Z czego składa się DNA? Co to jest nukleotyd? Skład, budowa, liczba i sekwencja nukleotydów w łańcuchu DNA Podwójna helisa DNA stabilizuje jony
Kwasy nukleinowe to wysokocząsteczkowe substancje składające się z mononukleotydów, które są połączone ze sobą w łańcuch polimerowy za pomocą wiązań 3”, 5” - fosfodiestrowych i są upakowane w komórkach w określony sposób.
Kwasy nukleinowe to biopolimery dwóch typów: kwasu rybonukleinowego (RNA) i kwasu dezoksyrybonukleinowego (DNA). Każdy biopolimer składa się z nukleotydów różniących się resztą węglowodanową (ryboza, dezoksyryboza) i jedną z zasad azotowych (uracyl, tymina). Zgodnie z tymi różnicami kwasy nukleinowe otrzymały swoją nazwę.
Struktura kwasu dezoksyrybonukleinowego
Kwasy nukleinowe mają strukturę pierwszorzędową, drugorzędową i trzeciorzędową.
Pierwotna struktura DNA
Pierwotna struktura DNA nazywana jest liniowym łańcuchem polinukleotydowym, w którym mononukleotydy są połączone wiązaniami 3”, 5” -fosfodiestrowymi. Materiałem wyjściowym do montażu łańcucha kwasu nukleinowego w komórce jest nukleozyd 5"-trifosforan, który w wyniku usunięcia reszt kwasu fosforowego β i γ jest zdolny do przyłączenia 3" atomu węgla innego nukleozydu . A zatem, 3"atom węgla jednej dezoksyrybozy wiąże się kowalencyjnie z 5" atomem węgla drugiej dezoksyrybozy poprzez jedną resztę kwasu fosforowego i tworzy liniowy polinukleotydowy łańcuch kwasu nukleinowego. Stąd nazwa: wiązania 3”, 5” -fosfodiestrowe. Zasady azotowe nie biorą udziału w łączeniu nukleotydów jednego łańcucha (ryc. 1.).
Takie połączenie pomiędzy pozostałą częścią cząsteczki kwasu fosforowego jednego nukleotydu a węglowodanem drugiego prowadzi do powstania szkieletu pentozofosforanowego cząsteczki polinukleotydu, do którego jedna po drugiej są przyłączone zasady azotowe. Ich kolejność ułożenia w łańcuchach cząsteczek kwasu nukleinowego jest ściśle specyficzna dla komórek różnych organizmów, tj. ma specyficzny charakter (reguła Chargaffa).
Liniowy łańcuch DNA, którego długość zależy od liczby nukleotydów zawartych w łańcuchu, ma dwa końce: jeden nazywany jest 3" i zawiera wolny hydroksyl, a drugi 5" zawiera kwas fosforowy pozostałość. Łańcuch jest spolaryzowany i może mieć kierunek 5 "-> 3" i 3 "-> 5". Wyjątkiem jest koliste DNA.
Genetyczny „tekst” DNA składa się ze „słów” kodu – trójek nukleotydów zwanych kodonami. Regiony DNA, które zawierają informacje o pierwotnej strukturze wszystkich typów RNA, nazywane są genami strukturalnymi.
Łańcuchy polinukleodytowego DNA osiągają gigantyczne rozmiary, są więc w określony sposób upakowane w komórce.
Badając skład DNA, Chargaff (1949) ustanowił ważne prawa dotyczące zawartości poszczególnych zasad DNA. Pomogli odkryć wtórną strukturę DNA. Te wzorce nazywane są zasadami Chargaffa. Zasady Chargaffa
Reguły te wskazują, że podczas budowy DNA nie powinno się zaobserwować dość ścisłej zgodności (parowania) zasad purynowych i pirymidynowych w ogóle, ale konkretnie tyminy z adeniną i cytozyny z guaniną. W oparciu o te zasady, m.in. w 1953 roku Watson i Crick zaproponowali model struktury drugorzędowej DNA, zwany podwójną helisą (ryc.). |

Wtórna struktura DNA
Drugorzędowa struktura DNA to podwójna helisa, której model został zaproponowany przez D. Watsona i F. Cricka w 1953 roku.
Warunki wstępne stworzenia modelu DNA
Wstępne analizy dały wrażenie, że DNA dowolnego pochodzenia zawiera wszystkie cztery nukleotydy w równych ilościach molowych. Jednak w latach 40. E. Chargaff i jego współpracownicy w wyniku analizy DNA izolowanego z różnych organizmów wyraźnie wykazali, że zasady azotowe są w nich zawarte w różnych proporcjach ilościowych. Chargaff odkrył, że chociaż te proporcje są takie same dla DNA ze wszystkich komórek tego samego typu organizmu, DNA z różnych gatunków może znacznie różnić się zawartością niektórych nukleotydów. Sugerowało to, że różnice w proporcji zasad azotowych mogą być związane z jakimś rodzajem kodu biologicznego. Chociaż stosunek poszczególnych zasad purynowych i pirymidynowych w różnych próbkach DNA okazał się różny, porównując wyniki analizy wyłonił się pewien wzór: we wszystkich próbkach całkowita ilość puryn była równa całkowitej ilości pirymidyn (A + G = T + C), ilość adeniny była równa ilości tyminy (A=T), a ilości guaniny – ilości cytozyny (G=C). DNA wyizolowane z komórek ssaków było generalnie bogatsze w adeninę i tyminę oraz stosunkowo uboższe w guaninę i cytozynę, podczas gdy DNA bakterii było bogatsze w guaninę i cytozynę oraz stosunkowo uboższe w adeninę i tyminę. Dane te stanowiły ważną część materiału faktograficznego, na podstawie którego później zbudowano model struktury DNA Watsona-Cricka.
Innym ważnym pośrednim wskazaniem możliwej struktury DNA były dane L. Paulinga dotyczące struktury cząsteczek białka. Pauling wykazał, że możliwych jest kilka różnych stabilnych konfiguracji łańcucha aminokwasów w cząsteczce białka. Jedną z powszechnych konfiguracji łańcucha peptydowego, α-helisy, jest regularna struktura helikalna. Przy takiej strukturze możliwe jest tworzenie wiązań wodorowych pomiędzy aminokwasami znajdującymi się na sąsiednich zwojach łańcucha. Pauling opisał konfigurację α-helikalną łańcucha polipeptydowego w 1950 roku i zasugerował, że cząsteczki DNA również prawdopodobnie mają strukturę helikalną, połączoną wiązaniami wodorowymi.
Jednak najcenniejszych informacji o budowie cząsteczki DNA dostarczyły wyniki rentgenowskiej analizy strukturalnej. Promienie rentgenowskie przechodząc przez kryształ DNA ulegają dyfrakcji, to znaczy są odchylane w określonych kierunkach. Stopień i charakter ugięcia promieni zależą od struktury samych cząsteczek. Dyfraktogram rentgenowski (rys. 3) daje doświadczonemu oku szereg pośrednich wskazówek dotyczących budowy cząsteczek badanej substancji. Analiza wzorów dyfrakcji rentgenowskiej DNA doprowadziła do wniosku, że zasady azotowe (mające płaski kształt) są ułożone w stos jak stos płytek. Dyfraktogramy rentgenowskie ujawniły trzy główne okresy w strukturze krystalicznego DNA: 0,34, 2 i 3,4 nm.

Model DNA Watsona-Cricka
Na podstawie danych analitycznych Chargaffa, dyfraktogramów rentgenowskich uzyskanych przez Wilkinsa oraz badań chemików, którzy dostarczyli informacji o dokładnych odległościach między atomami w cząsteczce, o kątach między wiązaniami danego atomu i wielkości atomów, Watson i Crick zaczęli budować modele fizyczne poszczególnych części składowych cząsteczki DNA w określonej skali i „dopasowywać” je do siebie w taki sposób, aby powstały układ odpowiadał różnym danym eksperymentalnym [pokazać] .
Już wcześniej wiedziano, że sąsiadujące nukleotydy w łańcuchu DNA są połączone mostkami fosfodiestrowymi łączącymi atom węgla 5' dezoksyrybozy jednego nukleotydu z atomem węgla 3' dezoksyrybozy następnego nukleotydu. Watson i Crick nie mieli wątpliwości, że okres 0,34 nm odpowiada odległości między kolejnymi nukleotydami w łańcuchu DNA. Ponadto można by założyć, że okres 2 nm odpowiada grubości łańcucha. Aby wyjaśnić, jaka rzeczywista struktura odpowiada okresowi 3,4 nm, Watson i Crick, podobnie jak wcześniej Pauling, zasugerowali, że łańcuch jest skręcony w formie spirali (a dokładniej linii śrubowej, ponieważ spirala w ścisłym tego słowa znaczeniu to słowo uzyskuje się, gdy zwoje tworzą w przestrzeni powierzchnię stożkową, a nie cylindryczną). Wtedy okres 3,4 nm będzie odpowiadał odległości między kolejnymi zwojami tej spirali. Taka spirala może być bardzo gęsta lub nieco rozciągnięta, to znaczy jej zakręty mogą być łagodne lub strome. Ponieważ okres 3,4 nm jest dokładnie 10-krotnością odległości między kolejnymi nukleotydami (0,34 nm), jasne jest, że każdy pełny obrót helisy zawiera 10 nukleotydów. Na podstawie tych danych Watson i Crick byli w stanie obliczyć gęstość łańcucha polinukleotydowego skręconego w helisę o średnicy 2 nm z odległością między zwojami równą 3,4 nm. Okazało się, że gęstość takiego łańcucha będzie równa połowie rzeczywistej gęstości DNA, która była już znana. Musiałem założyć, że cząsteczka DNA składa się z dwóch nici - że jest podwójną helisą nukleotydów.
Kolejnym zadaniem było oczywiście wyjaśnienie relacji przestrzennej między dwoma obwodami tworzącymi podwójną helisę. Po przetestowaniu szeregu układów łańcuchów na ich modelu fizycznym, Watson i Crick stwierdzili, że wszystkie dostępne dane najlepiej pasują do wariantu, w którym dwie helisy polinukleotydowe biegną w przeciwnych kierunkach; w tym przypadku łańcuchy składające się z reszt cukrowych i fosforanowych tworzą powierzchnię podwójnej helisy, a wewnątrz znajdują się puryn i pirymidyny. Zasady znajdujące się naprzeciw siebie, należące do dwóch łańcuchów, są połączone parami wiązaniami wodorowymi; to właśnie te wiązania wodorowe utrzymują łańcuchy razem, ustalając w ten sposób ogólną konfigurację cząsteczki.
Podwójną helisę DNA można sobie wyobrazić jako drabinkę linową w kształcie spirali, której szczeble pozostają w pozycji poziomej. Wtedy dwie podłużne liny będą odpowiadały łańcuchom reszt cukrowych i fosforanowych, a poprzeczki będą odpowiadały parom zasad azotowych połączonych wiązaniami wodorowymi.
W wyniku dalszych badań możliwych modeli Watson i Crick doszli do wniosku, że każdy „baton” powinien składać się z jednej puryny i jednej pirymidyny; przy okresie 2 nm (co odpowiada średnicy podwójnej helisy) nie byłoby wystarczająco dużo miejsca dla dwóch puryn, a dwie pirymidyny nie byłyby wystarczająco blisko siebie, aby utworzyć odpowiednie wiązania wodorowe. Dogłębne badanie szczegółowego modelu wykazało, że adenina i cytozyna, tworząc odpowiednią kombinację pod względem wielkości, nadal nie mogą być zlokalizowane w taki sposób, aby tworzyły między sobą wiązania wodorowe. Podobne doniesienia wymusiły wykluczenie kombinacji guanina-tymina, podczas gdy kombinacje adenina-tymina i guanina-cytozyna były całkiem akceptowalne. Charakter wiązań wodorowych jest taki, że adenina tworzy parę z tyminą, a guanina z cytozyną. Ta koncepcja specyficznego parowania zasad umożliwiła wyjaśnienie „reguły Chargaffa”, zgodnie z którą w dowolnej cząsteczce DNA ilość adeniny jest zawsze równa zawartości tyminy, a ilość guaniny jest równa ilości cytozyny. Dwa wiązania wodorowe powstają między adeniną i tyminą, a trzy wiązania wodorowe powstają między guaniną i cytozyną. Ze względu na specyficzność tworzenia wiązań wodorowych z każdą adeniną w jednym łańcuchu, tymina znajduje się w drugim; podobnie przeciw każdej guaninie można znaleźć tylko cytozynę. Zatem łańcuchy są komplementarne do siebie, to znaczy sekwencja nukleotydów w jednym łańcuchu jednoznacznie określa ich sekwencję w drugim. Dwa łańcuchy biegną w przeciwnych kierunkach, a ich końcowe grupy fosforanowe znajdują się na przeciwległych końcach podwójnej helisy.
W wyniku swoich badań w 1953 roku Watson i Crick zaproponowali model budowy cząsteczki DNA (ryc. 3), który pozostaje aktualny do dnia dzisiejszego. Zgodnie z modelem cząsteczka DNA składa się z dwóch komplementarnych łańcuchów polinukleotydowych. Każda nić DNA to polinukleotyd złożony z kilkudziesięciu tysięcy nukleotydów. W nim sąsiednie nukleotydy tworzą regularny szkielet pentozofosforanowy z powodu połączenia reszty kwasu fosforowego i dezoksyrybozy silnym wiązaniem kowalencyjnym. W tym przypadku zasady azotowe jednego łańcucha polinukleotydowego są ułożone w ściśle określonej kolejności względem zasad azotowych drugiego. Przemienność zasad azotowych w łańcuchu polinukleotydowym jest nieregularna.
Lokalizacja zasad azotowych w łańcuchu DNA jest komplementarna (z greckiego „uzupełnienie” – dodatek), tj. przeciwko adeninie (A) zawsze występuje tymina (T), a przeciwko guaninie (G) tylko cytozyna (C). Wynika to z faktu, że A i T, a także G i C ściśle sobie odpowiadają, tj. wzajemnie się uzupełniają. Ta zgodność jest nadana przez strukturę chemiczną zasad, która umożliwia tworzenie wiązań wodorowych w parze purynowo-pirymidynowej. Istnieją dwa połączenia między A i T, trzy między G i C. Wiązania te zapewniają częściową stabilizację cząsteczki DNA w przestrzeni. W tym przypadku stabilność podwójnej helisy jest wprost proporcjonalna do liczby wiązań G≡C, które są bardziej stabilne w porównaniu z wiązaniami A = T.
Znana sekwencja ułożenia nukleotydów w jednej nici DNA umożliwia, zgodnie z zasadą komplementarności, ustalenie nukleotydów drugiej nici.
Ponadto stwierdzono, że zasady azotowe o strukturze aromatycznej w roztworze wodnym znajdują się jedna nad drugą, tworząc niejako stos monet. Ten proces formowania stosów organiczne molekuły zwany staking. Łańcuchy polinukleotydowe cząsteczki DNA rozważanego modelu Watsona-Cricka mają podobny stan fizykochemiczny, ich zasady azotowe znajdują się w postaci stosu monet, pomiędzy płaszczyznami, w których powstają oddziaływania van der Waalsa (oddziaływania ułożone w stos).
Wiązania wodorowe między komplementarnymi zasadami (w poziomie) oraz oddziaływanie ułożone w stos między płaszczyznami zasad w łańcuchu polinukleotydowym dzięki siłom van der Waalsa (w pionie) zapewnia cząsteczce DNA dodatkową stabilizację w przestrzeni.
Szkielety cukrowo-fosforanowe obu łańcuchów są skierowane na zewnątrz, a zasady do wewnątrz, do siebie. Kierunek łańcuchów w DNA jest antyrównoległy (jeden z nich ma kierunek 5 "-> 3", drugi - 3 "-> 5", tj. 3 "koniec jednego łańcucha jest przeciwny do 5" końca drugiego .). Łańcuchy tworzą prawoskrętne spirale o wspólnej osi. Jeden obrót helisy to 10 nukleotydów, wielkość cewki to 3,4 nm, wysokość każdego nukleotydu to 0,34 nm, a średnica helisy to 2,0 nm. W wyniku rotacji jednej nici wokół drugiej powstaje duży rowek (o średnicy około 20 Å) i mały rowek (około 12 Å) podwójnej helisy DNA. Ta forma podwójnej helisy Watsona-Cricka została później nazwana formą B. W komórkach DNA zwykle występuje w formie B, która jest najbardziej stabilna.
Funkcje DNA
Zaproponowany model wyjaśniał wiele biologicznych właściwości kwasu dezoksyrybonukleinowego, w tym przechowywanie informacji genetycznej i różnorodność genów zapewnianych przez szeroką gamę sekwencyjnych kombinacji 4 nukleotydów oraz fakt istnienia kodu genetycznego, zdolności do samoodtwarzania oraz transfer informacji genetycznej, dostarczonej przez proces replikacji i implementacji informacji genetycznej w postaci białek, jak również wszelkich innych związków utworzonych za pomocą białek enzymatycznych.
Podstawowe funkcje DNA.
- DNA jest nośnikiem informacji genetycznej, o czym świadczy fakt istnienia kodu genetycznego.
- Reprodukcja i przekazywanie informacji genetycznej w pokoleniach komórek i organizmów. Tę funkcjonalność zapewnia proces replikacji.
- Realizacja informacji genetycznej w postaci białek, a także wszelkich innych związków powstałych za pomocą enzymów białkowych. Tę funkcję zapewniają procesy transkrypcji i translacji.

