszy. do osoby z pierwszą grupą krwi możesz przetaczać krew tylko pierwsza grupa. Wiadomo, że wśród ludności 33,7 % mieć pierwsza grupa pu, 37,5 % mieć druga grupa, 20,9% mieć trzecia grupa oraz Czwartą grupę ma 7,9%. Znajdź prawdopodobieństwo, że losowo pobranemu pacjentowi można przetoczyć krew losowo pobranego dawcy.
Decyzja:
Stawiamy hipotezy dotyczące grupy krwi losowo pobranego pacjenta:
Cześć = (w przypadku pacjentai-ta grupa krwi),i=1,2,3,4
![]()
![]()
![]()
![]()
(Procenty przeliczone na prawdopodobieństwa)
A=(można przetoczyć)
Zgodnie ze wzorem na prawdopodobieństwo całkowite otrzymujemy:
tj. transfuzję można wykonać w około 60% przypadków
Schemat Bernoulliego (lub schemat dwumianowy)
Próby Bernoulliego - to niezależne testy 2 wynik, który nazywamy warunkowo sukces i porażka.
p- wskaźnik sukcesu
q-prawdopodobieństwo niepowodzenia
Prawdopodobieństwo sukcesu nie zmienia się z doświadczenia na doświadczenie
Wynik poprzedniego testu nie ma wpływu na następny test.
Przeprowadzenie testów opisanych powyżej nazywa się schematem Bernoulliego lub schematem dwumianowym.
Przykłady testów Bernoulliego:
Rzut monetąPowodzenie - herb
Niepowodzenie- ogony
Przypadek właściwej monety
niewłaściwy pojemnik na monety
p oraz q nie zmieniaj się z doświadczenia na doświadczenie, jeśli nie zmienimy monety podczas eksperymentu
Rzucanie kostkąPowodzenie - rzuć „6”
Niepowodzenie - cała reszta
Sprawa zwykłej kostki
Przypadek niewłaściwych kości
p oraz q nie zmieniaj z doświadczenia na doświadczenie, jeśli w trakcie przeprowadzania eksperymentu nie zmieniamy kostek
Strzała strzelająca do celuPowodzenie - uderzyć
Niepowodzenie - tęsknić
p = 0,1 (strzelec trafia w jednym strzale na 10)
p oraz q nie zmieniaj się z doświadczenia na doświadczenie, jeśli w trakcie przeprowadzania eksperymentu nie zmienimy strzałki
Formuła Bernoulliego.
Zostawiać trzymany n p. Rozważ wydarzenia
(wn Próby Bernoulliego z prawdopodobieństwem powodzeniastanie się pm sukcesów),
![]() -istnieje standardowa notacja prawdopodobieństw takich zdarzeń
-istnieje standardowa notacja prawdopodobieństw takich zdarzeń
<-Wzór Bernoulliego do obliczania prawdopodobieństw (4.3)
Wyjaśnienie formuły : prawdopodobieństwo, że będzie m sukcesów (prawdopodobieństwa są mnożone, ponieważ próby są niezależne, a ponieważ wszystkie są takie same, pojawia się stopień), - prawdopodobieństwo, że wystąpi n-m porażek (wyjaśnienie jest analogiczne jak w przypadku sukcesów), - liczba sposobów realizacji wydarzenia, czyli na ile sposobów można umieścić m sukcesów w n miejscach.
Konsekwencje wzoru Bernoulliego:
Wniosek 1:
Zostawiać trzymany n Próby Bernoulliego z prawdopodobieństwem powodzenia p. Rozważ wydarzenia
A(m1,m2)=(liczba sukcesów wn Próby Bernoulliego będą zawierały się w przedziale [m1;m2])
![]() (4.4)
(4.4)
Wyjaśnienie wzoru:
Wzór (4.4) wynika ze wzoru (4.3) i twierdzenia o dodawaniu prawdopodobieństwa dla niezgodne zdarzenia, dlatego  - suma (suma) niekompatybilnych zdarzeń, a prawdopodobieństwo każdego z nich określa wzór (4.3).