Formy organizacji dwuniciowego DNA
DNA może tworzyć kilka rodzajów podwójnych helis (ryc. 4). Obecnie znanych jest już sześć form (od A do E i Z-forma).
Formy strukturalne DNA, jak ustaliła Rosalind Franklin, zależą od nasycenia wody w cząsteczce kwasu nukleinowego. W badaniach włókien DNA metodą rentgenowskiej analizy strukturalnej wykazano, że dyfraktogram rentgenowski radykalnie zależy od tego, przy jakiej wilgotności względnej, w jakim stopniu nasycenia wodą tego włókna odbywa się eksperyment. Jeśli włókno było wystarczająco nasycone wodą, to uzyskano jedno zdjęcie rentgenowskie. Podczas suszenia pojawił się zupełnie inny wzór rentgenowski, bardzo różny od wzoru rentgenowskiego włókna o wysokiej wilgotności.
Cząsteczka DNA o wysokiej wilgotności nazywana jest formą B... W warunkach fizjologicznych (niskie stężenie soli, wysoki stopień uwodnienia) dominującym strukturalnym typem DNA jest forma B (główną formą dwuniciowego DNA jest model Watsona-Cricka). Skok helisy takiej cząsteczki wynosi 3,4 nm. Na turę występuje 10 komplementarnych par w postaci skręconych stosów „monet” - zasad azotowych. Stosy są utrzymywane wiązaniami wodorowymi pomiędzy dwiema przeciwstawnymi „monetami” stosu i są „owinięte” w dwie wstążki szkieletu fosfodiestrowego skręcone w prawostronną spiralę. Płaszczyzny zasad azotowych są prostopadłe do osi spirali. Sąsiadujące pary komplementarne są obracane względem siebie o 36 °. Średnica helisy wynosi 20 Å, przy czym nukleotyd purynowy wynosi 12 Å, a nukleotyd pirymidynowy 8 Å.
Cząsteczka DNA o niższej wilgotności nazywana jest formą A... Forma A powstaje w warunkach mniejszego uwodnienia i większej zawartości jonów Na+ lub K+. Ta szersza prawoskrętna konformacja ma 11 par zasad na obrót. Płaszczyzny zasad azotowych mają większe nachylenie do osi spirali, są odchylone od osi normalnej do osi spirali o 20°. W związku z tym następuje obecność wewnętrznej pustej przestrzeni o średnicy 5 Å. Odległość między sąsiednimi nukleotydami wynosi 0,23 nm, długość cewki 2,5 nm, a średnica helisy 2,3 nm.
Pierwotnie uważano, że forma A DNA jest mniej ważna. Jednak później stało się jasne, że forma A DNA, podobnie jak forma B, ma ogromne znaczenie biologiczne. Helisa RNA-DNA w kompleksie matryca-starter ma formę A, a także helisę RNA-RNA i struktury spinki do włosów RNA (grupa 2'-hydroksylowa rybozy nie pozwala cząsteczkom RNA tworzyć formy B) . Forma A DNA została znaleziona w kontrowersji. Stwierdzono, że forma A DNA jest 10 razy bardziej odporna na promienie UV niż forma B.
Forma A i forma B są nazywane formy kanoniczne DNA.
Formularze C-E również praworęczne, ich powstawanie można zaobserwować tylko w specjalnych eksperymentach i najwyraźniej nie istnieją one in vivo. DNA w formie C ma strukturę podobną do B-DNA. Liczba par zasad na obrót wynosi 9,33, długość helisy 3,1 nm. Pary baz są nachylone pod kątem 8 stopni w stosunku do pozycji prostopadłej do osi. Rowki mają podobny rozmiar do rowków B-DNA. W tym przypadku rowek główny jest nieco płytszy, a rowek mniejszy jest głębszy. Naturalne i syntetyczne polinukleotydy DNA mogą przejść do formy C.
| Tabela 1. Charakterystyka niektórych typów struktur DNA | |||
| Typ spiralny | A | b | Z |
| Spiralny krok | 0,32 nm | 3,38 nm | 4,46 nm |
| Skręt spiralny | Prawidłowy | Prawidłowy | Lewo |
| Pary zasad na turę | 11 | 10 | 12 |
| Odległość między płaszczyznami bazowymi | 0,256 nm | 0,338 nm | 0,371 nm |
| Konformacja wiązania glikozydowego | anty | anty | wybryk syn-g |
| Konformacja cyklu furanozowego | C3 "-endo | C2 "-endo | C3 "-endo-G C2 "-endo-c |
| Szerokość rowka mały / duży | 1,11 / 0,22 nm | 0,57 / 1,17 nm | 0,2 / 0,88 nm |
| Głębokość rowka, mała / duża | 0,26 / 1,30 nm | 0,82 / 0,85 nm | 1,38 / 0,37 nm |
| Średnica spirali | 2,3 nm | 2,0 nm | 1,8 nm |
Elementy strukturalne DNA
(niekanoniczne struktury DNA)
Strukturalne elementy DNA obejmują niezwykłe struktury, ograniczone pewnymi specjalnymi sekwencjami:
|

DNA w kształcie litery Z został odkryty w 1979 roku podczas badania heksanukleotydu d (CG) 3 -. Został odkryty przez profesora MIT Alexandra Richa i jego współpracowników. Forma Z stała się jednym z najważniejszych elementów strukturalnych DNA ze względu na fakt, że jej powstawanie obserwowano w regionach DNA, w których puryny występują naprzemiennie z pirymidynami (np. 5'-HCGCH-3') lub w powtórzeniach 5' -CHCH-3' zawierający metylowaną cytozynę. Istotnym warunkiem powstania i stabilizacji Z-DNA była obecność nukleotydów purynowych w konformacji syn, naprzemiennie z zasadami pirymidynowymi w konformacji anty.
Naturalne cząsteczki DNA na ogół istnieją w prawidłowej formie B, jeśli nie zawierają sekwencji typu (CH) n. Jeśli jednak takie sekwencje są zawarte w DNA, wówczas te regiony, gdy zmienia się siła jonowa roztworu lub kationy neutralizujące ładunek ujemny na szkielecie fosfodiestrowym, mogą przekształcić się w formę Z, podczas gdy inne regiony DNA w łańcuchu pozostają w klasyczna forma B. Możliwość takiego przejścia wskazuje, że dwa łańcuchy w podwójnej helisie DNA są w stanie dynamicznym i mogą się rozwijać względem siebie, przechodząc od formy prawej do lewej i odwrotnie. Biologiczne konsekwencje takiej labilności, która umożliwia konformacyjne przekształcenia struktury DNA, nie są jeszcze w pełni poznane. Uważa się, że regiony Z-DNA odgrywają rolę w regulacji ekspresji niektórych genów i biorą udział w rekombinacji genetycznej.
Forma Z DNA to lewoskrętna podwójna helisa, w której szkielet fosfodiestrowy znajduje się zygzakowato wzdłuż osi cząsteczki. Stąd nazwa cząsteczki (zygzak) -DHK. Z-DNA jest najmniej skręconym (12 par zasad na obrót) i najcieńszym znanym w naturze. Odległość między sąsiednimi nukleotydami wynosi 0,38 nm, długość cewki 4,56 nm, a średnica Z-DNA 1,8 nm. Ponadto, wygląd zewnętrzny ta cząsteczka DNA wyróżnia się obecnością jednego rowka.
Forma Z DNA została znaleziona w komórkach prokariotycznych i eukariotycznych. Obecnie uzyskano przeciwciała, które potrafią odróżnić formę Z od formy B DNA. Przeciwciała te wiążą się z określonymi regionami gigantycznych chromosomów komórek gruczołów ślinowych Drosophila (Dr. melanogaster). Reakcja wiązania jest łatwa do prześledzenia ze względu na niezwykłą strukturę tych chromosomów, w której gęstsze regiony (dyski) kontrastują z mniej gęstymi regionami (interdyskami). Regiony Z-DNA znajdują się w międzypasmach. Wynika z tego, że forma Z faktycznie istnieje w warunkach naturalnych, chociaż rozmiary poszczególnych sekcji formy Z są nadal nieznane.

(shifters) to najbardziej znane i najczęściej spotykane sekwencje zasad w DNA. Palindrom to słowo lub fraza, które czyta się od lewej do prawej i odwrotnie w ten sam sposób. Przykładami takich słów lub wyrażeń są: SHALASH, KAZAK, POTOP, RÓŻA SPADŁA NA ŁAPA AZORA. W odniesieniu do regionów DNA termin ten (palindrom) oznacza tę samą przemianę nukleotydów w łańcuchu od prawej do lewej i od lewej do prawej (jak litery w słowie „chata” itp.).
Palindrom charakteryzuje się obecnością odwróconych powtórzeń sekwencji zasad o symetrii drugiego rzędu w odniesieniu do dwóch nici DNA. Takie sekwencje, z całkowicie zrozumiałego powodu, są samouzupełniające się i mają tendencję do tworzenia struktur typu spinka do włosów lub krzyża (ryc.). Spinki do włosów pomagają białkom regulacyjnym rozpoznać miejsce, w którym odpisywany jest tekst genetyczny DNA chromosomu.
W przypadkach, gdy odwrócone powtórzenie jest obecne na tej samej nici DNA, sekwencja ta nazywana jest powtórzeniem lustrzanym. Powtórzenia lustrzane nie posiadają właściwości samokomplementarności, a zatem nie są zdolne do tworzenia struktur typu spinka do włosów lub krzyża. Sekwencje tego typu znajdują się praktycznie we wszystkich dużych cząsteczkach DNA i mogą wahać się od kilku par zasad do kilku tysięcy par zasad.
Obecność palindromów w postaci struktur krzyżowych w komórkach eukariotycznych nie została udowodniona, chociaż w komórkach E. coli znaleziono szereg struktur krzyżowych in vivo. Obecność sekwencji komplementarnych do siebie w RNA lub jednoniciowym DNA jest głównym powodem fałdowania łańcucha nukleinowego w roztworach w pewną strukturę przestrzenną, charakteryzującą się tworzeniem wielu „szpilek do włosów”.

DNA w formie H jest helisą utworzoną przez trzy nici DNA - potrójną helisę DNA. Jest to kompleks podwójnej helisy Watsona-Cricka z trzecią jednoniciową nicią DNA, która wpasowuje się w jej duży rowek, z utworzeniem tzw. pary Hoogsteena.
Powstanie takiego tripleksu następuje w wyniku pofałdowania podwójnej helisy DNA w taki sposób, że połowa jej odcinka pozostaje w formie podwójnej helisy, a druga połowa jest rozłączona. W tym przypadku jedna z rozłączonych spiral tworzy nową strukturę z pierwszą połową podwójnej spirali - potrójną spiralą, a druga okazuje się być niestrukturalna, w postaci odcinka jednożyłowego. Cechą tego przejścia strukturalnego jest ostra zależność od pH ośrodka, którego protony stabilizują nową strukturę. Ze względu na tę cechę nową strukturę nazwano formą H DNA, której powstawanie stwierdzono w superskręconych plazmidach zawierających regiony homopurynowo-homopirymidynowe, będące powtórzeniem lustrzanym.
W dalszych badaniach pojawiła się możliwość strukturalnego przejścia niektórych dwuniciowych polinukleotydów homopurynowo-homopirymidynowych z wytworzeniem struktury trójniciowej zawierającej:
- jedna nić homopurynowa i dwie nici homopirymidynowe ( Py-Pu-Py triplex) [Interakcja Hoogsteena].
Bloki składowe tripleksu Py-Pu-Py to triady kanoniczne izomorficzne z CGC+ i TAT. Stabilizacja tripleksu wymaga protonowania triady CGC +, dlatego te tripleksy zależą od pH roztworu.
- jedna nici homopirymidyny i dwie nici homopuryny ( Triplex Py-Pu-Pu) [odwrotna interakcja Hoogsteena].
Bloki składowe tripleksu Py-Pu-Pu są kanonicznie izomorficzne z triadami CGG i TAA. Istotną właściwością tripleksów Py-Pu-Pu jest zależność ich stabilności od obecności jonów podwójnie naładowanych, a do stabilizacji tripleksów o różnych sekwencjach wymagane są różne jony. Ponieważ tworzenie tripleksów Py-Pu-Pu nie wymaga protonowania ich składowych nukleotydów, takie tripleksy mogą istnieć w obojętnym pH.
Uwaga: bezpośrednie i odwrotne oddziaływanie Hoogsteena tłumaczy się symetrią 1-metylotyminy: obrót o 180 ° prowadzi do tego, że atom O4 zostaje zastąpiony atomem O2, podczas gdy układ wiązań wodorowych zostaje zachowany.
Istnieją dwa rodzaje potrójnych spiral:
- równoległe potrójne helisy, w których polaryzacja trzeciej nici pokrywa się z polaryzacją łańcucha homopuryny dupleksu Watsona-Cricka
- antyrównoległe potrójne helisy, w których bieguny trzeciego i homopurynowego łańcucha są przeciwne.

G-kwadrupleks- 4-niciowy DNA. Taka struktura powstaje, gdy istnieją cztery guaniny, które tworzą tzw. G-kwadrupleks - okrągły taniec czterech guanin.
Pierwsze wzmianki o możliwości powstania takich struktur pojawiły się na długo przed przełomową pracą Watsona i Cricka – w 1910 roku. Następnie niemiecki chemik Ivar Bang odkrył, że jeden ze składników DNA - kwas guanozynowy - tworzy żele w wysokich stężeniach, podczas gdy inne składniki DNA nie mają tej właściwości.
W 1962 roku metodą dyfrakcji rentgenowskiej udało się ustalić strukturę komórkową tego żelu. Okazało się, że składa się z czterech reszt guaninowych, łączących się w okrąg i tworzących charakterystyczny kwadrat. W środku wiązanie jest podtrzymywane przez jon metalu (Na, K, Mg). Te same struktury mogą powstawać w DNA, jeśli zawiera dużo guaniny. Te płaskie kwadraty (kwartety G) są ułożone w stos, tworząc dość stabilne, gęste struktury (kwadrupleksy G).
Cztery oddzielne nici DNA mogą być splecione w czteroniciowe kompleksy, ale jest to raczej wyjątek. Częściej pojedyncza nić kwasu nukleinowego jest po prostu wiązana w węzeł, tworząc charakterystyczne zgrubienia (na przykład na końcach chromosomów) lub dwuniciowy DNA tworzy lokalny kwadrupleks w pewnym regionie bogatym w guaninę.
Najbardziej badane jest istnienie kwadrupleksów na końcach chromosomów - na telomerach iw onkopromotorach. Jednak do tej pory nie jest znane pełne zrozumienie lokalizacji takiego DNA w ludzkich chromosomach.
Wszystkie te niezwykłe struktury DNA w formie liniowej są niestabilne w porównaniu z formą B DNA. Jednak DNA często występuje w kolistej formie naprężeń topologicznych, gdy ma to, co nazywa się superzwijaniem. W tych warunkach łatwo tworzą się niekanoniczne struktury DNA: formy Z, krzyżówki i spinki do włosów, formy H, kwadrupleksy guaninowe i motyw i.
- Forma superskręcona - zauważa się, gdy jest izolowana z jądra komórkowego bez uszkadzania szkieletu pentozofosforanowego. Ma kształt super skręconych zamkniętych pierścieni. W stanie superskręconym podwójna helisa DNA jest „skręcana na siebie” co najmniej raz, to znaczy zawiera co najmniej jedną superskrętkę (przyjmuje postać ósemki).
- Zrelaksowany stan DNA jest obserwowany przy pojedynczym zerwaniu (zerwaniu jednej nici). W tym przypadku supercewki znikają, a DNA przyjmuje postać zamkniętego pierścienia.
- Liniowa forma DNA - obserwowana, gdy dwie nici podwójnej helisy są zerwane.
Trzeciorzędowa struktura DNA
Trzeciorzędowa struktura DNA powstaje w wyniku dodatkowego skręcenia w przestrzeni dwuniciowej cząsteczki - jej superzwijania. Superzwijanie się cząsteczki DNA w komórkach eukariotycznych, w przeciwieństwie do prokariotów, odbywa się w postaci kompleksów z białkami.
Prawie cały eukariotyczny DNA znajduje się w chromosomach jąder, tylko niewielka jego ilość jest zawarta w mitochondriach, roślinach i plastydach. Główną substancją chromosomów komórek eukariotycznych (w tym chromosomów ludzkich) jest chromatyna, składająca się z dwuniciowego DNA, białek histonowych i niehistonowych.
Białka histonów chromatyny
Histony to proste białka, które stanowią do 50% chromatyny. We wszystkich badanych komórkach zwierzęcych i roślinnych stwierdzono pięć głównych klas histonów: H1, H2A, H2B, H3, H4, różniące się wielkością, składem aminokwasowym i wartością ładunku (zawsze dodatnie).
Histon H1 ssaka składa się z pojedynczego łańcucha polipeptydowego składającego się z około 215 aminokwasów; rozmiary innych histonów wahają się od 100 do 135 aminokwasów. Wszystkie są spiralnie zwinięte i skręcone w kulkę o średnicy około 2,5 nm, zawierają niezwykle dużą ilość dodatnio naładowanych aminokwasów lizyny i argininy. Histony mogą być acetylowane, metylowane, fosforylowane, poli(ADP)-rybozylowane, a histony H2A i H2B są kowalencyjnie związane z ubikwityną. Jaka jest rola takich modyfikacji w tworzeniu struktury i pełnieniu funkcji przez histony nie została jeszcze w pełni wyjaśniona. Zakłada się, że jest to ich zdolność do interakcji z DNA i zapewnienia jednego z mechanizmów regulacji działania genów.
Histony oddziałują z DNA głównie poprzez wiązania jonowe (mostki solne) utworzone między ujemnie naładowanymi grupami fosforanowymi DNA a dodatnio naładowanymi resztami lizyny i argininy w histonach.
Białka chromatyny niehistonowej
W przeciwieństwie do histonów, białka niehistonowe są bardzo zróżnicowane. Wyizolowano do 590 różnych frakcji niehistonowych białek wiążących DNA. Nazywa się je również białkami kwaśnymi, ponieważ w ich strukturze przeważają aminokwasy kwaśne (są polianionami). Specyficzna regulacja aktywności chromatyny jest związana z różnymi białkami niehistonowymi. Na przykład enzymy wymagane do replikacji i ekspresji DNA mogą tymczasowo wiązać się z chromatyną. Inne białka, na przykład uczestniczące w różnych procesach regulacyjnych, wiążą się z DNA tylko w określonych tkankach lub na określonych etapach różnicowania. Każde białko jest komplementarne do określonej sekwencji nukleotydowej DNA (miejsce DNA). Ta grupa obejmuje:
- rodzina specyficznych dla miejsca białek palca cynkowego. Każdy palec cynkowy rozpoznaje określone miejsce składające się z 5 par nukleotydów.
- rodzina białek site-specific - homodimerów. Fragment takiego białka w kontakcie z DNA ma strukturę helisa-turn-helix.
- Białka żelowe o wysokiej mobilności (białka HMG) to grupa białek strukturalnych i regulatorowych, które są stale związane z chromatyną. Mają masę cząsteczkową poniżej 30 kDa i charakteryzują się wysoką zawartością naładowanych aminokwasów. Ze względu na niską masę cząsteczkową białka HMG są wysoce ruchliwe podczas elektroforezy w żelu poliakrylamidowym.
- enzymy replikacji, transkrypcji i naprawy.
Przy udziale białek strukturalnych, regulatorowych oraz enzymów biorących udział w syntezie DNA i RNA nić nukleosomów przekształcana jest w wysoce skondensowany kompleks białek i DNA. Powstała struktura jest 10 000 razy krótsza niż oryginalna cząsteczka DNA.

Chromatyna
Chromatyna to kompleks białek z jądrowym DNA i substancje nieorganiczne... Większość chromatyny jest nieaktywna. Zawiera ciasno upakowane, skondensowane DNA. To heterochromatyna. Rozróżnij konstytutywną, genetycznie nieaktywną chromatynę (satelitarne DNA), składającą się z niewyrażonych regionów, i opcjonalną - nieaktywną w wielu pokoleniach, ale w pewnych okolicznościach zdolną do ekspresji.
Aktywna chromatyna (euchromatyna) jest nieskondensowana, tj. zapakowane mniej ciasno. W różnych komórkach jego zawartość waha się od 2 do 11%. W komórkach mózgu jest to przede wszystkim 10-11%, w komórkach wątroby 3-4 i nerek 2-3%. Odnotowano aktywną transkrypcję euchromatyny. Jednocześnie jego strukturalna organizacja pozwala na wykorzystanie tej samej informacji genetycznej DNA właściwej dla danego typu organizmu na różne sposoby w wyspecjalizowanych komórkach.
W mikroskopie elektronowym obraz chromatyny przypomina koralik: sferyczne zgrubienia o wielkości około 10 nm, oddzielone nitkowatymi mostkami. Te kuliste zgrubienia nazywane są nukleosomami. Nukleosom to strukturalna jednostka chromatyny. Każdy nukleosom zawiera superskręcony segment DNA o długości 146 par zasad, nawinięty z utworzeniem 1,75 zwojów w lewo na rdzeniu nukleosomu. Rdzeń nukleosomalny to oktamer histonowy składający się z histonów H2A, H2B, H3 i H4, po dwie cząsteczki każdego typu (ryc. 9), który wygląda jak dysk o średnicy 11 nm i grubości 5,7 nm. Piąty histon, H1, nie jest częścią jądra nukleosomalnego i nie bierze udziału w procesie nawijania DNA na oktamerze histonowym. Kontaktuje się z DNA, gdzie podwójna helisa wchodzi i wychodzi z rdzenia nukleosomalnego. Są to międzykorowe (łącznikowe) regiony DNA, których długość zmienia się w zależności od typu komórki od 40 do 50 par zasad. W rezultacie zmienia się również długość fragmentu DNA zawartego w nukleosomie (od 186 do 196 par nukleotydów).
Nukleosom zawiera około 90% DNA, reszta to łącznik. Uważa się, że nukleosomy są fragmentami „cichej” chromatyny, a łącznik jest aktywny. Jednak nukleosomy mogą się rozwijać i stać się liniowe. Rozwinięte nukleosomy są już aktywną chromatyną. W ten sposób wyraźnie manifestuje się zależność funkcji od struktury. Można przypuszczać, że im więcej chromatyny znajduje się w składzie kulistych nukleosomów, tym jest mniej aktywna. Oczywiście w różnych komórkach nierówny udział chromatyny spoczynkowej jest związany z liczbą takich nukleosomów.
Na zdjęciach z mikroskopu elektronowego, w zależności od warunków izolacji i stopnia rozciągnięcia, chromatyna może wyglądać nie tylko jako długa nić z pogrubieniami – „koralikami” nukleosomów, ale także jako krótsza i gęstsza fibryl (włókno) o średnicy 30 nm, którego powstawanie obserwuje się podczas oddziaływania histon H1 związany z regionem łącznikowym DNA i histon H3, co prowadzi do dodatkowego skręcenia helisy sześciu nukleosomów na obrót z utworzeniem solenoidu o średnicy 30 nm. W takim przypadku białko histonowe może zakłócać transkrypcję wielu genów, a tym samym regulować ich aktywność.
W wyniku opisanych powyżej oddziaływań DNA z histonami odcinek podwójnej helisy DNA 186 par zasad o średniej średnicy 2 nm i długości 57 nm przekształca się w helisę o średnicy 10 nm i długość 5 nm. Po ściśnięciu tej spirali we włókno o średnicy 30 nm stopień kondensacji wzrasta sześciokrotnie.
Ostatecznie upakowanie dupleksu DNA z pięcioma histonami powoduje 50-krotną kondensację DNA. Jednak nawet tak wysoki stopień kondensacji nie może wyjaśnić prawie 50 000 - 100 000-krotnego zagęszczenia DNA w chromosomie metafazowym. Niestety szczegóły dalszego upakowania chromatyny do chromosomu metafazowego nie są jeszcze znane, dlatego można rozważać jedynie ogólne cechy tego procesu.
Poziomy zagęszczenia DNA w chromosomach
Każda cząsteczka DNA jest upakowana w oddzielnym chromosomie. Ludzkie komórki diploidalne zawierają 46 chromosomów, które znajdują się w jądrze komórkowym. Całkowita długość DNA wszystkich chromosomów komórki wynosi 1,74 m, ale średnica jądra, w którym upakowane są chromosomy, jest miliony razy mniejsza. Takie zwarte upakowanie DNA w chromosomach i chromosomach w jądrze komórkowym zapewniają różne białka histonowe i niehistonowe, które oddziałują w określonej sekwencji z DNA (patrz powyżej). Zagęszczenie DNA w chromosomach umożliwia zmniejszenie jego wymiarów liniowych o około 10 000 razy – konwencjonalnie z 5 cm do 5 mikronów. Istnieje kilka poziomów zagęszczenia (ryc. 10).