- suma (suma) niekompatybilnych zdarzeń, a prawdopodobieństwo każdego z nich określa wzór (4.3).
Konsekwencja 2
Zostawiać trzymany n Próby Bernoulliego z prawdopodobieństwem powodzenia p. Rozważ wydarzenie
A=( wn Próby Bernoulliego zakończą się co najmniej 1 sukcesem}
![]() (4.5)
(4.5)
Wyjaśnienie wzoru: ={ nie będzie sukcesu w n próbach Bernoulliego)=
(wszystkie n prób zakończy się niepowodzeniem)
Problem (o formule Bernoulliego i jego konsekwencjach) przykład dla problemu 1.6-D. h.
Właściwa moneta rzucić 10 razy. Znajdź prawdopodobieństwa następujących zdarzeń:
A=(herb spadnie dokładnie 5 razy)
B=(herb spadnie nie więcej niż 5 razy)
C=(herb spadnie przynajmniej raz)
Decyzja:
Przeformułujmy problem w kategoriach testów Bernoulliego:
n=10 liczba prób
powodzenie- herb
p=0,5 – prawdopodobieństwo sukcesu
q=1-p=0,5 – prawdopodobieństwo niepowodzenia
Aby obliczyć prawdopodobieństwo zdarzenia A, używamy Formuła Bernoulliego:

Aby obliczyć prawdopodobieństwo zdarzenia B, używamy konsekwencja 1 do Wzór Bernoulliego:

Aby obliczyć prawdopodobieństwo zdarzenia C, używamy wniosek 2 do Wzór Bernoulliego:

Schemat Bernoulliego. Obliczanie za pomocą przybliżonych wzorów.
PRZYBLIŻONA FORMUŁA MOIAVRE-LAPLACE
Formuła lokalna
p sukces i q porażka, a potem dla wszystkich m obowiązuje przybliżona formuła:
 , (4.6)
, (4.6)
m.
Wartość funkcji można znaleźć w pliku special tabela. Zawiera tylko wartości dla . Ale funkcja jest parzysta, tj.
Jeśli , to załóżmy
integralna formuła
Jeśli liczba prób n w schemacie Bernoulliego jest duża, a prawdopodobieństwa są również duże p sukces i q niepowodzenie, to przybliżona formuła jest ważna dla wszystkich (4.7) :
Wartość funkcji można znaleźć w specjalnej tabeli. Zawiera tylko wartości dla . Ale funkcja jest nieparzysta, tj. ![]() .
.
Jeśli , to załóżmy
PRZYBLIŻONY WZÓR POISSONA
Formuła lokalna
Niech liczba prób n według schematu Bernoulliego jest duże, a prawdopodobieństwo sukcesu w jednym teście jest małe, a iloczyn też mały. Następnie określa się go za pomocą przybliżonego wzoru:
![]() , (4.8)
, (4.8)
Prawdopodobieństwo, że liczba sukcesów w n próbach Bernoulliego wynosi m.
Wartości funkcji ![]() można obejrzeć w specjalnej tabeli.
można obejrzeć w specjalnej tabeli.
integralna formuła
Niech liczba prób n według schematu Bernoulliego jest duże, a prawdopodobieństwo sukcesu w jednym teście jest małe, a iloczyn też mały.
Następnie ![]() określony za pomocą przybliżonego wzoru:
określony za pomocą przybliżonego wzoru:
 , (4.9)
, (4.9)
Prawdopodobieństwo, że liczba sukcesów w n próbach Bernoulliego mieści się w przedziale .
Wartości funkcji ![]() można wyświetlić w specjalnej tabeli, a następnie zsumować w całym zakresie.
można wyświetlić w specjalnej tabeli, a następnie zsumować w całym zakresie.
|
Formuła |
Formuła Poissona |
Formuła Moivre'a-Laplace'a |
Jakość szacunki |
|
szacunki są przybliżone |
|||
|
10 |
używany do przybliżonych szacunków obliczenia |
||
|
używany do stosowanego obliczenia inżynierskie |
|||
|
100 0 |
wykorzystywane do wszelkich obliczeń inżynierskich |
||
|
n>1000 |
bardzo dobre stopnie |
Możesz spojrzeć na jakość przykładów do zadań 1.7 i 1.8 D. z.