- Podwójna helisa DNA to ujemnie naładowana cząsteczka o średnicy 2 nm i długości kilku cm.
- poziom nukleosomalny- chromatyna wygląda w mikroskopie elektronowym jak łańcuch "kulek" - nukleosomów - "na sznurku". Nukleosom jest uniwersalną jednostką strukturalną, która znajduje się zarówno w euchromatynie, jak i heterochromatynie, w jądrze międzyfazowym i chromosomach metafazowych.
Nukleosomalny poziom zagęszczenia zapewniają specjalne białka - histony. Osiem dodatnio naładowanych domen histonowych tworzy rdzeń (rdzeń) nukleosomu, wokół którego owinięta jest ujemnie naładowana cząsteczka DNA. Skutkuje to 7-krotnym skróceniem, przy czym średnica wzrasta od 2 do 11 nm.
- poziom elektrozaworu
Poziom organizacji chromosomów solenoidu charakteryzuje się skręceniem włókna nukleosomalnego i tworzeniem z niego grubszych włókienek o średnicy 20-35 nm - solenoidów lub superbidów. Skok solenoidu wynosi 11 nm, na obrót przypada około 6-10 nukleosomów. Upakowanie solenoidu jest uważane za bardziej prawdopodobne niż superbid, zgodnie z którym fibryl chromatyny o średnicy 20-35 nm jest łańcuchem granulek lub superbidów, z których każdy składa się z ośmiu nukleosomów. Na poziomie solenoidu liniowy rozmiar DNA zmniejsza się 6-10 razy, średnica wzrasta do 30 nm.
- poziom pętli
Poziom pętli zapewniają białka wiążące DNA niespecyficzne względem histonów, które rozpoznają i wiążą się z określonymi sekwencjami DNA, tworząc pętle o długości około 30-300 kb. Pętla zapewnia ekspresję genów, tj. E. pętla jest nie tylko formacją strukturalną, ale także funkcjonalną. Skrócenie na tym poziomie występuje 20-30 razy. Średnica wzrasta do 300 nm. Na preparatach cytologicznych widoczne są pętlowe struktury typu „lamp-brush” w oocytach płazów. Te pętle są najwyraźniej superskręcone i reprezentują domeny DNA, które prawdopodobnie odpowiadają jednostkom transkrypcji i replikacji chromatyny. Specyficzne białka utrwalają podstawy pętli i być może niektóre z ich wewnętrznych obszarów. Organizacja domen w kształcie pętli promuje fałdowanie chromatyny w chromosomach metafazowych w struktury helikalne wyższych rzędów.
- poziom domeny
Poziom domeny organizacji chromosomów nie został dostatecznie zbadany. Na tym poziomie obserwuje się powstawanie domen pętli – struktury nitek (włókien) o grubości 25-30 nm, które zawierają 60% białka, 35% DNA i 5% RNA, są praktycznie niewidoczne we wszystkich fazach komórki cyklu z wyjątkiem mitozy i są nieco losowo rozmieszczone w jądrze komórkowym. Na preparatach cytologicznych widoczne są pętlowe struktury typu „lamp-brush” w oocytach płazów.
Domeny pętli łączą swoje zasady z wewnątrzjądrową macierzą białkową w tzw. osadzonych miejscach przyłączania, często określanych jako sekwencje MAR/SAR (MAR, z angielskiego regionu związanego z macierzą; SAR, z angielskich regionów przyłączenia rusztowania) – fragmenty DNA kilka sto par zasad, które charakteryzują się dużą zawartością (>65%) par zasad A/T. Każda domena wydaje się mieć jeden początek replikacji i działa jako samodzielna jednostka superskręcona. Każda zapętlona domena zawiera wiele jednostek transkrypcyjnych, których funkcjonowanie jest prawdopodobnie skoordynowane – cała domena jest albo w stanie aktywnym, albo nieaktywnym.
Na poziomie domeny, w wyniku sekwencyjnego upakowania chromatyny, wymiary liniowe DNA zmniejszają się około 200-krotnie (700 nm).
- poziom chromosomów
Na poziomie chromosomalnym kondensacja chromosomu profazy w metafazę zachodzi z zagęszczeniem zapętlonych domen wokół osi osiowej białek niehistonowych. Temu superzwijaniu towarzyszy fosforylacja wszystkich cząsteczek H1 w komórce. W rezultacie chromosom metafazowy można przedstawić jako ciasno upakowane pętle solenoidu zwinięte w ciasną spiralę. Typowy ludzki chromosom może zawierać do 2600 pętli. Grubość takiej struktury sięga 1400 nm (dwie chromatydy), natomiast cząsteczka DNA jest skrócona 104 razy, tj. z 5 cm rozciągniętego DNA do 5 μm.
Funkcje chromosomów
W interakcji z mechanizmami pozachromosomalnymi chromosomy zapewniają
- przechowywanie informacji dziedzicznych
- wykorzystanie tych informacji do tworzenia i utrzymywania organizacji komórkowej
- regulacja odczytywania informacji dziedzicznych
- samopodwojenie materiału genetycznego
- przeniesienie materiału genetycznego z komórki macierzystej na córkę.
Istnieją dowody na to, że gdy region chromatyny jest aktywowany, tj. podczas transkrypcji najpierw usuwa się z niego odwracalnie histon H1, a następnie oktet histonu. Powoduje to dekondensację chromatyny, czyli sekwencyjne przejście 30-nanometrowego włókna chromatyny w 10-nanometrowe włókno i jego dalsze rozwinięcie w regiony wolnego DNA, tj. utrata struktury nukleosomalnej.
Wszyscy wiemy, że wygląd człowieka, niektóre nawyki, a nawet choroby są dziedziczone. Cała ta informacja o żywej istocie jest zakodowana w genach. Jak więc wyglądają te przysłowiowe geny, jak działają i gdzie się znajdują?
Tak więc nośnikiem wszystkich genów każdej osoby lub zwierzęcia jest DNA. Związek ten został odkryty przez Johanna Friedricha Mieschera w 1869 r. Chemicznie DNA jest kwasem dezoksyrybonukleinowym. Co to znaczy? W jaki sposób ten kwas niesie kod genetyczny całego życia na naszej planecie?
Zacznijmy od przyjrzenia się, gdzie znajduje się DNA. W komórce ludzkiej znajduje się wiele organelli, które pełnią różne funkcje. DNA znajduje się w jądrze. Jądro jest małą organellą otoczoną specjalną błoną przechowującą cały materiał genetyczny - DNA.
Jaka jest struktura cząsteczki DNA?
Przede wszystkim spójrzmy, czym jest DNA. DNA to bardzo długa cząsteczka zbudowana z elementów budulcowych – nukleotydów. Istnieją 4 rodzaje nukleotydów - adenina (A), tymina (T), guanina (G) i cytozyna (C). Łańcuch nukleotydów wygląda schematycznie tak: GGAATCTAAG... To jest sekwencja nukleotydów, która jest łańcuchem DNA.Struktura DNA została po raz pierwszy odszyfrowana w 1953 roku przez Jamesa Watsona i Francisa Cricka.
W jednej cząsteczce DNA znajdują się dwa łańcuchy nukleotydów, które są spiralnie skręcone wokół siebie. Jak te łańcuchy nukleotydów sklejają się i skręcają w spiralę? Zjawisko to wynika z właściwości komplementarności. Komplementarność oznacza, że tylko niektóre nukleotydy (komplementarne) mogą znajdować się naprzeciwko siebie w dwóch niciach. Tak więc w przeciwieństwie do adeniny zawsze występuje tymina, a w przeciwieństwie do guaniny zawsze jest tylko cytozyna. Tak więc guanina jest komplementarna do cytozyny, a adenina jest komplementarna do tyminy.Takie pary nukleotydów naprzeciw siebie w różnych niciach są również nazywane komplementarnymi.
 Można go schematycznie przedstawić w następujący sposób:
Można go schematycznie przedstawić w następujący sposób:
G - C
T - A
T - A
C - G
Te komplementarne pary A - T i G - C tworzą wiązanie chemiczne między nukleotydami pary, a wiązanie między G i C jest silniejsze niż między A i T. Wiązanie powstaje ściśle między komplementarnymi zasadami, to znaczy utworzenie wiązania między niekomplementarnymi G i A jest niemożliwe.
Pakowanie DNA, w jaki sposób nić DNA staje się chromosomem?
Dlaczego te łańcuchy nukleotydów DNA również skręcają się wokół siebie? Dlaczego jest to potrzebne? Faktem jest, że liczba nukleotydów jest ogromna i zajmuje dużo miejsca, aby pomieścić tak długie łańcuchy. Z tego powodu dochodzi do spiralnego skręcenia dwóch nici DNA wokół siebie. Ten fenomen nazywa się spiralizacją. W wyniku spiralizacji nici DNA skracają się 5-6 razy.Niektóre cząsteczki DNA są aktywnie wykorzystywane przez organizm, podczas gdy inne są rzadko używane. Takie rzadko używane cząsteczki DNA, oprócz spiralizacji, przechodzą jeszcze bardziej zwarte „upakowanie”. Ten kompaktowy pakiet nazywa się superzwijaniem i skraca nić DNA 25-30 razy!
Jak przebiega pakowanie nici DNA?
 Do superzwijania stosuje się białka histonowe, które mają wygląd i strukturę pręta lub szpuli nici. Na tych „zwojach” – białkach histonowych nawinięte są spiralne nici DNA. W ten sposób długa nić staje się bardzo zwarta i zajmuje bardzo mało miejsca.
Do superzwijania stosuje się białka histonowe, które mają wygląd i strukturę pręta lub szpuli nici. Na tych „zwojach” – białkach histonowych nawinięte są spiralne nici DNA. W ten sposób długa nić staje się bardzo zwarta i zajmuje bardzo mało miejsca. Jeśli konieczne jest użycie tej lub innej cząsteczki DNA, następuje proces „odwijania”, to znaczy, że nić DNA jest „odwijana” z „cewki” - białka histonowego (jeśli było na nim nawinięte) i rozwija się z spirala w dwa równoległe łańcuchy. A kiedy cząsteczka DNA jest w tak nieskręconym stanie, można z niej odczytać niezbędną informację genetyczną. Co więcej, odczyt informacji genetycznej odbywa się tylko z nieskręconych nici DNA!
Nazywa się zestaw superskręconych chromosomów heterochromatyna oraz chromosomy dostępne do odczytywania informacji - euchromatyna.
Czym są geny, jaki jest ich związek z DNA?
Przyjrzyjmy się teraz, czym są geny. Wiadomo, że istnieją geny, które decydują o grupie krwi, kolorze oczu, włosów, skórze i wielu innych właściwościach naszego organizmu. Gen to ściśle określony odcinek DNA, składający się z określonej liczby nukleotydów znajdujących się w ściśle określonej kombinacji. Lokalizacja w ściśle określonym obszarze DNA oznacza, że określonemu genowi zostało przypisane jego miejsce i nie ma możliwości zmiany tego miejsca. Właściwe jest takie porównanie: człowiek mieszka na pewnej ulicy, w pewnym domu i mieszkaniu, a człowiek nie może samowolnie przenieść się do innego domu, mieszkania lub innej ulicy. Pewna liczba nukleotydów w genie oznacza, że każdy gen ma określoną liczbę nukleotydów i nie może stać się mniej lub bardziej. Na przykład gen do produkcji insuliny ma długość 60 par zasad; gen kodujący produkcję hormonu oksytocyny - 370 par zasad. Ścisła sekwencja nukleotydów jest unikalna dla każdego genu i jest ściśle określona. Na przykład sekwencja AATTAATA to fragment genu kodującego produkcję insuliny. W celu uzyskania insuliny wykorzystuje się właśnie taką sekwencję, do uzyskania np. adrenaliny stosuje się inną kombinację nukleotydów. Ważne jest, aby zrozumieć, że tylko pewna kombinacja nukleotydów koduje określony „produkt” (adrenalina, insulina itp.). Taka jest unikalna kombinacja pewnej liczby nukleotydów, stojących na „swoim miejscu” – to jest gen.
Oprócz genów w łańcuchu DNA znajdują się tak zwane „sekwencje niekodujące”. Takie niekodujące sekwencje nukleotydowe regulują pracę genów, wspomagają spiralizację chromosomów oraz wyznaczają początek i koniec genu. Jednak do chwili obecnej rola większości niekodujących sekwencji pozostaje niejasna.
Czym jest chromosom? Chromosomy płciowe
Zbiór genów danej osoby nazywa się genomem. Oczywiście nie da się zmieścić całego genomu w jednym DNA. Genom jest podzielony na 46 par cząsteczek DNA. Jedna para cząsteczek DNA nazywana jest chromosomem. Więc to właśnie te chromosomy, które osoba ma 46 sztuk. Każdy chromosom zawiera ściśle określony zestaw genów, na przykład chromosom 18 zawiera geny kodujące kolor oczu itp. Chromosomy różnią się od siebie długością i kształtem. Najczęstsze formy to X lub Y, ale są też inne. Osoba ma dwa chromosomy o tym samym kształcie, które nazywane są sparowanymi (parami). Ze względu na takie różnice wszystkie sparowane chromosomy są ponumerowane – jest ich 23 par. Oznacza to, że istnieje para chromosomów nr 1, para nr 2, nr 3 itd. Każdy gen odpowiedzialny za daną cechę znajduje się na tym samym chromosomie. We współczesnych wytycznych dla specjalistów lokalizację genu można wskazać np.: chromosom 22, ramię długie.Jakie są różnice między chromosomami?
 Czym jeszcze różnią się chromosomy? Co oznacza termin „długie ramię”? Weźmy chromosomy postaci X. Przecięcie nici DNA może zachodzić ściśle pośrodku (X) lub może również zachodzić nie centralnie. Gdy takie przecięcie nici DNA nie występuje centralnie, to w stosunku do miejsca przecięcia niektóre końce są dłuższe, a inne odpowiednio krótsze. Takie długie końce są zwykle nazywane długim ramieniem chromosomu, a krótkie, odpowiednio, krótkim ramieniem. W chromosomach w formie Y większość z nich zajmują długie ramiona, a krótkie są bardzo małe (nie są nawet wskazane na schematycznym obrazie).
Czym jeszcze różnią się chromosomy? Co oznacza termin „długie ramię”? Weźmy chromosomy postaci X. Przecięcie nici DNA może zachodzić ściśle pośrodku (X) lub może również zachodzić nie centralnie. Gdy takie przecięcie nici DNA nie występuje centralnie, to w stosunku do miejsca przecięcia niektóre końce są dłuższe, a inne odpowiednio krótsze. Takie długie końce są zwykle nazywane długim ramieniem chromosomu, a krótkie, odpowiednio, krótkim ramieniem. W chromosomach w formie Y większość z nich zajmują długie ramiona, a krótkie są bardzo małe (nie są nawet wskazane na schematycznym obrazie). Wielkość chromosomów jest różna: największe to chromosomy par nr 1 i nr 3, najmniejsze to chromosomy par nr 17, nr 19.
Oprócz kształtu i wielkości chromosomy różnią się funkcjami. Spośród 23 par 22 są somatyczne, a 1 seksualna. Co to znaczy? Chromosomy somatyczne determinują wszystkie zewnętrzne oznaki osobnika, zwłaszcza jego reakcje behawioralne, psychotyp dziedziczny, czyli wszystkie cechy i cechy każdej indywidualnej osoby. Para chromosomów płci określa płeć osoby: mężczyzna lub kobieta. Istnieją dwa typy ludzkich chromosomów płci - X (X) i Y (Y). Jeśli są połączone jak XX (X - X) - to jest kobieta, a jeśli XY (X - Y) - mamy przed sobą mężczyznę.
Choroby dziedziczne i uszkodzenia chromosomów
Jednak zdarzają się „awarie” genomu, a następnie u ludzi wykrywane są choroby genetyczne. Na przykład, gdy na 21 parach chromosomów zamiast dwóch znajdują się trzy chromosomy, rodzi się osoba z zespołem Downa.Istnieje wiele mniejszych „awarii” materiału genetycznego, które nie prowadzą do wystąpienia choroby, ale wręcz przeciwnie, nadają dobre właściwości. Wszystkie „awarie” materiału genetycznego nazywane są mutacjami. Mutacje prowadzące do choroby lub pogorszenia właściwości organizmu uważane są za negatywne, a mutacje prowadzące do powstania nowych korzystnych właściwości za pozytywne.
Jednak w odniesieniu do większości chorób, na które dzisiaj cierpią ludzie, nie jest to choroba dziedziczna, a jedynie predyspozycja. Na przykład cukier jest powoli wchłaniany przez ojca dziecka. Nie oznacza to, że dziecko urodzi się z cukrzycą, ale będzie miało predyspozycje. Oznacza to, że jeśli dziecko nadużywa słodyczy i produktów mącznych, rozwinie się u niego cukrzyca.
Dziś tzw predykatywny Medycyna. W ramach tej praktyki lekarskiej identyfikuje się predyspozycje u osoby (na podstawie identyfikacji odpowiednich genów), a następnie podaje mu się zalecenia - jaką dietę stosować, jak prawidłowo zmieniać reżim pracy i odpoczynku, aby nie chorować.
Jak czytać informacje zakodowane w DNA?
Jak możesz odczytać informacje zawarte w DNA? Jak wykorzystuje to jej własne ciało? Samo DNA jest rodzajem matrycy, ale nie prostej, ale zakodowanej. Aby odczytać informacje z matrycy DNA, najpierw przenosi się je na specjalny nośnik – RNA. RNA jest chemicznie kwasem rybonukleinowym. Różni się od DNA tym, że może przejść przez błonę jądrową do komórki, a DNA jest pozbawiony tej zdolności (może znajdować się tylko w jądrze). Zakodowana informacja jest wykorzystywana w samej komórce. Tak więc RNA jest nośnikiem zakodowanej informacji z jądra do komórki.Jak syntetyzuje się RNA, jak syntetyzuje się białko za pomocą RNA?
 Do nici DNA, z których należy „odczytać” informacje, odwinąć się, zbliża się do nich specjalny enzym – „budowniczy” i syntetyzuje komplementarną nić RNA równolegle do nici DNA. Cząsteczka RNA składa się również z 4 rodzajów nukleotydów – adeniny (A), uracylu (U), guaniny (G) i cytozyny (C). W tym przypadku komplementarne są następujące pary: adenina - uracyl, guanina - cytozyna. Jak widać, w przeciwieństwie do DNA, RNA wykorzystuje uracyl zamiast tyminy. Oznacza to, że enzym „budowniczy” działa w następujący sposób: jeśli widzi A w nici DNA, to przyłącza Y do nici RNA, jeśli G, to przyłącza C itd. Tak więc z każdego aktywnego genu podczas transkrypcji powstaje matryca - kopia RNA, która może przejść przez błonę jądrową.
Do nici DNA, z których należy „odczytać” informacje, odwinąć się, zbliża się do nich specjalny enzym – „budowniczy” i syntetyzuje komplementarną nić RNA równolegle do nici DNA. Cząsteczka RNA składa się również z 4 rodzajów nukleotydów – adeniny (A), uracylu (U), guaniny (G) i cytozyny (C). W tym przypadku komplementarne są następujące pary: adenina - uracyl, guanina - cytozyna. Jak widać, w przeciwieństwie do DNA, RNA wykorzystuje uracyl zamiast tyminy. Oznacza to, że enzym „budowniczy” działa w następujący sposób: jeśli widzi A w nici DNA, to przyłącza Y do nici RNA, jeśli G, to przyłącza C itd. Tak więc z każdego aktywnego genu podczas transkrypcji powstaje matryca - kopia RNA, która może przejść przez błonę jądrową. Jak przebiega synteza białka kodowanego przez określony gen?
Po opuszczeniu jądra RNA wchodzi do cytoplazmy. Już w cytoplazmie RNA może być jako macierz osadzony w specjalnych układach enzymatycznych (rybosomach), które mogą syntetyzować, kierując się informacjami RNA, odpowiednią sekwencję aminokwasową białka. Jak wiesz, cząsteczka białka składa się z aminokwasów. W jaki sposób rybosom udaje się dowiedzieć, który aminokwas musi być dołączony do rosnącego łańcucha białkowego? Odbywa się to na podstawie kodu trypletowego. Kod tripletowy oznacza, że sekwencja trzech nukleotydów łańcucha RNA ( tryplet, na przykład HGH) kodują jeden aminokwas (w tym przypadku glicynę). Każdy aminokwas jest kodowany przez określoną trójkę. I tak rybosom „odczytuje” trójkę, określa, który aminokwas powinien zostać dołączony jako następny, czytając informacje w RNA. Powstający łańcuch aminokwasów przybiera określoną formę przestrzenną i staje się białkiem zdolnym do pełnienia przypisanych mu funkcji enzymatycznych, budulcowych, hormonalnych i innych.Białko dla każdego żywego organizmu jest produktem genu. To właśnie białka determinują wszystkie różne właściwości, cechy i zewnętrzne przejawy genów.
Po prawej stronie największa spirala ludzkiego DNA, zbudowana z ludzi na plaży w Warnie (Bułgaria), która 23 kwietnia 2016 r. została wpisana do Księgi Rekordów Guinnessa
Kwas dezoksyrybonukleinowy. Informacje ogólne
DNA (kwas dezoksyrybonukleinowy) jest rodzajem planu życia, złożonym kodem, który zawiera dane dotyczące informacji dziedzicznych. Ta złożona makrocząsteczka jest w stanie przechowywać i przekazywać dziedziczną informację genetyczną z pokolenia na pokolenie. DNA określa takie właściwości każdego żywego organizmu, jak dziedziczność i zmienność. Zakodowane w nim informacje wyznaczają cały program rozwoju każdego żywego organizmu. Czynniki wrodzone genetycznie determinują cały przebieg życia zarówno osoby, jak i dowolnego innego organizmu. Sztuczne lub naturalne efekty środowiska zewnętrznego mogą tylko w niewielkim stopniu wpływać na ogólne nasilenie poszczególnych cech genetycznych lub wpływać na rozwój zaprogramowanych procesów.
Kwas dezoksyrybonukleinowy(DNA) to makrocząsteczka (jedna z trzech głównych, dwie pozostałe to RNA i białka), która zapewnia przechowywanie, przekazywanie z pokolenia na pokolenie oraz realizację programu genetycznego dla rozwoju i funkcjonowania organizmów żywych. DNA zawiera informacje o budowie różnych typów RNA i białek.
W komórkach eukariotycznych (zwierzęta, rośliny i grzyby) DNA znajduje się w jądrze komórkowym jako część chromosomów, a także w niektórych organellach komórkowych (mitochondriach i plastydach). W komórkach organizmów prokariotycznych (bakterii i archeonów) do błony komórkowej przyczepia się od wewnątrz okrągłą lub liniową cząsteczkę DNA, tzw. nukleoid. Oni i niższe eukarionty (na przykład drożdże) również mają małe, autonomiczne, przeważnie koliste cząsteczki DNA zwane plazmidami.
Z chemicznego punktu widzenia DNA to długa cząsteczka polimeru zbudowana z powtarzających się bloków – nukleotydów. Każdy nukleotyd składa się z zasady azotowej, cukru (deoksyrybozy) i grupy fosforanowej. Wiązania między nukleotydami w łańcuchu powstają z powodu dezoksyrybozy ( Z) i fosforanów ( F) grupy (wiązania fosfodiestrowe).