Obliczenia według wzoru Poissona.
Problem (wzór Poissona).
Stan : schorzenie:
Prawdopodobieństwo zniekształcenia jednego symbolu podczas przesyłania wiadomości przez linię komunikacyjną jest równe 0.001. Wiadomość uważa się za przyjętą, jeśli nie ma w niej zniekształceń. Znajdź prawdopodobieństwo otrzymania wiadomości składającej się z 20 słowa 100 każdy znaków każdy.
Decyzja:
Oznacz przez ORAZ
-ilość znaków w wiadomości
sukces: postać nie jest zniekształcona
Prawdopodobieństwo sukcesu
obliczmy. Zobacz zalecenia dotyczące używania przybliżonych formuł ( ![]() )
: do obliczeń należy zastosować Formuła Poissona
)
: do obliczeń należy zastosować Formuła Poissona
Prawdopodobieństwa dla wzoru Poissona względem im można znaleźć w specjalnej tabeli.
Stan : schorzenie:
Centrala telefoniczna obsługuje 1000 abonentów. Prawdopodobieństwo, że w ciągu minuty jakikolwiek abonent będzie potrzebował połączenia, wynosi 0,0007. Oblicz prawdopodobieństwo, że w ciągu minuty do centrali telefonicznej dotrą co najmniej 3 połączenia.
Decyzja:
Przeformułuj problem pod kątem schematu Bernoulliego
powodzenie: połączenie odebrane
Prawdopodobieństwo sukcesu
– przedział, w którym musi mieścić się liczba sukcesów
A = (nadejdzie co najmniej trzy połączenia) - zdarzenie, którego prawdopodobieństwo jest wymagane. znajdź w zadaniu
(Przybędą mniej niż trzy połączenia) Przechodzimy do dodatkowego. zdarzenia, ponieważ jego prawdopodobieństwo jest łatwiejsze do obliczenia.
![]()
(obliczanie terminów patrz specjalna tabela)
Zatem,
Problem (lokalny wzór Mouvre-Laplace'a)
Stan : schorzenie
Prawdopodobieństwo trafienia w cel jednym strzałem równa się 0,8. Określ prawdopodobieństwo, że o 400 będą strzały dokładnie 300 hity.
Decyzja:
Przeformułuj problem pod kątem schematu Bernoulliego
n=400 – liczba prób
m=300 – liczba sukcesów
sukces - trafienie
(Pytanie problemowe w zakresie schematu Bernoulliego)
Oszacowanie:
Spędzamy niezależne testy, w każdym z nich się wyróżniamy m opcje.
p1 - prawdopodobieństwo uzyskania pierwszej opcji w jednym teście
p2 - prawdopodobieństwo uzyskania drugiej opcji w jednym teście
…………..
pm to prawdopodobieństwo otrzymaniam-ta opcja w jednej próbie
p1,p2, ……………..,pm nie zmieniaj się z doświadczenia na doświadczenie
Sekwencja testów opisana powyżej nazywa się schemat wielomianowy.
(gdy m=2 schemat wielomianowy zamienia się w dwumianowy), tj. opisany powyżej schemat dwumianowy jest szczególnym przypadkiem bardziej ogólnego schematu zwanego wielomianem).
Rozważ następujące wydarzenia
А(n1,n2,….,nm)=(w n próbach opisanych powyżej, wariant 1 pojawił się n1 razy, wariant 2 pojawił się n2 razy, ….., itd., nm razy wariant m)
Wzór do obliczania prawdopodobieństw za pomocą schematu wielomianowego
Stan : schorzenie
kostka do gry rzuć 10 razy. Należy znaleźć prawdopodobieństwo, że wypadnie „6”. 2 razy, a „5” wypadnie 3 razy.