Ryż. 2. Nukletyd składa się z zasady azotowej, cukru (deoksyrybozy) i grupy fosforanowej
W przeważającej większości przypadków (z wyjątkiem niektórych wirusów zawierających jednoniciowy DNA) makrocząsteczka DNA składa się z dwóch łańcuchów zorientowanych względem siebie przez zasady azotowe. Ta dwuniciowa cząsteczka jest skręcona w linii śrubowej.
W DNA występują cztery rodzaje zasad azotowych (adenina, guanina, tymina i cytozyna). Zasady azotowe jednego z łańcuchów są połączone z zasadami azotowymi drugiego łańcucha wiązaniami wodorowymi zgodnie z zasadą komplementarności: adenina jest połączona tylko z tyminą ( W), guanina - tylko z cytozyną ( G-C). To właśnie te pary tworzą „poprzeczki” spiralnej „klatki schodowej” DNA (patrz: ryc. 2, 3 i 4).

Ryż. 2. Zasady azotowe
Sekwencja nukleotydów pozwala „zakodować” informacje o różne rodzaje RNA, z których najważniejsze to informacyjne lub informacyjne (mRNA), rybosomalne (rRNA) i transportowe (tRNA). Wszystkie te typy RNA są syntetyzowane na matrycy DNA poprzez skopiowanie sekwencji DNA do sekwencji RNA syntetyzowanej w procesie transkrypcji i biorą udział w biosyntezie białek (proces translacji). Oprócz sekwencji kodujących DNA komórki zawiera sekwencje, które pełnią funkcje regulacyjne i strukturalne.

Ryż. 3. Replikacja DNA
Lokalizacja podstawowych kombinacji chemicznych związków DNA oraz relacje ilościowe między tymi kombinacjami zapewniają kodowanie informacji dziedzicznej.
Edukacja nowe DNA (replikacja)
- Proces replikacji: rozwijanie podwójnej helisy DNA - synteza komplementarnych nici przez polimerazę DNA - tworzenie dwóch cząsteczek DNA z jednej.
- Podwójna helisa „rozpina się” na dwie gałęzie, gdy enzymy rozrywają wiązanie między parami zasad związków chemicznych.
- Każda gałąź to element nowego DNA. Nowe pary zasad są połączone w tej samej kolejności, co w gałęzi macierzystej.
Po zakończeniu duplikacji powstają dwie niezależne helisy, utworzone ze związków chemicznych rodzicielskiego DNA i posiadające ten sam kod genetyczny. W ten sposób DNA jest w stanie przetrawić informacje z komórki do komórki.
Więcej szczegółowych informacji:
STRUKTURA KWASÓW NUKLEJOWYCH

Ryż. 4 . Bazy azotowe: adenina, guanina, cytozyna, tymina
Kwas dezoksyrybonukleinowy(DNA) odnosi się do kwasów nukleinowych. Kwasy nukleinowe to klasa nieregularnych biopolimerów, których monomerami są nukleotydy.
NUKLEOTYDY składać się z zasada azotowa w połączeniu z pięciowęglowym węglowodanem (pentozą) - dezoksyryboza(w przypadku DNA) lub ryboza(w przypadku RNA), który łączy się z resztą kwasu fosforowego (H 2 PO 3 -).
Zasady azotowe istnieją dwa rodzaje: zasady pirymidynowe – uracyl (tylko w RNA), cytozyna i tymina, zasady purynowe – adenina i guanina.

Ryż. 5. Struktura nukleotydów (po lewej), lokalizacja nukleotydu w DNA (na dole) i rodzaje zasad azotowych (po prawej): pirymidyna i puryna

Atomy węgla w cząsteczce pentozy są ponumerowane od 1 do 5. Fosforan łączy się z trzecim i piątym atomem węgla. W ten sposób nukleotydy łączą się, tworząc łańcuch kwasu nukleinowego. W ten sposób możemy wyizolować końce 3 'i 5' nici DNA:

Ryż. 6. Izolacja końców 3 'i 5' nici DNA
Tworzą się dwie nici DNA podwójna helisa... Te łańcuchy w spirali są zorientowane w przeciwnych kierunkach. W różnych niciach DNA zasady azotowe są połączone wiązania wodorowe... Adenina zawsze łączy się z tyminą, a cytozyna z guaniną. Nazywa się to zasada komplementarności(cm. zasada komplementarności).
Zasada komplementarności:
| A-T G-C |
Na przykład, jeśli otrzymamy nić DNA z sekwencją
3'- ATTGTCCTAGCTGCTCG - 5',
wtedy drugi łańcuch będzie do niego komplementarny i skierowany w przeciwnym kierunku - od końca 5' do końca 3':
5'-TACAGGATCGACGAGC-3'.

Ryż. 7. Kierunek łańcuchów cząsteczki DNA i połączenie zasad azotowych za pomocą wiązań wodorowych
REPLIKACJA DNA
replikacja DNA to proces podwojenia cząsteczki DNA za pomocą syntezy matrycy. W większości przypadków naturalnej replikacji DNAElementarzdo syntezy DNA jest krótki fragment (odtworzony). Taki starter rybonukleotydowy jest tworzony przez enzym primazę (primaza DNA u prokariontów, polimeraza DNA u eukariontów), a następnie jest zastępowany przez polimerazę deoksyrybonukleotydową, która normalnie pełni funkcje naprawcze (koryguje uszkodzenia chemiczne i pęknięcia w cząsteczce DNA).
Replikacja odbywa się w mechanizmie semikonserwatywnym. Oznacza to, że podwójna helisa DNA rozwija się i na każdej z jej nici zostaje uzupełniona nowa nić zgodnie z zasadą komplementarności. Potomna cząsteczka DNA zawiera zatem jeden łańcuch z cząsteczki rodzicielskiej i jeden nowo zsyntetyzowany. Replikacja zachodzi w kierunku od końca 3 'do 5' łańcucha rodzicielskiego.

Ryż. 8. Replikacja (podwojenie) cząsteczki DNA
Synteza DNA- to nie jest tak skomplikowany proces, jak mogłoby się wydawać na pierwszy rzut oka. Jeśli się nad tym zastanowisz, najpierw musisz dowiedzieć się, czym jest synteza. To proces łączenia czegoś w całość. Tworzenie nowej cząsteczki DNA odbywa się w kilku etapach:
1) Topoizomeraza DNA, znajdująca się przed widelcem replikacyjnym, tnie DNA w celu ułatwienia jego rozwijania i rozwijania.
2) Helikaza DNA, po topoizomerazie, wpływa na proces „rozkręcania” helisy DNA.
3) Białka wiążące DNA wykonują wiązanie nici DNA, a także przeprowadzają ich stabilizację, zapobiegając ich sklejaniu się.
4) Polimeraza DNA δ(delta) , skoordynowany z prędkością ruchu widełek replikacyjnych, dokonuje syntezyprowadzącywięzy pomocniczy DNA w kierunku 5 „→ 3” na szablonie macierzyński Nić DNA w kierunku od końca 3" do końca 5" (prędkość do 100 par zasad na sekundę). Te wydarzenia na tym macierzyński Nici DNA są ograniczone.

Ryż. 9. Schematyczne przedstawienie procesu replikacji DNA: (1) Nić opóźniona (nić opóźniona), (2) Nić wiodąca (nić wiodąca), (3) Polimeraza DNA α (Polα), (4) Ligaza DNA, (5) RNA -starter, (6) Primase, (7) Fragment Okazaki, (8) Polimeraza DNA δ (Polδ), (9) Helikaza, (10) Jednoniciowe białka wiążące DNA, (11) Topoizomeraza.
Poniżej opisano syntezę opóźnionej nici DNA potomnego (zob. Schemat widelec replikacyjny i funkcja enzymu replikacyjnego)
Aby uzyskać bardziej wizualne wyjaśnienie replikacji DNA, zobacz
5) Natychmiast po rozwinięciu i ustabilizowaniu kolejnej nici cząsteczki macierzystej,Polimeraza DNA α(alfa)aw kierunku 5 „→3” syntetyzuje starter (starter RNA) – sekwencję RNA na matrycy DNA o długości od 10 do 200 nukleotydów. Następnie enzymjest usuwany z nici DNA.
Zamiast polimeraza DNAα
przyczepia się do 3" końca podkładu polimeraza DNAε
.
6)
polimeraza DNAε
(epsilon) jakby dalej wydłużał podkład, ale jako podłoże osadzadeoksyrybonukleotydy(w ilości 150-200 nukleotydów). W rezultacie z dwóch części powstaje solidna nić -RNA(tj. podkład) i DNA.
Polimeraza DNA εdziała do czasu, aż spotka się z poprzednim podkłademfragment Okazaki(zsyntetyzowany nieco wcześniej). Enzym ten jest następnie usuwany z łańcucha.
7) polimeraza DNA β(beta) zamiast tego wstajepolimeraza DNA ε,porusza się w tym samym kierunku (5 „→ 3”) i usuwa startery rybonukleotydowe, jednocześnie wstawiając w ich miejsce deoksyrybonukleotydy. Enzym działa aż do całkowitego usunięcia podkładu tj. aż do dezoksyrybonukleotydu (jeszcze wcześniej zsyntetyzowanegoPolimeraza DNA ε). Enzym nie jest w stanie połączyć wyniku swojej pracy z DNA znajdującym się przed nim, więc opuszcza łańcuch.
W efekcie fragment potomnego DNA „leży” na matrycy nici macierzystej. Nazywa się tofragment Okazaki.
8) szwy ligazy DNA dwa sąsiednie fragmenty Okazaki , tj. 5 "-koniec zsyntetyzowanego segmentupolimeraza DNA ε,i 3"-koniec obwodu, wbudowanypolimeraza DNAβ .
STRUKTURA RNA
Kwas rybonukleinowy(RNA) jest jedną z trzech głównych makrocząsteczek (pozostałe dwie to DNA i białka), które znajdują się w komórkach wszystkich żywych organizmów.
Podobnie jak DNA, RNA składa się z długiego łańcucha, w którym nazwane jest każde ogniwo nukleotyd... Każdy nukleotyd składa się z zasady azotowej, cukru rybozy i grupy fosforanowej. Jednak w przeciwieństwie do DNA, RNA zwykle nie ma dwóch nici, ale jedną. Pentoza w RNA jest reprezentowana przez rybozę, a nie dezoksyrybozę (ryboza ma dodatkową grupę hydroksylową na drugim atomie węglowodanu). Wreszcie DNA różni się od RNA składem zasad azotowych: zamiast tyminy ( T) uracyl ( U) który jest również komplementarny do adeniny.
Sekwencja nukleotydów umożliwia RNA kodowanie informacji genetycznej. Wszystkie organizmy komórkowe wykorzystują RNA (mRNA) do programowania syntezy białek.
Komórkowe RNA są wytwarzane w procesie zwanym transkrypcja czyli synteza RNA na matrycy DNA, realizowana przez specjalne enzymy - polimerazy RNA.
Następnie informacyjne RNA (mRNA) biorą udział w procesie zwanym audycja, tych. synteza białek na macierzy mRNA z udziałem rybosomów. Pozostałe RNA po transkrypcji przechodzą modyfikacje chemiczne, a po utworzeniu struktur drugorzędowych i trzeciorzędowych pełnią funkcje zależne od rodzaju RNA.

Ryż. 10. Różnica między DNA a RNA na bazie azotowej: zamiast tyminy (T) RNA zawiera uracyl (U), który jest również komplementarny do adeniny.
TRANSKRYPCJA
Jest to proces syntezy RNA na matrycy DNA. DNA rozwija się w jednym z miejsc. Jedna z nici zawiera informacje, które należy skopiować na cząsteczkę RNA – ta nić nazywana jest nicią kodującą. Druga nić DNA, komplementarna do kodującej, nazywana jest matrycą. W procesie transkrypcji na nici matrycowej w kierunku 3'-5' (wzdłuż nici DNA) syntetyzowana jest komplementarna nić RNA. W ten sposób powstaje kopia RNA kodującej nici.
![]()
Ryż. 11. Schematyczne przedstawienie transkrypcji
Na przykład, jeśli otrzymamy sekwencję nici kodującej
3'- ATTGTCCTAGCTGCTCG - 5',
wtedy, zgodnie z zasadą komplementarności, łańcuch macierzowy będzie niósł ciąg
5'- TACAGGATCGACGAGC- 3',
a zsyntetyzowany z niego RNA to sekwencja
Audycja
Rozważ mechanizm synteza białek na matrycy RNA, a także na kodzie genetycznym i jego właściwościach. Ponadto, dla jasności, korzystając z poniższego linku, zalecamy obejrzenie krótkiego filmu o procesach transkrypcji i tłumaczenia zachodzących w żywej komórce:

Ryż. 12. Proces syntezy białek: DNA koduje RNA, RNA koduje białko
KOD GENETYCZNY
Kod genetyczny- sposób kodowania sekwencji aminokwasowej białek przy użyciu sekwencji nukleotydowej. Każdy aminokwas jest kodowany przez sekwencję trzech nukleotydów - kodon lub triplet.
Kod genetyczny wspólny dla większości pro- i eukariontów. W tabeli wymieniono wszystkie 64 kodony i wskazano odpowiadające im aminokwasy. Kolejność zasad jest od końca 5 „do 3” mRNA.
Tabela 1. Standardowy kod genetyczny
|
1st nie |
2. baza |
3rd nie |
|||||||
|
U |
C |
A |
g |
||||||
|
U |
U U U |
(Ph / F) |
U C U |
(Ser/S) |
U A U |
(Tyr / Y) |
U G U |
(Cys / C) |
U |
|
U U C |
UC C |
U A C |
UG C |
C |
|||||
|
U U A |
(Leu / L) |
UC A |
U A A |
Kodon stop ** |
U G A |
Kodon stop ** |
A |
||
|
U U G |
UC G |
U A G |
Kodon stop ** |
U G G |
(Trp/W) |
g |
|||
|
C |
C U U |
C C U |
(Pro / P) |
C A U |
(Jego / H) |
C G U |
(Arg / R) |
U |
|
|
C U C |
C C C |
C A C |
C G C |
C |
|||||
|
C U A |
C C A |
C A A |
(Gln / Q) |
C GA |
A |
||||
|
C U G |
C C G |
C A G |
C G G |
g |
|||||
|
A |
A U U |
(Ile / I) |
A C U |
(Tr / T) |
A A U |
(Asn / N) |
A G U |
(Ser/S) |
U |
|
A U C |
A C C |
A A C |
A G C |
C |
|||||
|
A U A |
A C A |
A A A |
(Lys / K) |
A G A |
A |
||||
|
A U G |
(Spotkane / M) |
A C G |
A A G |
A G G |
g |
||||
|
g |
G U U |
(Val / V) |
G C U |
(Ala / A) |
GA U |
(Bolenie / D) |
GG |
(Gly / G) |
U |
|
GU C |
GC C |
GA C |
G G C |
C |
|||||
|
GU A |
GC A |
G A A |
(Glu/E) |
GG A |
A |
||||
|
G U G |
G C G |
G A G |
G G G |
g |
|||||
Wśród trójek znajdują się 4 specjalne sekwencje, które pełnią funkcję „znaków interpunkcyjnych”:
- *Tryplet SIE, również kodujący metioninę, nazywa się kodon startowy... Synteza cząsteczki białka zaczyna się od tego kodonu. Tak więc podczas syntezy białka pierwszym aminokwasem w sekwencji będzie zawsze metionina.
- ** Trojaczki UAA, UAG oraz UGA są nazywane kodony stop i nie kodują pojedynczego aminokwasu. W tych sekwencjach synteza białek zatrzymuje się.
Właściwości kodu genetycznego
1. Trójka... Każdy aminokwas jest kodowany przez sekwencję trzech nukleotydów – trójkę lub kodon.
2. Ciągłość... Pomiędzy trójkami nie ma dodatkowych nukleotydów, informacje są odczytywane w sposób ciągły.
3. Bez nakładania... Jeden nukleotyd nie może wejść jednocześnie w dwie trójki.
4. Jednoznaczność... Jeden kodon może kodować tylko jeden aminokwas.

5. Degeneracja... Jeden aminokwas może być kodowany przez kilka różnych kodonów.

6. Wszechstronność... Kod genetyczny jest taki sam dla wszystkich żywych organizmów.
Przykład. Podano nam sekwencję łańcucha kodowania:
3’- CCGATTGCACGTCGATCGTATA- 5’.
Łańcuch macierzy będzie miał sekwencję:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
Teraz „syntetyzujemy” informacyjne RNA z tego łańcucha:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
Synteza białka przebiega w kierunku 5 '→ 3', dlatego musimy odwrócić sekwencję, aby "odczytać" kod genetyczny:
5’- AUAUGCUAGCUGCACGUUAGCC- 3’.
Teraz znajdźmy kodon startowy AUG:
5’- AU AUG CUAGCUGCACGUUAGCC- 3’.
Podzielmy sekwencję na trojaczki:
brzmi tak: informacja z DNA jest przenoszona na RNA (transkrypcja), z RNA - na białko (translacja). DNA może być również zduplikowane przez replikację, a proces odwrotnej transkrypcji jest również możliwy, gdy DNA jest syntetyzowany z matrycy RNA, ale proces ten jest głównie typowy dla wirusów.

Ryż. 13. Centralny dogmat Biologia molekularna
GENOM: GENY i CHROMOSOMY
(Pojęcia ogólne)
Genom - całość wszystkich genów organizmu; jego kompletny zestaw chromosomów.
Termin „genom” został zaproponowany przez G. Winklera w 1920 roku, aby opisać zestaw genów zawartych w haploidalnym zestawie chromosomów organizmów jednego gatunku biologicznego. Pierwotne znaczenie tego terminu wskazywało, że pojęcie genomu, w przeciwieństwie do genotypu, jest cechą genetyczną gatunku jako całości, a nie pojedynczego osobnika. Wraz z rozwojem genetyki molekularnej zmieniło się znaczenie tego terminu. Wiadomo, że DNA, który jest nośnikiem informacji genetycznej w większości organizmów, a zatem stanowi podstawę genomu, obejmuje nie tylko geny we współczesnym tego słowa znaczeniu. Większość DNA komórek eukariotycznych jest reprezentowane przez niekodujące („nadmiarowe”) sekwencje nukleotydowe, które nie zawierają informacji o białkach i kwasach nukleinowych. Tak więc główną częścią genomu dowolnego organizmu jest całe DNA jego haploidalnego zestawu chromosomów.
Geny to sekcje cząsteczek DNA, które kodują polipeptydy i cząsteczki RNA
W ciągu ostatniego stulecia nasze rozumienie genów znacznie się zmieniło. Wcześniej genom nazywano fragmentem chromosomu, który koduje lub determinuje jedną cechę lub fenotypowy właściwość (widoczną), taką jak kolor oczu.
W 1940 roku George Beadle i Edward Tatem zaproponowali molekularną definicję genu. Naukowcy leczyli zarodniki grzybów Neurospora crassa Promienie rentgenowskie i inne czynniki powodujące zmiany w sekwencji DNA ( mutacje) i znaleźli zmutowane szczepy grzyba, które utraciły pewne specyficzne enzymy, co w niektórych przypadkach doprowadziło do zakłócenia całego szlaku metabolicznego. Beadle i Tatem doszli do wniosku, że gen to fragment materiału genetycznego, który definiuje lub koduje pojedynczy enzym. Tak powstała hipoteza "Jeden gen - jeden enzym"... Ta koncepcja została później rozszerzona, aby zdefiniować „Jeden gen – jeden polipeptyd”, ponieważ wiele genów koduje białka, które nie są enzymami, a polipeptyd może być podjednostką złożonego kompleksu białkowego.
Na ryc. 14 to diagram przedstawiający, w jaki sposób trojaczki nukleotydów w DNA określają polipeptyd, sekwencję aminokwasową białka, w której pośredniczy mRNA. Jedna z nici DNA pełni rolę matrycy do syntezy mRNA, którego tryplety nukleotydowe (kodony) są komplementarne do trypletów DNA. U niektórych bakterii i wielu eukariontów sekwencje kodujące są przerywane regionami niekodującymi (tzw. introny).
Nowoczesna definicja genów biochemicznych jeszcze bardziej konkretnie. Geny to wszystkie odcinki DNA, które kodują pierwotną sekwencję produktów końcowych, w tym polipeptydy lub RNA o funkcji strukturalnej lub katalitycznej.
Oprócz genów DNA zawiera również inne sekwencje, które pełnią wyłącznie funkcję regulacyjną. Sekwencje regulacyjne może oznaczać początek lub koniec genów, wpływać na transkrypcję lub wskazywać miejsce inicjacji replikacji lub rekombinacji. Niektóre geny mogą ulegać ekspresji na różne sposoby, przy czym ten sam fragment DNA służy jako matryca do tworzenia różnych produktów.
Możemy z grubsza obliczyć minimalny rozmiar genu kodowanie średniego białka. Każdy aminokwas w łańcuchu polipeptydowym jest kodowany jako sekwencja trzech nukleotydów; sekwencje tych trypletów (kodonów) odpowiadają łańcuchowi aminokwasowemu w polipeptydzie kodowanym przez dany gen. Łańcuch polipeptydowy o długości 350 reszt aminokwasowych (łańcuch średni) odpowiada sekwencji o długości 1050 pz. ( pary zasad). Jednak wiele genów eukariotycznych i niektóre geny prokariotyczne są przerwane przez segmenty DNA, które nie są nośniki informacji o białku i dlatego okazuje się, że jest znacznie dłuższa niż pokazuje proste obliczenie.
Ile genów znajduje się na jednym chromosomie?
 Ryż. 15. Widok chromosomów w komórkach prokariotycznych (po lewej) i eukariotycznych. Histony to szeroka klasa białek jądrowych, które pełnią dwie główne funkcje: biorą udział w pakowaniu nici DNA w jądrze oraz w epigenetycznej regulacji procesów jądrowych, takich jak transkrypcja, replikacja i naprawa.
Ryż. 15. Widok chromosomów w komórkach prokariotycznych (po lewej) i eukariotycznych. Histony to szeroka klasa białek jądrowych, które pełnią dwie główne funkcje: biorą udział w pakowaniu nici DNA w jądrze oraz w epigenetycznej regulacji procesów jądrowych, takich jak transkrypcja, replikacja i naprawa.
DNA prokariontów jest prostsze: ich komórki nie mają jądra, dlatego DNA znajduje się bezpośrednio w cytoplazmie w postaci nukleoidu.
 Jak wiadomo, komórki bakteryjne mają chromosom w postaci nici DNA, upakowanej w zwartą strukturę - nukleoid. Chromosom prokariota Escherichia coli, którego genom został całkowicie odszyfrowany, jest kołową cząsteczką DNA (w rzeczywistości nie jest) poprawny krąg, a raczej pętla bez początku i końca), składająca się z 4 639 675 pz. Ta sekwencja zawiera około 4300 genów dla białek i 157 genów dla stabilnych cząsteczek RNA. V ludzki genom około 3,1 miliarda par zasad, co odpowiada prawie 29 000 genom zlokalizowanym na 24 różnych chromosomach.
Jak wiadomo, komórki bakteryjne mają chromosom w postaci nici DNA, upakowanej w zwartą strukturę - nukleoid. Chromosom prokariota Escherichia coli, którego genom został całkowicie odszyfrowany, jest kołową cząsteczką DNA (w rzeczywistości nie jest) poprawny krąg, a raczej pętla bez początku i końca), składająca się z 4 639 675 pz. Ta sekwencja zawiera około 4300 genów dla białek i 157 genów dla stabilnych cząsteczek RNA. V ludzki genom około 3,1 miliarda par zasad, co odpowiada prawie 29 000 genom zlokalizowanym na 24 różnych chromosomach.
Prokarionty (bakterie).
 Bakteria E coli ma jedną dwuniciową okrągłą cząsteczkę DNA. Składa się z 4 639 675 pz. i osiąga długość około 1,7 mm, co przekracza długość samej komórki E coli około 850 razy. Oprócz dużego okrągłego chromosomu w nukleoidzie wiele bakterii zawiera jedną lub więcej małych okrągłych cząsteczek DNA, które są swobodnie zlokalizowane w cytozolu. Takie elementy pozachromosomalne nazywane są plazmidy(rys. 16).
Bakteria E coli ma jedną dwuniciową okrągłą cząsteczkę DNA. Składa się z 4 639 675 pz. i osiąga długość około 1,7 mm, co przekracza długość samej komórki E coli około 850 razy. Oprócz dużego okrągłego chromosomu w nukleoidzie wiele bakterii zawiera jedną lub więcej małych okrągłych cząsteczek DNA, które są swobodnie zlokalizowane w cytozolu. Takie elementy pozachromosomalne nazywane są plazmidy(rys. 16).
Większość plazmidów składa się tylko z kilku tysięcy par zasad, niektóre zawierają więcej niż 10 000 pz. Przenoszą informację genetyczną i replikują się, tworząc plazmidy potomne, które wnikają do komórek potomnych podczas podziału komórki rodzicielskiej. Plazmidy znajdują się nie tylko w bakteriach, ale także w drożdżach i innych grzybach. W wielu przypadkach plazmidy nie zapewniają żadnej przewagi komórkom gospodarza, a ich jedynym zadaniem jest samodzielna reprodukcja. Jednak niektóre plazmidy niosą geny przydatne dla gospodarza. Na przykład geny zawarte w plazmidach mogą nadawać komórkom bakteryjnym odporność na środki przeciwbakteryjne. Plazmidy niosące gen β-laktamazy nadają oporność na antybiotyki β-laktamowe, takie jak penicylina i amoksycylina. Plazmidy mogą być przenoszone z komórek opornych na antybiotyki do innych komórek tego samego lub innego gatunku bakterii, czyniąc te komórki również opornymi. Intensywne stosowanie antybiotyków jest silnym czynnikiem selekcyjnym przyczyniającym się do rozprzestrzeniania się plazmidów kodujących antybiotykooporność (a także transpozonów kodujących podobne geny) wśród bakterii chorobotwórczych i prowadzi do powstania szczepów bakteryjnych wykazujących oporność na kilka antybiotyków. Lekarze zaczynają rozumieć niebezpieczeństwa powszechnego stosowania antybiotyków i przepisują je tylko wtedy, gdy jest to pilnie potrzebne. Z podobnych powodów powszechne stosowanie antybiotyków w leczeniu zwierząt gospodarskich jest ograniczone.
Zobacz też: Ravin N.V., Shestakov S.V. Genom prokariontów // Vavilov Journal of Genetics and Selection, 2013. V. 17. No. 4/2. S. 972-984.
Eukarionty.
Tabela 2. DNA, geny i chromosomy niektórych organizmów
|
wspólne DNA, p.n. |
Numer chromosomu * |
Przybliżona liczba genów |
|
|
Escherichia coli(bakteria) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(drożdże) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans(nicienie) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana(Zakład) |
119 186 200 |
33 000 |
|
|
muszka owocowa(muszka owocowa) |
120 367 260 |
20 000 |
|
|
Oryza sativa(Ryż) |
480 000 000 |
57 000 |
|
|
Mus musculus(mysz) |
2 634 266 500 |
27 000 |
|
|
Homo sapiens(Człowiek) |
3 070 128 600 |
29 000 |
Notatka. Informacje są stale aktualizowane; więcej aktualnych informacji można znaleźć na stronach poświęconych poszczególnym projektom genomicznym
* Dla wszystkich eukariontów, z wyjątkiem drożdży, podano diploidalny zestaw chromosomów. Diploidalny zestaw chromosomy (z greckiego diploos- podwójne i eidos- gatunki) - podwójny zestaw chromosomów(2n), z których każdy ma jeden homologiczny.
** Zestaw haploidalny. Szczepy dzikich drożdży mają zwykle osiem (oktaploidalnych) lub więcej zestawów takich chromosomów.
***Dla kobiet z dwoma chromosomami X. Samce mają chromosom X, ale nie mają Y, to znaczy jest tylko 11 chromosomów.
Komórka drożdży, jeden z najmniejszych eukariontów, ma 2,6 razy więcej DNA niż komórka E coli(Tabela 2). Komórki muszki owocowej Drosophila, klasyczny obiekt badań genetycznych, zawiera 35 razy więcej DNA, a komórki ludzkie - około 700 razy więcej DNA niż komórki E coli. Wiele roślin i płazów zawiera jeszcze więcej DNA. Materiał genetyczny komórek eukariotycznych jest zorganizowany w postaci chromosomów. Diploidalny zestaw chromosomów (2 n) zależy od rodzaju organizmu (tab. 2).
Na przykład w ludzkiej komórce somatycznej znajduje się 46 chromosomów ( Ryż. 17). Każdy chromosom komórki eukariotycznej, jak pokazano na ryc. 17, a, zawiera jedną bardzo dużą dwuniciową cząsteczkę DNA. Dwadzieścia cztery ludzkie chromosomy (22 sparowane chromosomy i dwa chromosomy płci X i Y) różnią się długością ponad 25 razy. Każdy chromosom eukariotyczny zawiera określony zestaw genów.