Decyzja:
Oznacz przez ORAZ zdarzenie, którego prawdopodobieństwo można znaleźć w problemie.
n=10 - liczba prób
m=3
1 opcja - spadek 6
p1=1/6n1=2
Opcja 2 – Upuść 5
p2=1/6n2=3
Opcja 3 – Upuść dowolną twarz oprócz 5 i 6
p3=4/6n3=5
P(2,3,5)-? (prawdopodobieństwo zdarzenia, o którym mowa w warunku problemu)
Problem dla obwodu wielomianowego
Stan : schorzenie
Znajdź prawdopodobieństwo, że wśród 10 Losowo wybrane osoby będą miały cztery urodziny w pierwszym kwartale, trzy w drugim, dwa w trzecim i jeden w czwartym.
Decyzja:
Oznacz przez ORAZ zdarzenie, którego prawdopodobieństwo można znaleźć w problemie.
Przeformułujmy problem w postaci schematu wielomianowego:
n=10 - liczba prób = liczba osób
m=4 to liczba opcji, które rozróżniamy w każdej próbie
Opcja 1 - poród w 1 kwartale
p1=1/4n1=4
Opcja 2 - poród w 2 kwartale
p2=1/4n2=3
Opcja 3 - poród w 3 kwartale
p3=1/4n3=2
Opcja 4 - poród w 4 kwartale
p4=1/4n4=1
P(4,3,2,1)-? (prawdopodobieństwo zdarzenia, o którym mowa w warunku problemu)
Przyjmujemy, że prawdopodobieństwo urodzenia się w dowolnym kwartale jest takie samo i wynosi 1/4. Przeprowadźmy obliczenia zgodnie ze wzorem na schemat wielomianu:
Problem dla obwodu wielomianowego
Stan : schorzenie
w urnie 30 kulki: Witamy spowrotem.3 białe, 2 zielone, 4 niebieskie i 1 żółty.
Decyzja:
Oznacz przez ORAZ zdarzenie, którego prawdopodobieństwo można znaleźć w problemie.
Przeformułujmy problem w postaci schematu wielomianowego:
n=10 - liczba prób = liczba wybranych piłek
m=4 to liczba opcji, które rozróżniamy w każdej próbie
Opcja 1 - wybierz białą kulę
p1=1/3n1=3
Wariant 2 - wybierz zieloną kulę
p2=1/6n2=2
Trzecia opcja - wybór niebieskiej kuli
p3=4/15n3=4
Wariant 4 - wybierz żółtą kulę
p4=7/30n4=1
P(3,2,4,1)-? (prawdopodobieństwo zdarzenia, o którym mowa w warunku problemu)
p1,p2, p3,p4 nie zmieniaj się z doświadczenia na doświadczenie, ponieważ wybór jest dokonywany z powrotem
Przeprowadźmy obliczenia zgodnie ze wzorem na schemat wielomianu:
Schemat hipergeometryczny
Niech będzie n elementów k typów:
n1 pierwszego typu
n2 drugiego typu
nk typ k
Z tych n elementów losowo bez powrotu wybierz m elementów
Rozważmy zdarzenie A(m1,…,mk), które polega na tym, że wśród wybranych m elementów będzie
m1 pierwszego typu
m2 drugiego typu
mk k-ty typ
Prawdopodobieństwo tego zdarzenia oblicza się według wzoru
P(A(m1,…,mk))=  (4.11)
(4.11)
Przykład 1
Problem dla schematu hipergeometrycznego (próbka dla problemu 1.9 D. h)
Stan : schorzenie
w urnie 30 kulki: 10 białych, 5 zielonych, 8 niebieskich i 7 żółtych(kulki różnią się tylko kolorem). Z urny losowo wybrano 10 kul. bez powrotu. Znajdź prawdopodobieństwo, że wśród wybranych kulek będzie: 3 białe, 2 zielone, 4 niebieskie i 1 żółty.
Mamyn=30,k=4,
n1=10,n2=5,n3=8,n4=7,
m1=3,m2=2,m3=4,m4=1
P(A(3,2,4,1))=  = można policzyć do liczby znając wzór na kombinacje
= można policzyć do liczby znając wzór na kombinacje
Przykład 2
Przykład obliczenia według tego schematu: patrz obliczenia dla gry Sportloto (temat 1)