Ryż. 17. Chromosomy eukariotyczne.a- para połączonych i skondensowanych chromatyd siostrzanych z ludzkiego chromosomu. W tej formie chromosomy eukariotyczne pozostają po replikacji iw metafazie podczas mitozy. b- kompletny zestaw chromosomów z leukocytu jednego z autorów książki. Każda normalna ludzka komórka somatyczna zawiera 46 chromosomów.

Wielkość i funkcja DNA jako matrycy do przechowywania i przenoszenia materiału dziedzicznego wyjaśnia obecność specjalnych elementów strukturalnych w organizacji tej cząsteczki. W organizmach wyższych DNA jest rozłożone między chromosomami.
Zbiór DNA (chromosomów) organizmu nazywa się genomem. Chromosomy znajdują się w jądrze komórkowym i tworzą strukturę zwaną chromatyną. Chromatyna to kompleks DNA i białek zasadowych (histonów) w stosunku 1:1. Długość DNA jest zwykle mierzona liczbą komplementarnych par nukleotydów (pz). Na przykład trzeci chromosom jest ludzkiCentury to cząsteczka DNA o wielkości 160 milionów pz Wyizolowany linearyzowany DNA o wielkości 3*106 pz. ma długość około 1 mm, zatem linearyzowana cząsteczka 3. chromosomu ludzkiego miałaby długość 5 mm, a DNA wszystkich 23 chromosomów (~3*109 pz, MR=1,8*1012) haploidu komórka - komórka jajowa lub plemnik - w postaci linearyzowanej miałaby 1 m. Z wyjątkiem komórek zarodkowych, wszystkie komórki ludzkiego ciała (jest ich około 1013) zawierają podwójny zestaw chromosomów. Podczas podziału komórki wszystkie 46 cząsteczek DNA ulega replikacji i reorganizacji w 46 chromosomów.
Jeśli połączysz cząsteczki DNA ludzkiego genomu (22 chromosomy i chromosomy X i Y lub X i X), otrzymasz sekwencję o długości około jednego metra. Uwaga: Wszystkie ssaki i inne organizmy o heterogametycznej płci męskiej, samice mają dwa chromosomy X (XX), a samce jeden chromosom X i jeden chromosom Y (XY).
Większość komórek ludzkich, dlatego całkowita długość DNA takich komórek wynosi około 2m. Dorosły osobnik ma około 10 14 komórek, więc całkowita długość wszystkich cząsteczek DNA wynosi 2 ・ 10 11 km. Dla porównania obwód Ziemi wynosi 4 ・ 10 4 km, a odległość od Ziemi do Słońca to 1,5 ・ 10 8 km. Oto jak zaskakująco upakowane jest DNA w naszych komórkach!
W komórkach eukariotycznych znajdują się inne organelle zawierające DNA - mitochondria i chloroplasty. Postawiono wiele hipotez dotyczących pochodzenia mitochondrialnego i chloroplastowego DNA. Powszechnie przyjętym dziś punktem widzenia jest to, że są one zaczątkami chromosomów pradawnych bakterii, które weszły do cytoplazmy komórek gospodarza i stały się prekursorami tych organelli. Mitochondrialny DNA koduje mitochondrialne tRNA i rRNA, a także kilka białek mitochondrialnych. Ponad 95% białek mitochondrialnych jest kodowanych przez jądrowy DNA.
STRUKTURA GENÓW
Rozważ strukturę genu u prokariontów i eukariontów, ich podobieństwa i różnice. Pomimo tego, że gen jest fragmentem DNA, który koduje tylko jedno białko lub RNA, oprócz części bezpośrednio kodującej zawiera również elementy regulacyjne i inne elementy strukturalne, które mają inną strukturę u prokariontów i eukariontów.
Sekwencja kodowania- główna jednostka strukturalna i funkcjonalna genu, to w niej kodujące tryplety nukleotydówsekwencja aminokwasowa. Rozpoczyna się kodonem start i kończy kodonem stop.
Przed i po sekwencji kodującej są nieprzetłumaczone sekwencje 5' i 3'... Pełnią funkcje regulacyjne i pomocnicze, m.in. zapewniają lądowanie rybosomu na m-RNA.
Sekwencje nieulegające translacji i kodujące stanowią jednostkę transkrypcyjną - transkrybowany odcinek DNA, czyli odcinek DNA, z którego syntetyzowany jest m-RNA.
Terminator- niepodlegający transkrypcji region DNA na końcu genu, w którym zatrzymuje się synteza RNA.
Na początku gen jest obszar regulacyjnyłącznie z promotor oraz operator.
Promotor- sekwencja, z którą wiąże się polimeraza podczas inicjacji transkrypcji. Operator to region, z którym mogą wiązać się specjalne białka - represorów, który może zmniejszać aktywność syntezy RNA z tego genu – innymi słowy zmniejszać ją wyrażenie.
Struktura genów u prokariontów
Ogólna struktura genów u prokariontów i eukariontów nie różni się – oba zawierają region regulatorowy z promotorem i operatorem, jednostkę transkrypcyjną z sekwencjami kodującymi i nieulegającymi translacji oraz terminator. Jednak organizacja genów u prokariontów i eukariontów jest inna.

Ryż. 18. Schemat budowy genu u prokariontów (bakterii) -obraz jest powiększony
Na początku i na końcu operonu istnieją wspólne regiony regulatorowe dla kilku genów strukturalnych. Jedna cząsteczka mRNA jest odczytywana z transkrybowanego regionu operonu, który zawiera kilka sekwencji kodujących, z których każda ma swój własny kodon start i stop. Z każdej z tych stron zjedno białko jest przerwane. W ten sposób, kilka cząsteczek białka jest syntetyzowanych z jednej cząsteczki i-RNA.
Dla prokariontów charakterystyczne jest łączenie kilku genów w jedną jednostkę funkcjonalną - operon... Pracę operonu mogą regulować inne geny, które mogą być zauważalnie odległe od samego operonu - regulatory... Białko przetłumaczone z tego genu nazywa się represor... Wiąże się z operatorem operonu, regulując ekspresję wszystkich zawartych w nim genów jednocześnie.
Zjawisko to jest również charakterystyczne dla prokariontów parowanie transkrypcji i tłumaczenia.
![]()
Ryż. 19 Zjawisko koniugacji transkrypcji i translacji u prokariontów – obraz jest powiększony
Taka koniugacja nie występuje u eukariontów ze względu na obecność otoczki jądrowej, która oddziela cytoplazmę, w której zachodzi translacja, od materiału genetycznego, na którym zachodzi transkrypcja. U prokariotów, podczas syntezy RNA na matrycy DNA, rybosom może natychmiast wiązać się z syntetyzowaną cząsteczką RNA. W ten sposób tłumaczenie rozpoczyna się jeszcze przed zakończeniem transkrypcji. Co więcej, kilka rybosomów może jednocześnie wiązać się z jedną cząsteczką RNA, syntetyzując jednocześnie kilka cząsteczek jednego białka.
Struktura genów u eukariontów
Geny i chromosomy eukariontów są bardzo złożone
Wiele gatunków bakterii ma tylko jeden chromosom i prawie we wszystkich przypadkach na każdym chromosomie znajduje się jedna kopia każdego genu. Tylko kilka genów, takich jak geny rRNA, jest zawartych w wielu kopiach. Geny i sekwencje regulatorowe tworzą praktycznie cały genom prokariontów. Co więcej, prawie każdy gen ściśle odpowiada sekwencji aminokwasowej (lub sekwencji RNA), którą koduje (ryc. 14).
Strukturalna i funkcjonalna organizacja genów eukariotycznych jest znacznie bardziej złożona. Badanie chromosomów eukariotycznych, a później sekwencjonowanie kompletnych sekwencji genomów eukariotycznych, przyniosło wiele niespodzianek. Wiele, jeśli nie większość, genów eukariotycznych ma interesującą cechę: ich sekwencje nukleotydowe zawierają jeden lub więcej regionów DNA, które nie kodują sekwencji aminokwasowej produktu polipeptydowego. Takie niepodlegające translacji insercje łamią bezpośrednią zgodność między sekwencją nukleotydową genu a sekwencją aminokwasową kodowanego polipeptydu. Te nieprzetłumaczone segmenty genów nazywają się introny, lub osadzony sekwencje a segmenty kodujące to egzony... U prokariontów tylko kilka genów zawiera introny.
Tak więc u eukariotów praktycznie nie ma kombinacji genów w operony, a sekwencja kodująca genu eukariotycznego jest najczęściej podzielona na regiony podlegające translacji - egzony i nieprzetłumaczone sekcje - introny.
W większości przypadków funkcja intronów nie została ustalona. Ogólnie tylko około 1,5% ludzkiego DNA „koduje”, to znaczy zawiera informacje o białkach lub RNA. Jednak biorąc pod uwagę duże introny, okazuje się, że 30% ludzkiego DNA składa się z genów. Ponieważ geny stanowią stosunkowo niewielką część ludzkiego genomu, znaczna część DNA pozostaje niewyjaśniona.

Ryż. 16. Schemat struktury genu u eukariontów - obraz jest powiększony
Z każdego genu najpierw syntetyzuje się niedojrzały lub pre-RNA, który zawiera zarówno introny, jak i eksony.
Następnie następuje proces splicingu, w wyniku którego wycina się regiony intronu i powstaje dojrzały mRNA, z którego można zsyntetyzować białko.

Ryż. 20. Proces alternatywnego splicingu - obraz jest powiększony
Taka organizacja genów umożliwia np. uświadomienie sobie, kiedy z jednego genu można zsyntetyzować różne formy białka, ze względu na to, że podczas splicingu można zszyć eksony w różne sekwencje.

Ryż. 21. Różnice w budowie genów prokariontów i eukariontów - obraz jest powiększony
MUTACJA I MUTAGENEZ
Mutacja nazywana trwałą zmianą genotypu, czyli zmianą sekwencji nukleotydów.
Proces prowadzący do powstania mutacji nazywa się mutageneza, a organizm, Wszystko których komórki niosą tę samą mutację - mutant.
Teoria mutacji został po raz pierwszy sformułowany przez Hugo de Vriesa w 1903 roku. Jego nowoczesna wersja zawiera następujące postanowienia:
1. Mutacje pojawiają się nagle, skokowo.
2. Mutacje przekazywane są z pokolenia na pokolenie.
3. Mutacje mogą być korzystne, szkodliwe lub neutralne, dominujące lub recesywne.
4. Prawdopodobieństwo wykrycia mutacji zależy od liczby przebadanych osobników.
5. Podobne mutacje mogą występować wielokrotnie.
6. Mutacje nie są ukierunkowane.
Mutacje mogą wystąpić z powodu różnych czynników. Rozróżnij mutacje, które powstały pod wpływem mutagenny wpływy: fizyczne (na przykład ultrafiolet lub promieniowanie), chemiczne (na przykład kolchicyna lub reaktywne formy tlenu) i biologiczne (na przykład wirusy). Również mutacje mogą być spowodowane przez błędy replikacji.
W zależności od warunków pojawienia się mutacje dzielą się na: spontaniczny- czyli mutacje, które powstały w normalnych warunkach, oraz wywołany- czyli mutacje, które powstały w specjalnych warunkach.
Mutacje mogą zachodzić nie tylko w DNA jądrowym, ale także np. w DNA mitochondriów czy plastydów. W związku z tym możemy odróżnić jądrowy oraz cytoplazmatyczny mutacje.
W wyniku mutacji często mogą pojawiać się nowe allele. Jeśli zmutowany allel hamuje działanie normalnego allelu, nazywa się mutację dominujący... Jeśli normalny allel tłumi zmutowany, taka mutacja nazywa się recesywny... Większość mutacji prowadzących do pojawienia się nowych alleli ma charakter recesywny.
Przez efekt rozróżnia się mutacje adaptacyjny prowadzące do zwiększenia adaptacji organizmu do środowiska, neutralny które nie wpływają na przeżycie, szkodliwy które zmniejszają zdolność przystosowania się organizmów do warunków środowiskowych i śmiertelny prowadzące do śmierci organizmu we wczesnych stadiach rozwoju.
W zależności od konsekwencji rozróżnia się mutacje, prowadzące do: utrata funkcji białka, mutacje prowadzące do pojawienie się białko ma nową funkcję, a także mutacje, które zmienić dawkę genu i odpowiednio dawkę zsyntetyzowanego z niego białka.
Mutacja może wystąpić w dowolnej komórce ciała. Jeśli w komórce zarodkowej pojawi się mutacja, nazywa się to zarodkowy(zarodkowy lub generatywny). Takie mutacje nie pojawiają się w organizmie, w którym się pojawiły, ale prowadzą do pojawienia się mutantów u potomstwa i są dziedziczone, dlatego są ważne dla genetyki i ewolucji. Jeśli mutacja wystąpi w jakiejkolwiek innej komórce, nazywa się to somatyczny... Taka mutacja może w takim czy innym stopniu objawiać się w organizmie, w którym powstała, na przykład prowadzić do powstania guzów nowotworowych. Jednak ta mutacja nie jest dziedziczona i nie wpływa na potomstwo.
Mutacje mogą wpływać na regiony genomu o różnej wielkości. Przeznaczyć gen, chromosomalny oraz genomowy mutacje.
Mutacje genów
Nazywa się mutacje, które występują w skali mniejszej niż jeden gen genetyczny, lub punkt (punkt)... Takie mutacje prowadzą do zmiany jednego lub więcej nukleotydów w sekwencji. Wśród mutacji genów sączęści zamienne prowadząca do zastąpienia jednego nukleotydu innym,skreślenia prowadzące do utraty jednego z nukleotydów,wstawki co prowadzi do dodania dodatkowego nukleotydu do sekwencji.

Ryż. 23. Mutacje genów (punktowe)
Zgodnie z mechanizmem działania na białko, mutacje genów dzielą się na:równoznaczny, które (w wyniku degeneracji kodu genetycznego) nie prowadzą do zmiany składu aminokwasowego produktu białkowego,mutacje zmiany sensu, które prowadzą do zamiany jednego aminokwasu na inny i mogą wpływać na strukturę syntetyzowanego białka, choć często okazują się nieistotne,nonsensowne mutacje prowadzące do zastąpienia kodonu kodującego kodonem stop,mutacje prowadzące do zaburzenie splicingu:

Ryż. 24. Schematy mutacji
Ponadto, zgodnie z mechanizmem działania na białko, mutacje są izolowane, co prowadzi do: przesunięcie ramki odczyty na przykład wstawienia i usunięcia. Takie mutacje, jak mutacje nonsensowne, chociaż występują w jednym punkcie genu, często wpływają na całą strukturę białka, co może prowadzić do całkowitej zmiany jego struktury. gdy odcinek chromosomu jest obrócony o 180 stopni, Ryż. 28. Translokacja
gdy odcinek chromosomu jest obrócony o 180 stopni, Ryż. 28. Translokacja
Ryż. 29. Chromosom przed i po duplikacji
Mutacje genomowe
Wreszcie, mutacje genomowe wpływają na cały genom jako całość, czyli liczbę zmian chromosomów. Przydziel poliploidię - wzrost ploidii komórkowej i aneuploidii, czyli zmianę liczby chromosomów, na przykład trisomię (obecność dodatkowego homologu w jednym z chromosomów) i monosomię (brak homologu w chromosom).
Filmy o DNA
REPLIKACJA DNA, KODOWANIE RNA, SYNTEZA BIAŁKA
(Jeśli wideo nie jest wyświetlane, jest dostępne przez
Zgodnie ze swoją budową chemiczną DNA ( Kwas dezoksyrybonukleinowy) jest biopolimer, których monomerami są nukleotydy... Oznacza to, że DNA jest polinukleotyd... Co więcej, cząsteczka DNA zwykle składa się z dwóch łańcuchów, skręconych względem siebie wzdłuż linii śrubowej (często nazywanej „skręconą spiralnie”) i połączonych wiązaniami wodorowymi.
Łańcuszki można skręcać zarówno w lewą, jak i prawą (najczęściej) stronę.
Niektóre wirusy mają pojedynczą nić DNA.
Każdy nukleotyd DNA składa się z 1) zasady azotowej, 2) dezoksyrybozy, 3) reszty kwasu fosforowego.
Podwójna prawoskrętna helisa DNA
DNA obejmuje następujące elementy: adenina, guanina, tymina oraz cytozyna... Adenina i guanina należą do purinam, oraz tymina i cytozyna - to pirymidyna... Czasami DNA zawiera uracyl, który jest zwykle charakterystyczny dla RNA, gdzie zastępuje tyminę.
Zasady azotowe jednego łańcucha cząsteczki DNA są połączone z zasadami azotowymi drugiego ściśle według zasady komplementarności: adenina tylko z tyminą (tworzą ze sobą dwa wiązania wodorowe), a guanina tylko z cytozyną (trzy wiązania) .
Zasada azotowa w samym nukleotydzie jest połączona z pierwszym atomem węgla formy cyklicznej dezoksyryboza czyli pentoza (węglowodan o pięciu atomach węgla). Wiązanie jest kowalencyjne, glikozydowe (C-N). W przeciwieństwie do rybozy, dezoksyryboza nie ma jednej z grup hydroksylowych. Pierścień dezoksyrybozy składa się z czterech atomów węgla i jednego atomu tlenu. Piąty atom węgla znajduje się poza pierścieniem i jest połączony poprzez atom tlenu z pozostałą częścią kwasu fosforowego. Ponadto, poprzez atom tlenu przy trzecim atomie węgla, przyłączona jest reszta kwasu fosforowego sąsiedniego nukleotydu.
Tak więc w jednej nici DNA sąsiednie nukleotydy są ze sobą połączone. wiązania kowalencyjne między dezoksyrybozą a kwasem fosforowym (wiązanie fosfodiestrowe). Powstaje szkielet fosforanowo-deoksyrybozowy. Prostopadle do niej, w kierunku drugiej nici DNA, skierowane są zasady azotowe, które są połączone z zasadami drugiego łańcucha wiązaniami wodorowymi.
Struktura DNA jest taka, że szkielety łańcuchów połączonych wiązaniami wodorowymi są skierowane w różnych kierunkach (mówią „wielokierunkowe”, „antyrównoległe”). Z boku, gdzie jeden kończy się kwasem fosforowym połączonym z piątym atomem węgla dezoksyrybozy, drugi kończy się „wolnym” trzecim atomem węgla. Oznacza to, że szkielet jednego łańcucha jest odwrócony do góry nogami w stosunku do drugiego. W ten sposób w strukturze nici DNA wyróżnia się 5 „końców” i 3 końce.
Podczas replikacji (podwajania) DNA synteza nowych nici zawsze przebiega od ich piątego końca do trzeciego, ponieważ nowe nukleotydy mogą przyłączać się tylko do wolnego trzeciego końca.
Ostatecznie (pośrednio przez RNA) każde trzy kolejne nukleotydy w łańcuchu DNA kodują jeden aminokwas białka.
Odkrycie struktury cząsteczki DNA nastąpiło w 1953 roku dzięki pracom F. Cricka i D. Watsona (ułatwiły to również wczesne prace innych naukowców). Chociaż jak Substancja chemiczna DNA było znane już w XIX wieku. W latach 40. XX wieku stało się jasne, że to DNA jest nośnikiem informacji genetycznej.
Podwójna helisa jest uważana za drugorzędową strukturę cząsteczki DNA. W komórkach eukariotycznych przytłaczająca ilość DNA znajduje się w chromosomach, gdzie wiąże się z białkami i innymi substancjami, a także ulega gęstszemu upakowaniu.
Kwas dezoksyrybonukleinowy lub DNA jest nośnikiem informacji genetycznej. Większość DNA w komórkach jest skoncentrowana w jądrze. Jest głównym składnikiem chromosomów. U eukariontów DNA znajduje się również w mitochondriach i plastydach. DNA składa się z mononukleotydów połączonych kowalencyjnie ze sobą, reprezentujących długi, nierozgałęziony polimer. Mononukleotydy tworzące DNA składają się z dezoksyrybozy, jednej z 4 zasad azotowych (adeniny, guaniny, cytozyny i tyminy) oraz reszty kwasu fosforowego. Liczba tych mononukleotydów jest bardzo duża. Na przykład w komórkach prokariotycznych zawierających jeden chromosom DNA jest jedną makrocząsteczką o masie cząsteczkowej większej niż 2 x 109.
Mononukleotydy jednej nici DNA są połączone ze sobą szeregowo ze względu na tworzenie kowalencyjne wiązania fosfodiestrowe między grupą OH dezoksyrybozy jednego mononukleotydu a resztą kwasu fosforowego innego. Po jednej stronie utworzonego szkieletu jednej nici DNA znajdują się zasady azotowe. Można je porównać do czterech różnych koralików noszonych na jednej nitce, ponieważ wydają się być nawleczone na łańcuch cukrowo-fosforanowy.
Powstaje pytanie, w jaki sposób ten długi łańcuch polinukleotydowy może kodować program rozwoju komórki, a nawet całego organizmu? Odpowiedź na to pytanie można uzyskać, rozumiejąc, w jaki sposób powstaje przestrzenna struktura DNA. Struktura tej cząsteczki została rozszyfrowana i opisana przez J. Watsona i F. Cricka w 1953 roku.
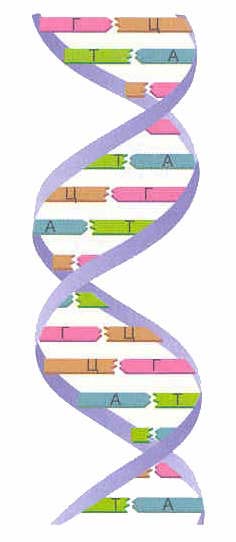
Cząsteczki DNA to dwie nici, które biegną równolegle do siebie i tworzą praworęczna spirala
... Szerokość tej spirali wynosi około 2 nm, ale jej długość może sięgać setek tysięcy nanometrów. Watson i Crick zaproponowali model DNA, zgodnie z którym wszystkie zasady DNA znajdują się wewnątrz helisy, a szkielet cukrowo-fosforanowy znajduje się na zewnątrz. W ten sposób podstawy jednego łańcucha są jak najbliżej podstaw drugiego,
dlatego powstają między nimi wiązania wodorowe. Struktura helisy DNA jest taka, że tworzące ją łańcuchy polinukleotydowe można oddzielić dopiero po jej rozwinięciu.
Ze względu na maksymalne sąsiedztwo dwóch nici DNA, jego skład zawiera taką samą ilość zasad azotowych jednego typu (adenina i guanina) oraz zasad azotowych innego typu (tymina i cytozyna), czyli wzór obowiązuje: A + G = T + C... Wynika to z wielkości zasad azotowych, mianowicie długość struktur, które powstają w wyniku występowania wiązania wodorowego pomiędzy parami adenina-tymina i guanina-cytozyna, wynosi około 1,1 nm. Całkowite rozmiary tych par odpowiadają rozmiarom wewnętrznej części helisy DNA. Aby utworzyć spiralę para C-T byłby za mały i para A-G wręcz przeciwnie, jest za duży. Oznacza to, że zasada azotowa pierwszej nici DNA określa zasadę, która znajduje się w tym samym miejscu na drugiej nici DNA. Nazywano ścisłą korespondencję nukleotydów znajdujących się w cząsteczce DNA w sparowanych łańcuchach równoległych do siebie komplementarność (dodatkowość). Dokładna reprodukcja lub replikacja informacja genetyczna jest możliwa właśnie dzięki tej właściwości cząsteczki DNA.
W DNA informacja biologiczna jest zapisywana w taki sposób, że można ją dokładnie skopiować i przekazać komórkom potomnym. Zanim nastąpi w nim podział komórek replikacja (samopodwojenie ) DNA. Ponieważ każda nić zawiera sekwencję nukleotydów, która jest komplementarna do sekwencji łańcucha partnera, w rzeczywistości niosą one tę samą informację genetyczną. Jeśli oddzielisz nici i użyjesz każdej z nich jako szablonu (szablonu) do zbudowania drugiej nici, otrzymasz dwie nowe, identyczne nici DNA. Tak zachodzi duplikacja DNA w komórce.


